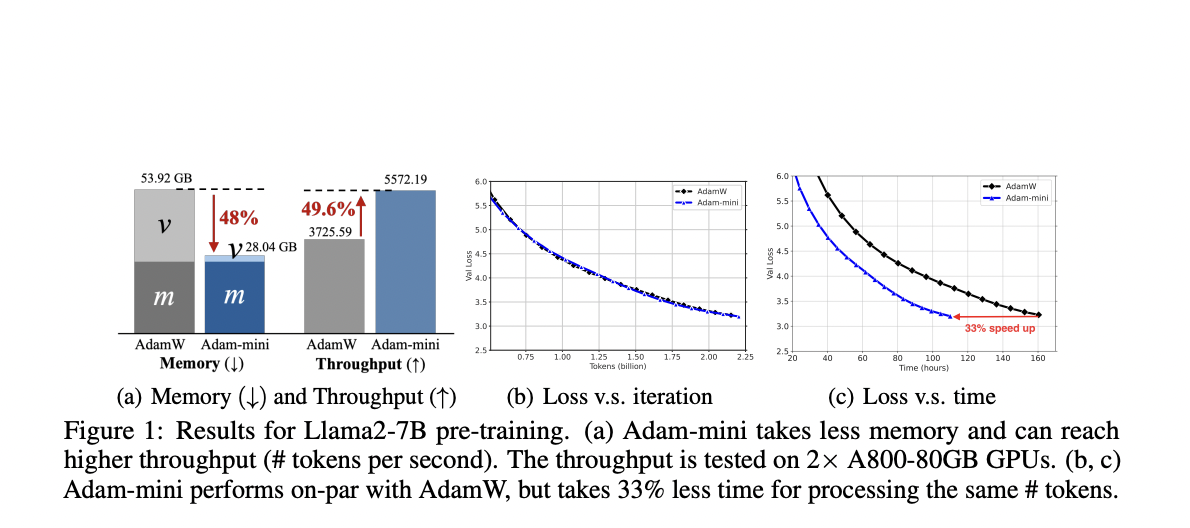
The field of research focuses on optimizing algorithms for training large language models (LLMs), which are essential for understanding and generating human language. These models are critical for various applications, including natural language processing and artificial intelligence. Training LLMs requires significant computational resources and memory, making optimizing these processes a high-priority area for researchers.
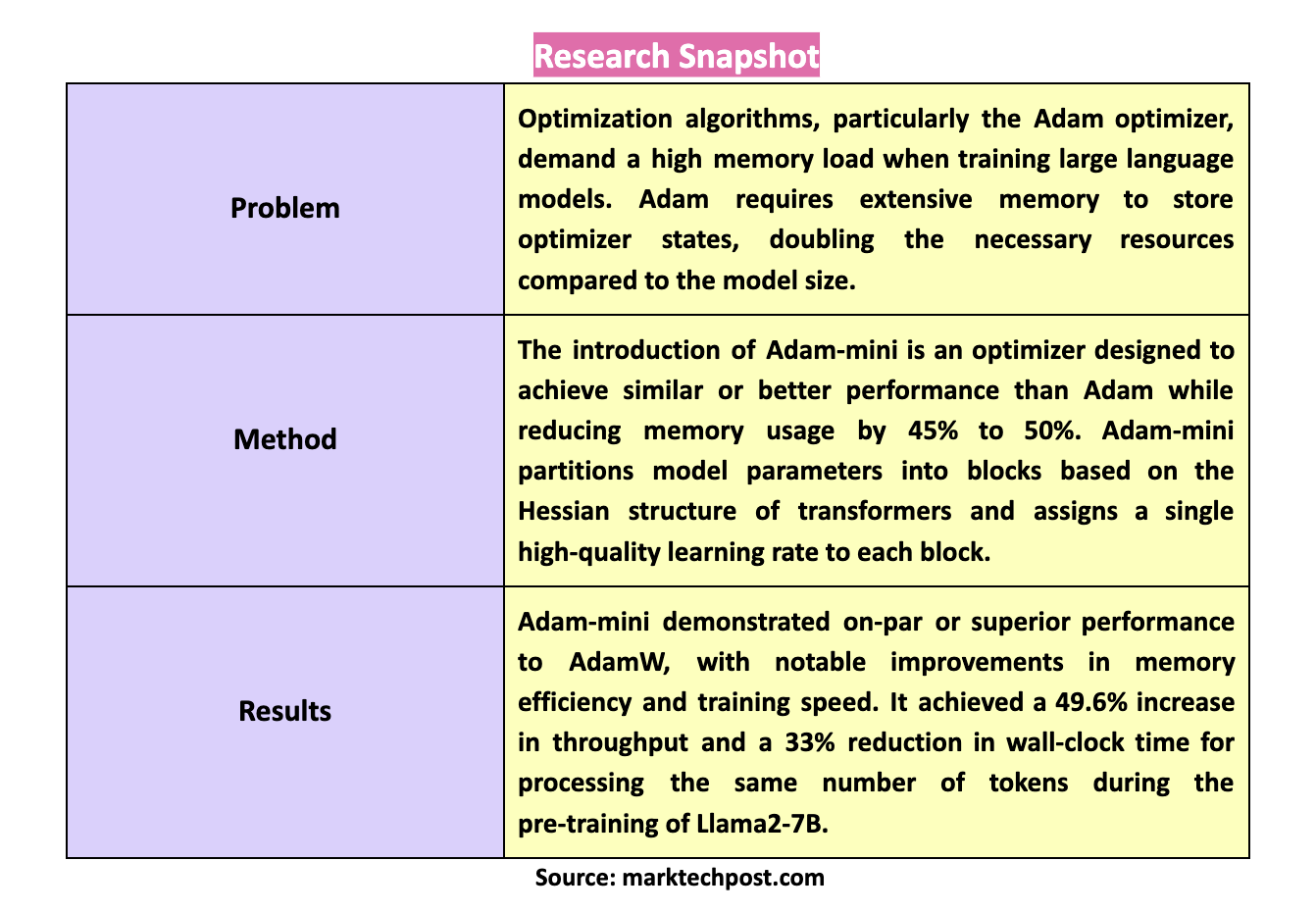
The primary problem addressed by this paper is the high memory demand of optimization algorithms used in training large language models. Specifically, the Adam optimizer, a standard in the field due to its superior performance, requires substantial memory to store optimizer states such as first-order and second-order momentum values. This memory demand doubles the necessary resources compared to the model size, creating a significant burden. As a result, training large models becomes expensive and less accessible to researchers with limited resources. Alternative methods like Adafactor attempt to reduce memory usage but often compromise performance, highlighting the need for more efficient solutions.
The Adam optimizer is widely used for training LLMs because of its ability to handle various model sizes and tasks effectively. However, Adam’s requirement for extensive memory to store its optimizer states, particularly the first-order and second-order momentums, poses a considerable challenge. For instance, training a 7 billion parameter model with Adam requires about 56 GB per card for these states alone, totaling 86 GB when gradients are included. This makes training prohibitively expensive, even with advanced graphical cards like the A100-80GB. Additionally, CPU-offloading and sharding are employed to manage this high memory requirement, increasing latency and slowing down the training process.
Researchers from The Chinese University of Hong Kong, Shenzhen, Shenzhen Research Institute of Big Data, Duke University, and Stanford University introduced Adam-mini, an optimizer designed to achieve similar or better performance than Adam while reducing memory usage by 45% to 50%. Adam-mini accomplishes this by partitioning model parameters into blocks based on the Hessian structure of transformers. Each block is then assigned a single high-quality learning rate, significantly reducing the number of learning rates from billions to a manageable number. This approach allows Adam-mini to maintain or even improve performance with a fraction of the memory required by Adam.
