Deep learning systems must be highly integrated and have access to vast amounts of computational resources to function properly. Consequently, building massive data centers with hundreds of specialized hardware accelerators is becoming increasingly necessary for large-scale applications. The best course of action is to move away from central model inference and toward decentral model inference, in which a network of edge devices with loosely linked neural networks distributes the processing power of the model. Unfortunately, the robustness required for this paradigm change is absent from existing deep learning methods.
When it comes to pruning or changing network layers during deployment, artificial neural networks (ANNs) typically could be more resilient. Similarly, it is common for accuracy to suffer severely when interlayer execution orders are changed without additional training. However, these characteristics would be great to have, for instance, in the distributed settings mentioned above, when a model is run on several shared network nodes. In this configuration, overworked nodes or not working properly could be bypassed in favor of other available nodes. On top of that, it would be easy to implement models in practice by simply replacing absent or dysfunctional nodes with comparable ones rather than the same ones.
Adding these characteristics to models has always been a tough nut to crack. Most ANNs are structured and taught via backpropagation, meaning that each neuron can only adapt to its associated input and output neurons and the network’s overall desired output during training to function. In addition, it is commonly believed that deep learning requires a hierarchical arrangement of explanatory elements as a prerequisite, meaning that one must expect that successive layers will extract higher-level features. Hence, layers would have to change how they extract features based on their position in the network if the execution orders of the layers were to be switched. Most known network architectures cannot support network layers adjusting to a modified execution order in this fashion. Therefore, the network’s overall performance degrades once it has learned to perform its training task, a violation of the preceding prior. The greater adaptability of the newly found transformer design has been demonstrated.
Recent work unifies similar transformer-based language models, and all achieve moderate decrease or even performance improvement. When trained appropriately, transformers can be layer-pruned at test time. Researchers believe that transformers’ exceptional adaptability lies in self-attention modules’ ability to adjust their output according to the input. Consequently, it ought to be feasible to train a transformer network to adapt not only to changes in the input features determined by the overall network input but also to variations brought about by receiving input from different layers during testing.
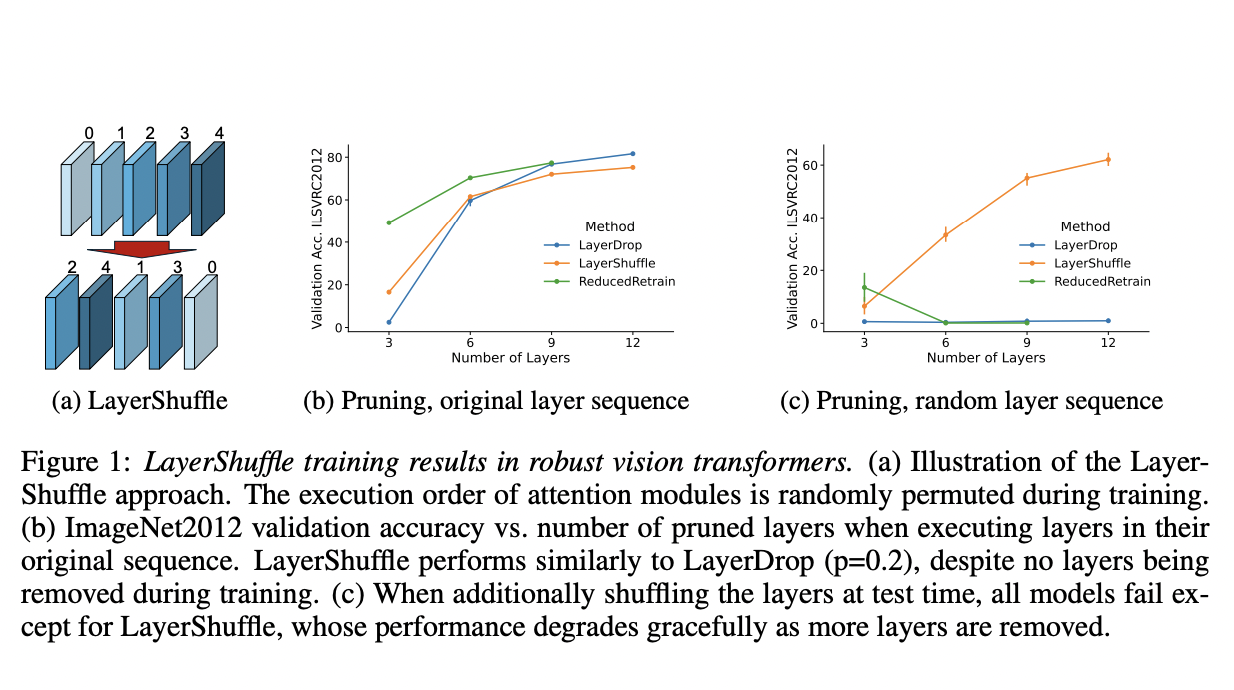
The LayerShuffle technique, developed by researchers from the University of Copenhagen and IT University of Copenhagen, presents a promising solution to enhance the resilience of vision transformers. It is particularly effective in scenarios where the execution of the layers is random, offering a beacon of hope for future applications. While it performs slightly less than LayerDrop for sequential execution, its potential for random execution is a significant step forward.
Given each given order of execution of layers, the team examined three methods for them:
- The first step is to rearrange the network layers while training randomly. This ensures that the layers are presented with distinct batches of data in a completely random order.
- Similarly to the previous method, they employ a layer-depth encoding that is influenced by learnt word embedding techniques to randomly rearrange the order of the layers. The goal is to determine if this extra information would lead to even better performance.
- Finally, they employ a little layer position prediction network for each layer to forecast, from the output, the layer’s present location in the network while randomly rearranging the order of the layers.
The researchers further go into the impact of pruning an increasing number of layers during test time to find out how neural networks trained with LayerShuffle would do when multiple devices in a (distributed) model go down. Using just 3,6 or 9 layers, they calculate its average validation accuracy across five models.
With their training methods, the team discovered that a vision transformer’s layers can adapt to any execution sequence during testing as long as a minor drop in performance is tolerable. There is a small performance gain when each layer is given its present location in the network in addition to the incoming data, demonstrating that each attention layer can already determine its role from incoming data alone. Their discovery that learned models can be layer-pruned during testing, leading to improved performance, instills confidence in the thoroughness of their research.
According to a latent space analysis, LayerShuffle-trained model layers modify their output based on their network position. The team also looked into the possibility of creating merged models from LayerShuffle-trained models. Surprisingly, the performance of these models was only marginally lower than their trained models. This contrasts with the baseline, where almost all merged models performed poorly.
Future research holds exciting potential for further understanding the typical results of multi-layer perceptron and multi-head attention layers. This study could reveal whether layers can learn to turn off their output for inputs they can’t handle, allowing a more appropriate layer downstream to handle the data after relaying it through the attention module’s leftover connections.
Additional insights could be obtained by looking at the model’s attention maps and including all layers’ intermediate latent vectors in a single two-dimensional embedding. These features may one day make LayerShuffle-trained models perfect for distributing the computational burden of model inference among several extremely loosely connected compute nodes. The researchers are also considering deploying and orchestrating their trained models onto a real set of edge devices and putting the inference process into action on a network of these devices. This could be achieved by integrating their approach with other frameworks that have been suggested to tackle this problem, which is an exciting area for future research.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post LayerShuffle: Robust Vision Transformers for Arbitrary Layer Execution Orders appeared first on MarkTechPost.