
VLMs like LLaVA-Med have advanced significantly, offering multi-modal capabilities for biomedical image and data analysis, which could aid radiologists. However, these models face challenges, such as hallucinations and imprecision in responses, leading to potential misdiagnoses. With radiology departments experiencing increased workloads and radiologists facing burnout, the need for tools to mitigate these issues is pressing. VLMs can assist in interpreting medical imaging and provide natural language answers, but their generalization and user-friendliness issues hinder their clinical adoption. A specialized “Radiology Assistant” tool could address these needs by enhancing report writing and facilitating communication about imaging and diagnosis.
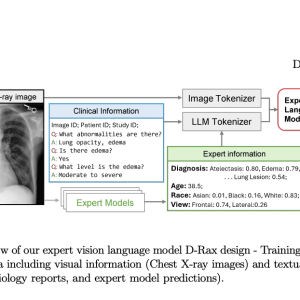
Researchers from the Sheikh Zayed Institute for Pediatric Surgical Innovation, George Washington University, and NVIDIA have developed D-Rax, a specialized tool for radiological assistance. D-Rax enhances the analysis of chest X-rays by integrating advanced AI with visual question-answering capabilities. It is designed to facilitate natural language interactions with medical images, improving radiologists’ ability to identify and diagnose conditions accurately. This model leverages expert AI predictions to train on a rich dataset, including MIMIC-CXR imaging data and diagnostic outcomes. D-Rax aims to streamline decision-making, reduce diagnostic errors, and support radiologists in their daily tasks.
The advent of VLMs has significantly advanced the development of multi-modal AI tools. Flamingo is an early example that integrates image and text processing through prompts and multi-line reasoning. Similarly, LLaVA combines visual and textual data using a multi-modal architecture inspired by CLIP, which links images to text. BioMedClip is a foundational VLM in biomedicine for tasks like image classification and visual question-answering. LLaVA-Med, a version of LLaVA adapted for biomedical applications, helps clinicians interact with medical images using conversational language. However, many of these models face challenges such as hallucinations and inaccuracies, highlighting the need for specialized tools in radiology.
The methods for this study involve utilizing and enhancing datasets to train a domain-specific VLM called D-Rax, designed for radiology. The baseline dataset comprises MIMIC-CXR images and Medical-Diff-VQA’s question-answer pairs derived from chest X-rays. Enhanced data include predictions from expert AI models for conditions like diseases, patient demographics, and X-ray views. D-Rax’s training employs a multimodal architecture with the Llama2 language model and a pre-trained CLIP visual encoder. The fine-tuning process integrates expert predictions and instruction-following data to improve the model’s precision and reduce hallucinations in interpreting radiologic images.
The results demonstrate that integrating expert-enhanced instruction significantly improves D-Rax’s performance on certain radiological questions. For abnormality and presence questions, both open and closed-ended, models trained with enhanced data show notable gains. However, the performance remains similar across basic and enhanced data for questions about location, level, and type. Qualitative evaluations highlight D-Rax’s ability to identify issues like pleural effusion and cardiomegaly correctly. The enhanced models also handle complex queries better than simple expert models, which are limited to straightforward questions. Extended testing on a larger dataset reinforces these findings, showing robustness in D-Rax’s capabilities.
D-Rax aims to enhance precision and reduce errors in responses from VLMs through a specialized training approach that integrates expert predictions. The model achieves more accurate and human-like outputs by embedding expert knowledge on disease, age, race, and view into CXR analysis instructions. Using datasets like MIMIC-CXR and Medical-Diff-VQA ensures domain-specific insights, reducing hallucinations and improving response accuracy for open and close-ended questions. This approach facilitates better diagnostic reasoning, improves clinician communication, offers clearer patient information, and has the potential to elevate the quality of clinical care significantly.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post D-Rax: Enhancing Radiologic Precision through Expert-Integrated Vision-Language Models appeared first on MarkTechPost.