Pretrained large models have shown impressive abilities in many different fields. Recent research focuses on ensuring these models align with human values and avoid harmful behaviors. To achieve this, alignment methods are crucial, where two primary methods are supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF). RLHF is useful in generalizing the reward model to new prompt-response pairs. However, it faces the challenge of training a reward model that works well with unseen data. One common problem is “overoptimization” or “reward hacking”. Increasing the size of the reward model and the amount of training data can help solve this issue, but it is not practical in real-world situations.
This paper discusses two approaches in the related work. The first approach is Reward Modeling, where reward models are trained on human preference data to guide the RLHF process or prompt optimization. Recent research focuses on developing better reward models to improve the performance of large language models (LLMs) in RLHF. This includes enhancing reward modeling by improving the quality or quantity of preference data. The second approach is Mitigating Overoptimization in RLHF, where reward models often overfit and have trouble generalizing beyond the training data, leading to the issue of overoptimization. One can penalize overly confident model outputs using label smoothing or SFT regularization to reduce this problem.
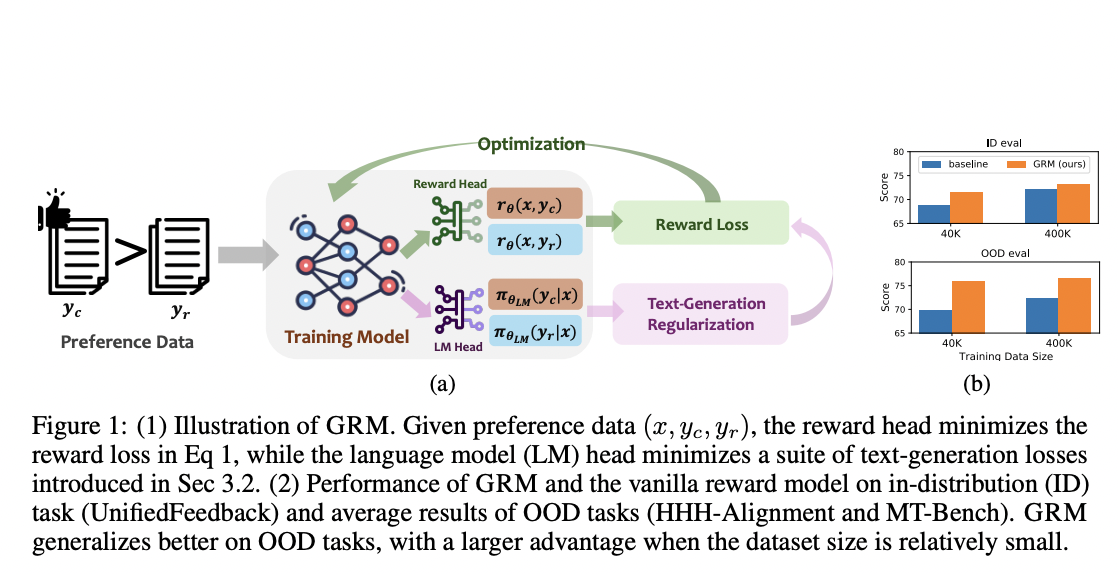
Researchers from HKUST, Georgia Institute of Technology, and the University of Illinois Urbana-Champaign have introduced the Generalizable Reward Model (GRM), which uses text-generation regularization on hidden states to improve the performance of reward models. Their study shows that all three types of text-generation regularization work well with GRM, with SFT regularization being the most effective and reliable solution. The results demonstrate that GRM greatly enhances the accuracy of reward models in various out-of-distribution (OOD) tasks. Moreover, it consistently boosts the performance of RLHF and helps in reducing the problem of overoptimization.
The Unified-Feedback dataset is used for training reward models, and it is one of the largest collections of pairwise feedback datasets. All reward models are trained on a subset of 400K and 40K instances from the Unified-Feedback dataset and evaluated on an 8K-instance hold-out eval set. Moreover, while evaluating model performance on OOD preference data, datasets like HHH-Alignment, MT-Bench Human Judgements, and RewardBench are used. The HHH-Alignment dataset evaluates language models on helpfulness, honesty, and harmlessness, while the MT-Bench dataset contains human preferences for model responses to MT-bench questions.
Here are the results after evaluating GRM:
- GRM greatly improves the generalization ability of reward models, leading to better performance on both (in-distribution) ID and OOD evaluation sets.
- All three types of text-generation regularization losses can enhance generalization, with SFT regularization being the most effective and consistent.
- It shows strong performance even with limited datasets, outperforming baselines with a huge margin.
- GRM efficiently reduces the overoptimization problem in BoN and PPO and is robust against label noise in the preference data.
In conclusion, researchers have proposed the Generalizable Reward Model (GRM), an efficient method, that aims to improve the generalizability and robustness of reward learning for LLMs. GRM uses regularization techniques on the hidden states of reward models, which significantly improves the generalization performance of reward models for unseen data. Moreover, the proposed approach effectively reduces the problem of overoptimization in RLHF. These results will support future research in creating stronger reward models, helping to align large models more efficiently and solutions with cost-effectiveness.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post Generalizable Reward Model (GRM): An Efficient AI Approach to Improve the Generalizability and Robustness of Reward Learning for LLMs appeared first on MarkTechPost.