Adam-mini works by leveraging the near-block diagonal structure of transformers’ Hessians, partitioning parameters into blocks such as Query, Key, Value, and MLP layers. For each block, a single effective learning rate is calculated using the average of Adam’s second-order momentum values in that block. This method reduces the memory footprint and simplifies the learning rate assignment process. For example, during the pre-training of Llama2-7B on two A800-80GB GPUs, Adam-mini achieved a throughput of 5572.19 tokens per second, compared to 3725.59 tokens per second with AdamW, representing a 49.6% increase. This efficiency results in a 33% reduction in wall-clock time for processing the same number of tokens.
The researchers validated Adam-mini’s performance across various language models ranging from 125 million to 7 billion parameters, including pre-training, supervised fine-tuning (SFT), and reinforcement learning from human feedback (RLHF). The optimizer demonstrated on-par or superior performance to AdamW, with notable improvements in memory efficiency and training speed. For instance, in supervised fine-tuning and reinforcement learning tasks, Adam-mini consistently outperformed AdamW, achieving higher evaluation scores and faster convergence.
In conclusion, the Adam-mini optimizer addresses the significant memory inefficiencies of traditional optimization methods like Adam by introducing a novel partitioning strategy based on the Hessian structure of models. This innovative approach results in substantial memory savings and improved training efficiency, making it a valuable tool for researchers working with large-scale language models. By reducing the memory footprint by up to 50% and increasing throughput by nearly 50%, Adam-mini not only enhances the feasibility of training large models but also encourages broader participation from researchers with limited GPU resources.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 45k+ ML SubReddit
The post Adam-mini: A Memory-Efficient Optimizer Revolutionizing Large Language Model Training with Reduced Memory Usage and Enhanced Performance appeared first on MarkTechPost.