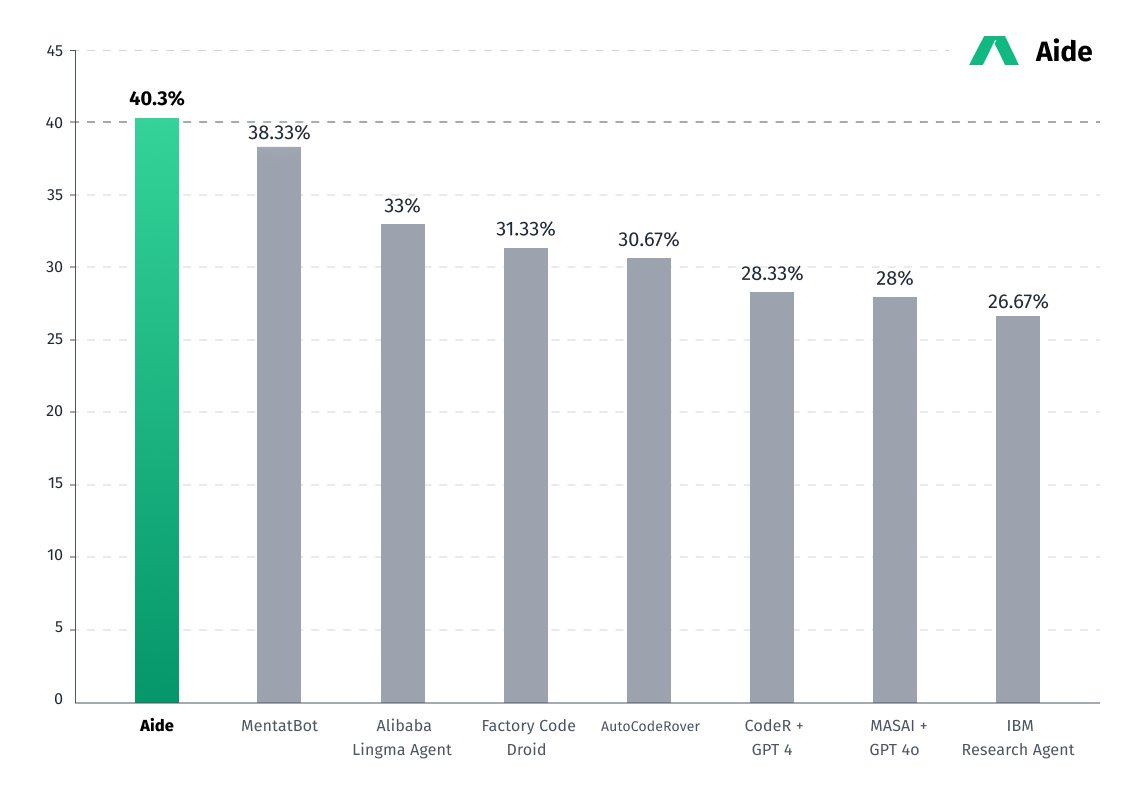
Recent developments in the field of software engineering have raised the bar for productivity and teamwork. A team of researchers from Codestory has recently developed a multi-agent coding framework called Aide that achieved a remarkable 40.3% accepted solutions on the SWE-Bench-Lite benchmark, establishing a new state-of-the-art. With its smooth integration into development environments and increased productivity, this framework promises to completely transform the way developers work with code.
The idea of numerous agents, each in charge of a particular code symbol like a class, function, enum, or type, lies at the core of this architecture. This atomic level of granularity enables natural language communication amongst bots, enabling each to concentrate on a particular unit of task. The Language Server Protocol (LSP) facilitates the agents’ communication using protocols that guarantee accurate and effective information transmission.
Practically, this means that up to 30 agents can be active at once during a single run, collaborating to make decisions and sharing information. The framework’s capabilities have been demonstrated by its remarkable performance on the SWE-Bench-Lite benchmark. ClaudeSonnet3.5 and GPT-4o were utilized in the creation of an editor environment for the agents through the use of Pyright and Jedi. GPT-4o was exceptional at code editing, while Sonnet3.5—which is renowned for its robust agentic behaviors—was helpful in organizing and navigating the codebase.
The agentic aspect of Sonnet 3.5 was very significant. It was the first paradigm to propose separating functions instead of making already complex ones more complex, exhibiting a sophisticated knowledge of maintainability and code structure. This behavior, along with GPT-4o’s excellent code editing abilities, made the framework perform noticeably better than earlier versions.
The SWE-Bench-Lite benchmark was selected because it can replicate real-world coding difficulties, giving agents a reliable testing environment. The benchmark configuration comprised a mock editor harness with Pyright for diagnostics and Jinja for LSP features, enabling agents to obtain information and perform tests quickly without taxing system resources.
The benchmarking process yielded important lessons, one of which was the significance of agent collaboration. Together, agents who were each in charge of a different code symbol were able to do tasks quickly and often corrected unrelated problems like lint errors or TODOs as they went. This cooperative method not only enhanced the quality of the code but also demonstrated the ability of agentic systems to manage complicated coding jobs on their own.
The team has shared that there are still a few obstacles to overcome before fully including this multi-agent framework in development environments. Research is currently underway to ensure smooth communication between human developers and agents, handle concurrent code modifications, and preserve code stability. Furthermore, the team is studying to optimize the framework’s performance better, specifically with inference speeds and intelligence costs.
The team’s ultimate objective is to increase the capabilities of human developers rather than to replace them. The goal is to improve software development process accuracy and efficiency by supplying a swarm of specialized agents, freeing up developers to work on more complex problems while the agents take care of more detailed duties.
The post Transforming Software Development with Multi-Agent Collaboration: CodeStory’s Aide Framework Sets State-of-the-Art on SWE-Bench-Lite with 40.3% Accepted Solutions appeared first on MarkTechPost.