
Adversarial attacks are attempts to trick a machine learning model into making a wrong prediction. They work by creating slightly modified versions of real-world data (like images) that a human wouldn’t notice as different but that cause the model to misclassify them. Neural networks are known to be vulnerable to adversarial attacks, raising concerns about the reliability and security of machine learning systems in critical applications like image classification. For instance, facial recognition systems used for security purposes could be fooled by adversarial examples, allowing unauthorized access.
Researchers from the Weizmann Institute of Science, Israel, and the Center for Data Science, New York University have introduced MALT (Mesoscopic Almost Linearity Targeting) to address the challenge of adversarial attacks on neural networks, which exploit vulnerabilities in machine learning models. The current state-of-the-art adversarial attack, AutoAttack, employs a strategy that selects target classes based on model confidence levels but is computationally intensive. AutoAttack’s approach limits the number of classes targeted due to computational constraints, potentially missing vulnerable classes, and failure to generate adversarial examples on certain inputs.
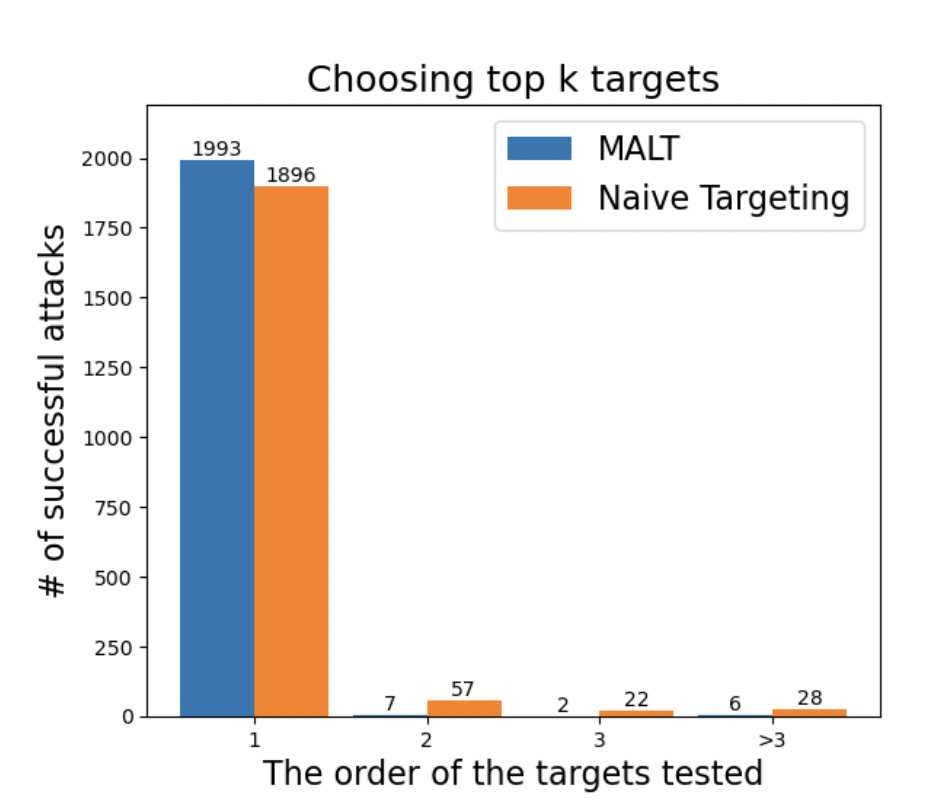
MALT is a novel adversarial targeting method inspired by the hypothesis that neural networks exhibit almost linear behavior at a mesoscopic scale. Unlike traditional methods that rely solely on model confidence, MALT reorders potential target classes based on normalized gradients, aiming to identify classes with minimal modifications required for misclassification.
MALT exploits the “mesoscopic almost linearity” principle to generate adversarial examples for machine learning models efficiently. This principle suggests that for small modifications to the input data, the model’s behavior can be approximated as linear. In simpler terms, imagine the model’s decision-making process as a landscape with hills and valleys. MALT focuses on modifying the data within a small region where this landscape can be treated as a flat plane. MALT utilizes gradient estimation techniques to understand how small changes in the input data will affect the model’s output. This helps identify which pixels or modify features in the image to achieve the desired misclassification. Additionally, MALT employs an iterative optimization process. It starts with an initial modification to the input data and then refines those changes based on the gradient information. This process continues until the model confidently classifies the data as the target class.
In conclusion, the study presents a significant advancement in adversarial attack techniques by introducing a more efficient and effective targeting strategy. By leveraging mesoscopic almost linearity, MALT concentrates on small, localized modifications to the data. This reduces the complexity of the optimization process compared to methods that explore a wider range of changes. MALT shows significant advantages over existing adversarial attack methods, particularly in terms of speed and effectiveness
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our 46k+ ML SubReddit, 26k+ AI Newsletter, Telegram Channel, and LinkedIn Group.
If You are interested in a promotional partnership (content/ad/newsletter), please fill out this form.
The post MALT (Mesoscopic Almost Linearity Targeting): A Novel Adversarial Targeting Method based on Medium-Scale Almost Linearity Assumptions appeared first on MarkTechPost.