
At the moment, many subfields of computer vision are dominated by large-scale vision models. Newly developed state-of-the-art models for tasks such as semantic segmentation, object detection, and image classification exceed today’s hardware capabilities. These models have stunning performance, but the hefty computational costs mean they are rarely employed in real-world applications.
To tackle this issue, the Google Research Team focuses on the following task: giving an application and a huge model that works great on it. The study aims to reduce the model to a smaller, more efficient architecture while maintaining speed. Model pruning and knowledge distillation are popular paradigms that are objective for this job. By removing unnecessary components, model pruning makes the previously huge model smaller. However, the team focused on the knowledge distillation method. The basic principle of knowledge distillation is to reduce a large and inefficient instructor model—or set of models—to a smaller and more efficient student model. The student’s predictions, also known as internal activations, are pushed to align with the teacher’s, which enables a change in the model family as part of compression. Following the initial distillation arrangement to a tee, they see it is remarkably effective. They find that for good generalizability, it’s important to have the functions compatible with many support points. Support points outside the original image manifold can be generated using an aggressive mixup (a data augmentation technique that combines two images to create a new one). This technique helps the student model learn from a wider range of data, improving its generalizability.
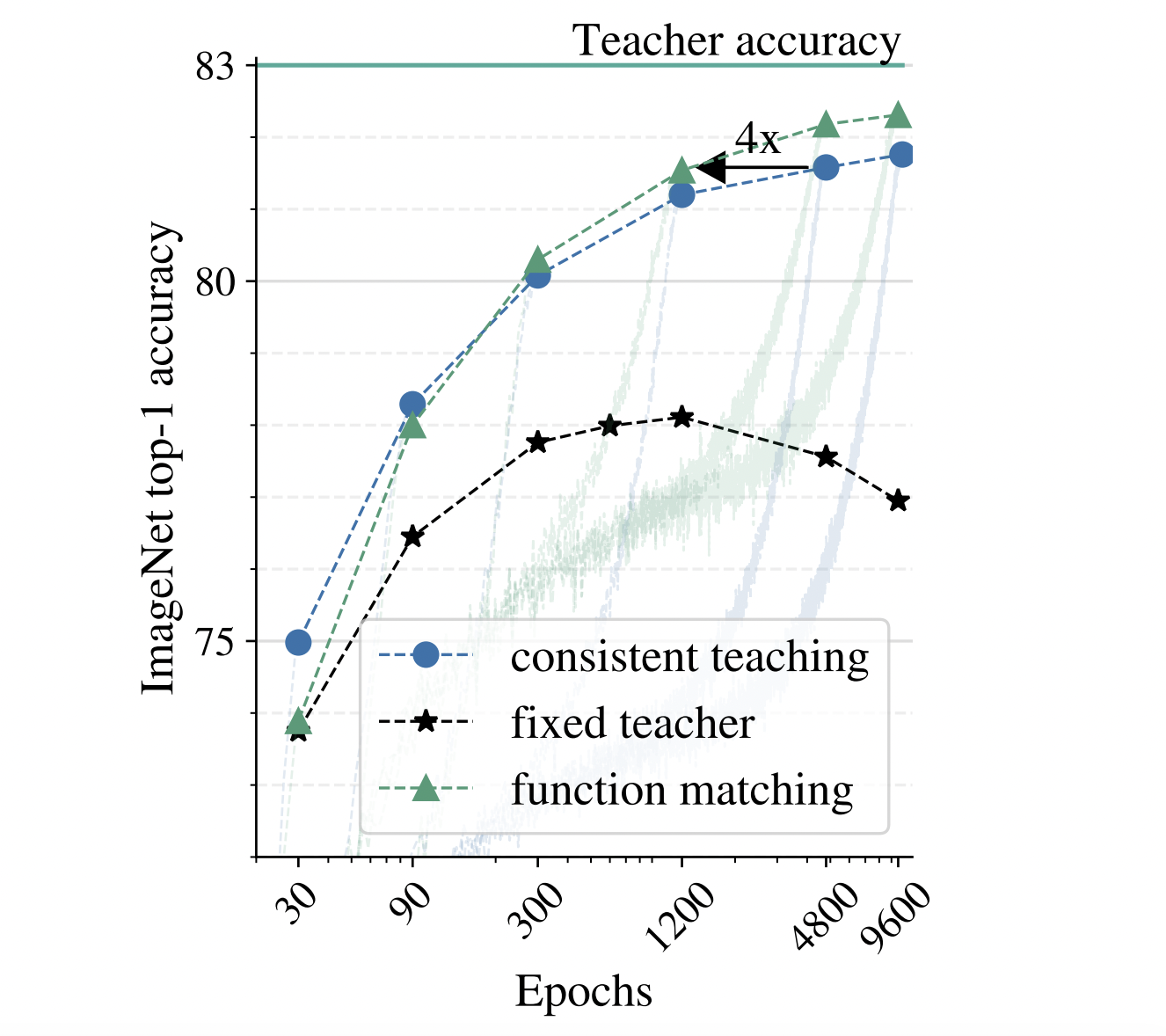
The researchers experimentally show that aggressive augmentations, long training periods, and consistent picture views are crucial to making model compression via knowledge distillation work well in practice. These findings may seem straightforward, but there are several potential roadblocks that researchers (and practitioners) face when trying to implement the design decisions proposed. To start with, particularly for extremely large teachers, it might be tempting to precompute the operations for an image offline once to save computation. This method of having a different instructor. Additionally, they show that writers often suggest distinct or opposing design choices when using knowledge distillation in situations other than model compression. Compared to supervised training, knowledge distillation has an abnormally high number of epochs needed to achieve optimal performance. Lastly, decisions that appear less than ideal during training sessions of a normal duration often prove to be the most optimal on lengthy runs, and the opposite is also true.
They primarily focus on compressing the big BiT-ResNet-152×2 in their empirical investigation. This network was trained on the ImageNet-21k dataset and fine-tuned to align with the relevant datasets. Without sacrificing accuracy, they reduce it to a typical ResNet-50 architecture by swapping out batch normalization for group normalization and testing it on various small and medium-sized datasets. Due to its high deployment cost (about ten times more computing power than the baseline ResNet-50), efficient compression of this model is crucial. They utilize a short version of BiT-ResNet-50 called ResNet-50 for the student’s architecture. The results on the ImageNet dataset are equally impressive: using a total of 9600 distillation epochs (iterations of the distillation process), the solution achieved an impressive ResNet-50 SOTA of 82.8% on ImageNet. This model outperforms the best ResNet-50 in the literature by 2.2% and 4.4% compared to the ResNet-50 model, the latter of which employs a more intricate configuration.
Overall, the study demonstrates the effectiveness and robustness of the proposed distillation formula. By successfully compressing and switching model families, such as from the BiT-ResNet design to the MobileNet architecture, the team showcases the potential of their solutions. This transition from extremely large models to the more realistic ResNet-50 architecture yields robust empirical results, instilling optimism in the audience about the future of model compression in computer vision.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post Google Researchers Reveal Practical Insights into Knowledge Distillation for Model Compression appeared first on MarkTechPost.