Machine learning models for vision and language, have shown significant improvements recently, thanks to bigger model sizes and a huge amount of high-quality training data. Research shows that more training data improves models predictably, leading to scaling laws that explain the link between error rates and dataset size. These scaling laws help decide the balance between model size and data size, but they look at the dataset as a whole without considering individual training examples. This is a limitation because some data points are more valuable than others, especially in noisy datasets collected from the web. So, it is crucial to understand how each data point or source affects model training.
The related works in this paper discuss a method called Scaling Laws for deep learning, which have become popular in recent years. These laws help in several ways, including understanding the trade-offs between increasing training data and model size, predicting the performance of large models, and comparing how well different learning algorithms perform at smaller scales. The second approach focuses on how individual data points can improve the model’s performance. These methods usually score training examples based on their marginal contribution. They can identify mislabeled data, filter out high-quality data, upweight helpful examples, and select promising new data points for active learning.
Researchers from Stanford University have introduced a new approach by investigating scaling behavior for the value of individual data points. They found that the contribution of a data point to a model’s performance decreases predictably as the dataset grows larger, following a log-linear pattern. However, this decrease varies among data points, meaning that some points are more useful in smaller datasets, while others become more valuable in larger datasets. Moreover, a maximum likelihood estimator and an amortized estimator were introduced to efficiently learn these individual patterns from a small number of noisy observations for each data point.
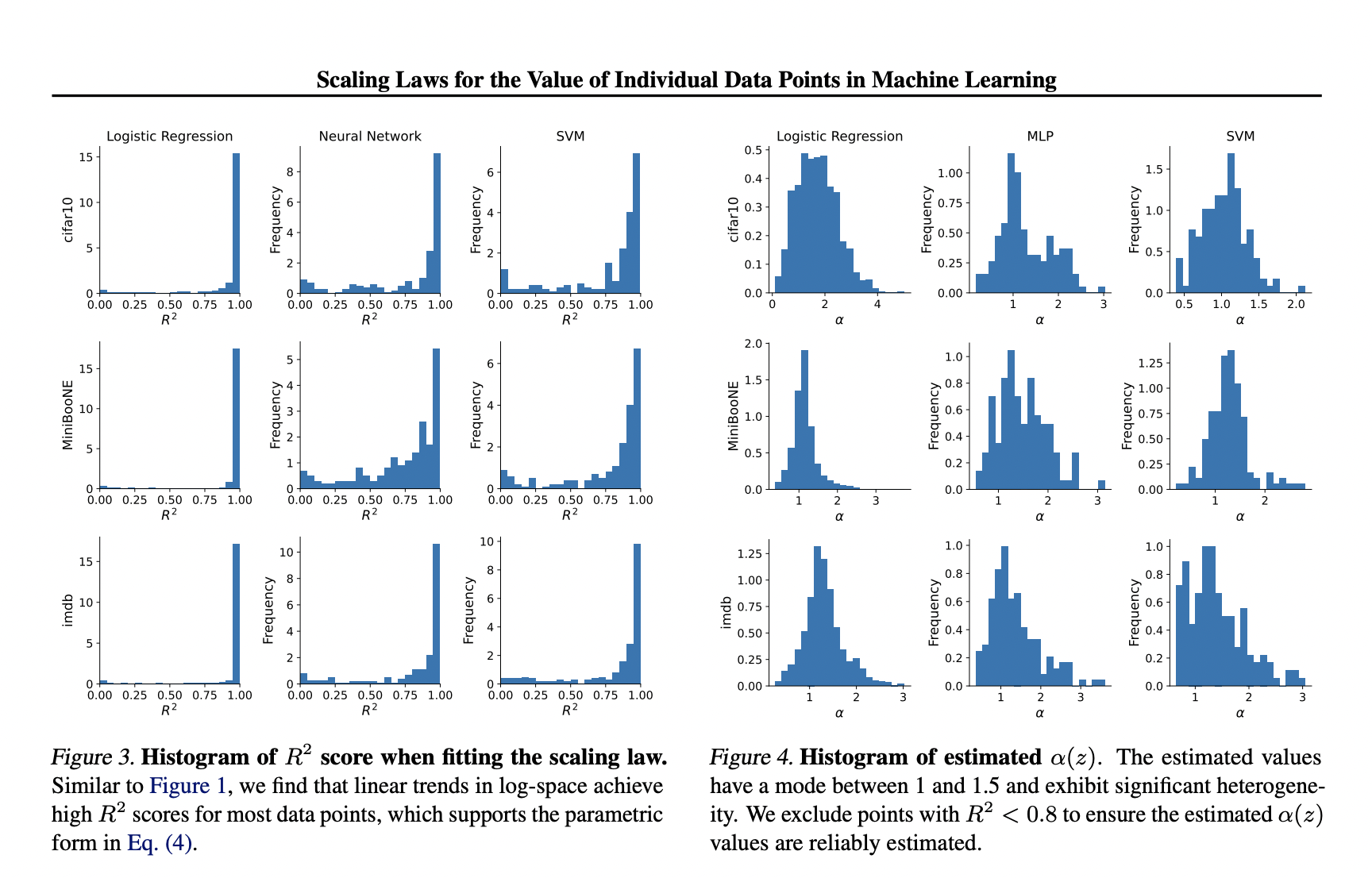
Experiments are carried out to provide evidence for the parametric scaling law, focusing on three types of models: logistic regression, SVMs, and MLPs (specifically, two-layer ReLU networks). These models are tested on three datasets: MiniBooNE, CIFAR-10, and IMDB movie reviews. Pre-trained embeddings like frozen ResNet-50 and BERT, are used to speed up training and prevent underfitting for CIFAR-10 and IMDB, respectively. The performance of each model is measured using cross-entropy loss on a test dataset of 1000 samples. For logistic regression, 1000 data points and 1000 samples per k value are used. For SVMs and MLPs, due to the higher variance in marginal contributions, 200 data points and 5000 samples per dataset size k are used.
The proposed methods are tested by predicting how accurate the marginal contributions are at each dataset size. For instance, with the IMDB dataset and logistic regression, expectations can accurately be predicted for dataset sizes ranging from k = 100 to k = 1000. To systematically evaluate this, the accuracy of the scaling law predictions is shown across different dataset sizes for both versions of a likelihood-based estimator using different samples. A more detailed version of these results shows the reduction of the R2 score when predictions are extended beyond k = 2500, while the correlation and rank correlation with the true expectations stays high.
In conclusion, researchers from Stanford University have developed a new method by examining how the value of individual data points changes with scale. They found evidence for a simple pattern that works across different datasets and model types. Experiments confirmed this scaling law by showing a clear log-linear trend and testing how well it predicts contributions at different dataset sizes. The scaling law can be used to predict behavior for larger datasets than those initially tested. However, measuring this behavior for an entire training dataset is expensive, so researchers developed ways to measure the scaling parameters using a small number of noisy observations per data point.
high-quality data in AI research.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post How AI Scales with Data Size? This Paper from Stanford Introduces a New Class of Individualized Data Scaling Laws for Machine Learning appeared first on MarkTechPost.