
Function-calling agent models, a significant advancement within large language models (LLMs), face the challenge of requiring high-quality, diverse, and verifiable datasets. These models interpret natural language instructions to execute API calls, which are critical for real-time interactions with various digital services. However, existing datasets often lack comprehensive verification and diversity, leading to inaccuracies and inefficiencies. Overcoming these challenges is crucial for the reliable deployment of function-calling agents in real-world applications, such as retrieving stock market data or managing social media interactions.
Current methods for training function-calling agents rely on static datasets that do not undergo thorough verification. This often results in datasets that are inadequate when models encounter new or unseen APIs, severely limiting their adaptability and performance. For example, a model trained primarily on restaurant booking APIs may struggle with tasks like stock market data retrieval due to a lack of relevant training data, highlighting the need for more robust datasets.
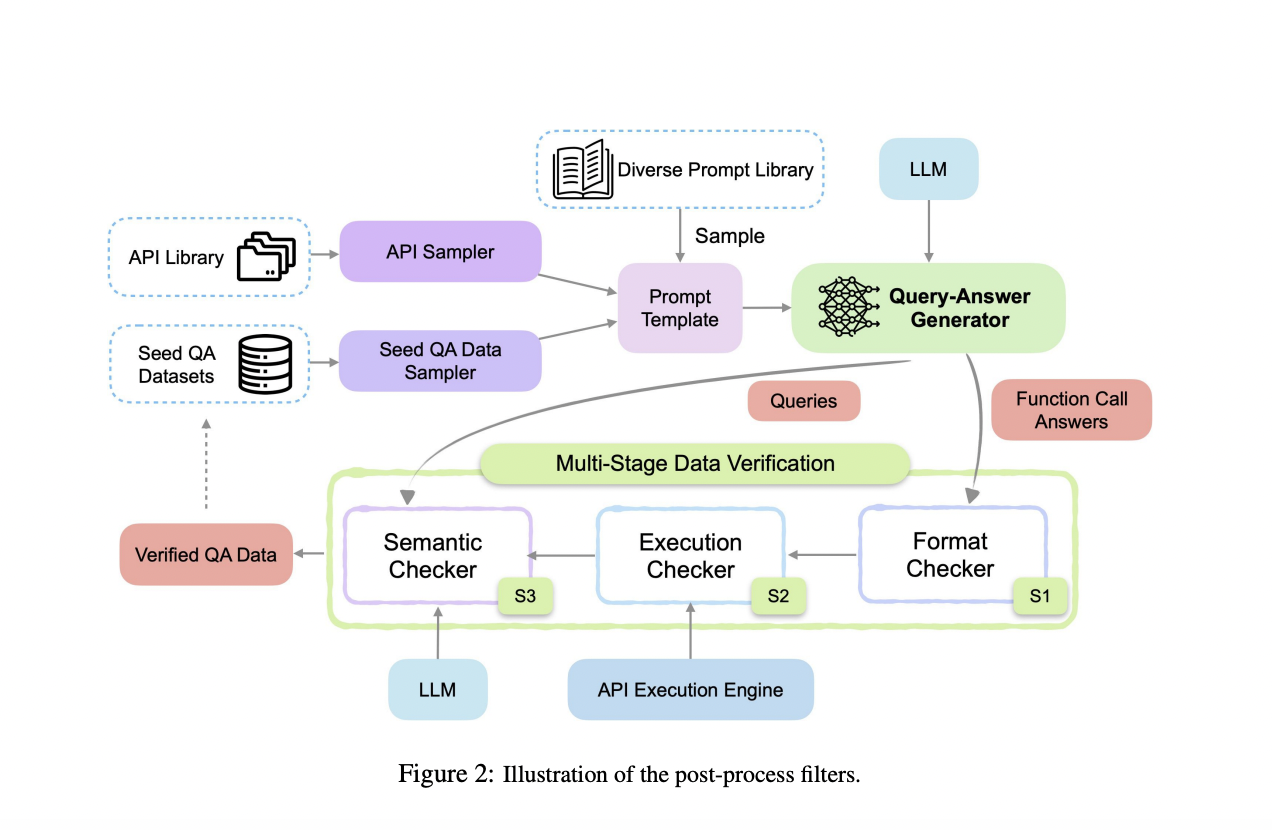
Researchers from Salesforce AI Research propose APIGen, an automated pipeline designed to generate diverse and verifiable function-calling datasets. APIGen addresses the limitations of existing methods by incorporating a multi-stage verification process, ensuring data reliability and correctness. This innovative approach involves three hierarchical stages: format checking, actual function executions, and semantic verification. By rigorously verifying each data point, APIGen produces high-quality datasets that significantly enhance the training and performance of function-calling models.
APIGen’s data generation process starts with sampling APIs and example query-answer pairs from a library, formatting them into a standardized JSON format. The pipeline then employs a multi-stage verification process. Stage 1 involves a format checker that ensures correct JSON structure. Stage 2 executes the function calls to verify their operational correctness. Stage 3 uses a semantic checker to ensure alignment between the function calls, execution results, and query objectives. This process results in a comprehensive dataset of 60,000 high-quality entries, covering 3,673 APIs across 21 categories, available on Huggingface.
APIGen’s datasets significantly improved model performance, achieving state-of-the-art results on the Berkeley Function-Calling Benchmark. Notably, models trained using these datasets outperformed multiple GPT-4 models, demonstrating considerable enhancements in accuracy and efficiency. For instance, a model with only 7B parameters achieved an accuracy of 87.5%, surpassing previous state-of-the-art models by a significant margin. These results underscore the robustness and reliability of APIGen-generated datasets in enhancing the capabilities of function-calling agents.
In conclusion, the researchers present APIGen, a novel framework for generating high-quality and diverse function-calling datasets, addressing a critical challenge in AI research. The proposed multi-stage verification process ensures data reliability and correctness, significantly enhancing model performance. The APIGen-generated datasets enable even small models to achieve competitive results, advancing the field of function-calling agents. This approach opens new possibilities for developing efficient and powerful language models, highlighting the importance of high-quality data in AI research.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post Salesforce AI Research Unveils APIGen: Automated Pipeline for Generating Verifiable and Diverse Function-Calling Datasets appeared first on MarkTechPost.