While large language models (LLMs) have been proven to be pivotal in natural language processing (NLP), these models require immense computational resources and time for training, posing a significant and one of the most crucial challenges for researchers and developers. This enormous computational cost and memory requirement can be a barrier to both research and practical applications of LLMs. Efficiently training these massive models without compromising their performance is essential to make LLM technology more accessible and scalable.
Several methods have been developed to tackle this issue. QLoRA, for instance, combines low-rank adaptation with quantization to reduce memory usage during training, allowing fine-tuning large models on less powerful hardware. Another approach, LASER, uses signal-to-noise ratio (SNR) to apply low-rank approximations to specific layers, improving model performance on certain tasks without excessive computational demands.
Researchers from Cognitive Computations, Arcee.AI, and Vago Solutions introduced a novel method called Spectrum to enhance the efficiency of LLM training. Spectrum selectively targets layer modules based on their SNR, freezing less informative modules and focusing computational resources on the most impactful ones. This targeted approach significantly reduces GPU memory usage while maintaining high performance. By utilizing this method, researchers can direct computational power where it is most needed, ensuring optimal use of resources and improving overall training efficiency.
Spectrum’s methodology is grounded in Random Matrix Theory and utilizes the Marchenko-Pastur distribution to identify the most informative layers in a model. Spectrum optimizes the training process by focusing on layers with high SNR, reducing the need for extensive computational resources. This method contrasts with traditional approaches that uniformly train all layers, often leading to inefficient use of resources. The Marchenko-Pastur distribution helps distinguish signals from noise in the weight matrices, enabling precise targeting of layers that contribute most to the model’s learning capability.
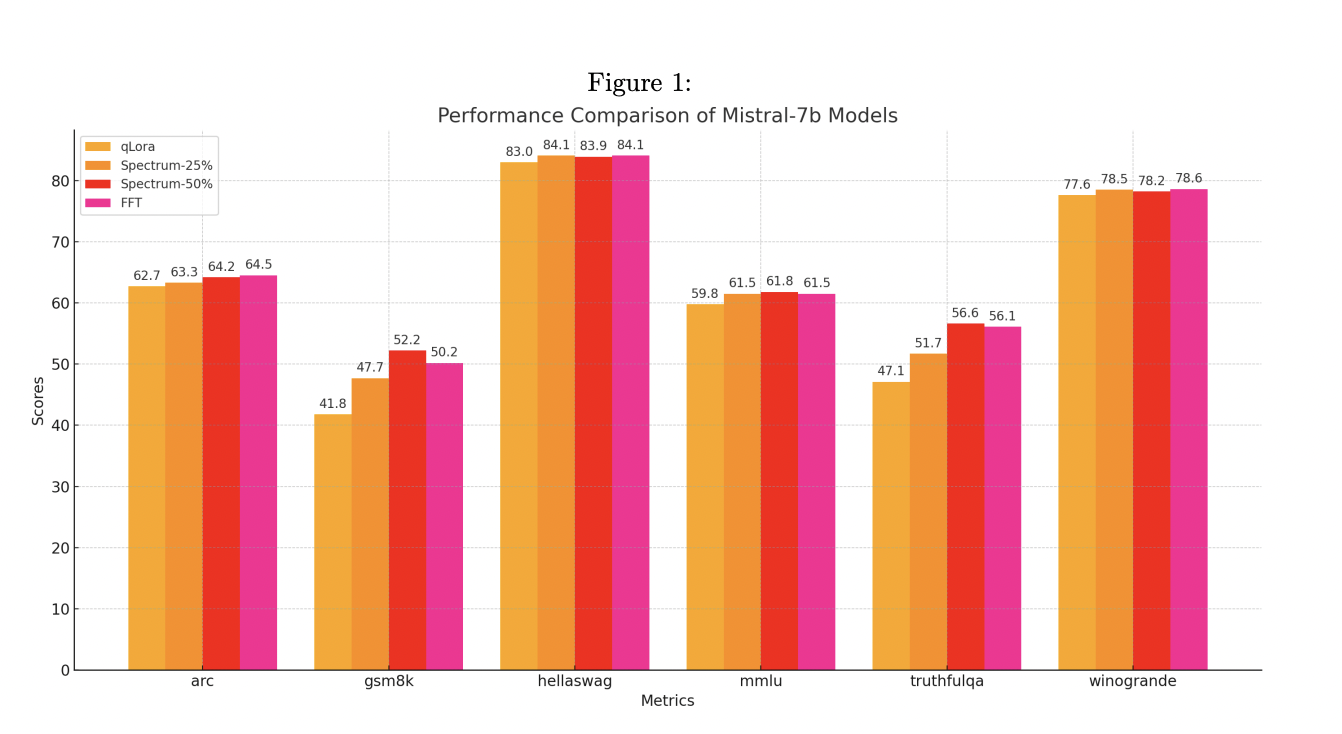
The researchers conducted experiments using five Llama 3 8B models and evaluated them on various benchmarks, including Arc-Easy, GSM8K, HellaSwag, and MMLU. The models trained with Spectrum showed competitive performance across these benchmarks, often matching or exceeding the results of fully fine-tuned models. Furthermore, Spectrum’s efficiency in distributed training environments using DeepSpeed ZeRO-3 was particularly noteworthy, achieving significant memory savings per GPU, which is crucial for large-scale model training. Spectrum consistently matched or outperformed these methods, demonstrating its effectiveness in training speed and memory efficiency.
In one evaluation, Spectrum-25, which targets the top 25% of layers, reduced memory usage by 23.05% and training time by 36.78% compared to full fine-tuning. The combination of Spectrum and QLoRA further enhanced these results, showing a 31.99% reduction in peak memory usage per GPU and the shortest training time of 54 minutes and 55 seconds. Spectrum-50, targeting the top 50% of layers, achieved a 17.72% reduction in memory usage and a 1 hour and 27 minutes training time. QLoRA showed better memory efficiency in single GPU settings, but Spectrum still provided substantial improvements over traditional fine-tuning methods. By updating only the most informative parameters, Spectrum maintains model quality while significantly reducing the computational load. This approach speeds up the training process and makes it feasible to train large models on less powerful hardware.
Spectrum’s efficiency was particularly evident in distributed training environments using DeepSpeed ZeRO-3. The method achieved significant memory savings per GPU, making it ideal for large-scale model training. In single GPU settings, while QLoRA showed better memory efficiency, Spectrum still provided substantial improvements over traditional fine-tuning methods. The combination of Spectrum with QLoRA also proved to be highly effective, demonstrating even greater reductions in VRAM usage and training time, thus highlighting the method’s versatility and efficiency
In conclusion, Spectrum offers a groundbreaking approach to train large language models efficiently. By selectively focusing on the most informative layers, Spectrum reduces computational demands and accelerates the training process without compromising model performance. This innovation holds great potential for democratizing LLM research and enabling broader applications in various fields. The research teams from Cognitive Computations, Arcee.AI, and Vago Solutions have contributed to the field, paving the way for more efficient and accessible LLM training methods.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post Spectrum: An AI Method that Accelerates LLM Training by Selectively Targeting Layer Modules based on their Signal-to-Noise Ratio (SNR) appeared first on MarkTechPost.