Hugging Face has announced the release of the Open LLM Leaderboard v2, a significant upgrade designed to address the challenges and limitations of its predecessor. The new leaderboard introduces more rigorous benchmarks, refined evaluation methods, and a fairer scoring system, promising to reinvigorate the competitive landscape for language models.
Addressing Benchmark Saturation
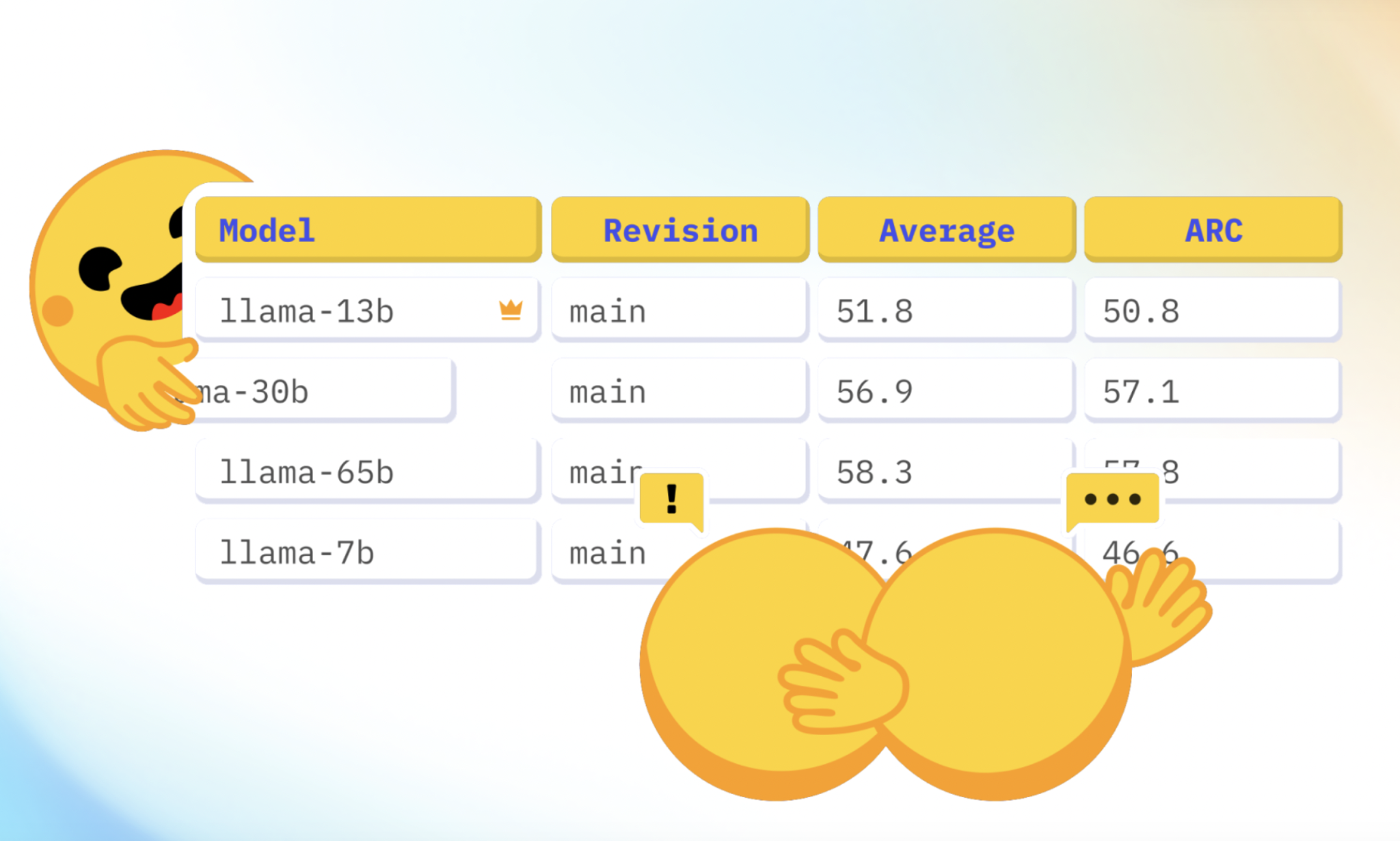
Over the past year, the original Open LLM Leaderboard became a pivotal resource in the machine learning community, attracting over 2 million unique visitors and engaging 300,000 active monthly users. Despite its success, the escalating performance of models led to benchmark saturation. Models began to reach baseline human performance on benchmarks like HellaSwag, MMLU, and ARC, reducing their effectiveness in distinguishing model capabilities. Additionally, some models exhibited signs of contamination, having been trained on data similar to the benchmarks, which compromised the integrity of their scores.
Introduction of New Benchmarks
To counter these issues, the Open LLM Leaderboard v2 introduces six new benchmarks that cover a range of model capabilities:
- MMLU-Pro: An enhanced version of the MMLU dataset, featuring ten-choice questions instead of four, requiring more reasoning and expert review to reduce noise.
- GPQA (Google-Proof Q&A Benchmark): A highly challenging knowledge dataset designed by domain experts to ensure difficulty and factuality, with gating mechanisms to prevent contamination.
- MuSR (Multistep Soft Reasoning): A dataset of algorithmically generated complex problems, including murder mysteries and team allocation optimizations, to test reasoning and long-range context parsing.
- MATH (Mathematics Aptitude Test of Heuristics, Level 5 subset): High-school level competition problems formatted for rigorous evaluation, focusing on the hardest questions.
- IFEval (Instruction Following Evaluation): Tests models’ ability to follow explicit instructions, using rigorous metrics for evaluation.
- BBH (Big Bench Hard): A subset of 23 challenging tasks from the BigBench dataset covering multistep arithmetic, algorithmic reasoning, and language understanding.
Fairer Rankings with Normalized Scoring
A notable change in the new leaderboard is the adoption of normalized scores for ranking models. Previously, raw scores were summed, which could misrepresent performance due to varying benchmark difficulties. Now, scores are normalized between a random baseline (0 points) and the maximal possible score (100 points). This approach ensures a fairer comparison across different benchmarks, preventing any single benchmark from disproportionately influencing the final ranking.
For example, in a benchmark with two choices per question, a random baseline would score 50 points. This raw score would be normalized to 0, aligning scores between benchmarks and providing a clearer picture of model performance.
Enhanced Reproducibility and Interface
Hugging Face has updated the evaluation suite in collaboration with EleutherAI to improve reproducibility. The updates include support for delta weights (LoRA fine-tuning/adaptation), a new logging system compatible with the leaderboard, and using chat templates for evaluation. Additionally, manual checks were conducted on all implementations to ensure consistency and accuracy. The interface has also been significantly enhanced. Thanks to the Gradio team, notably Freddy Boulton, the new Leaderboard component loads data on the client side, making searches and column selections instantaneous. This improvement provides users with a faster and more seamless experience.
Prioritizing Community-Relevant Models
The new leaderboard introduces a “maintainer’s choice” category highlighting high-quality models from various sources, including major companies, startups, collectives, and individual contributors. This curated list aims to include state-of-the-art LLMs and prioritize evaluations of the most useful models for the community.
Voting on Model Relevance
A voting system has been implemented to manage the high volume of model submissions. Community members can vote for their preferred models, and those with the most votes will be prioritized for evaluation. This system ensures that the most anticipated models are evaluated first, reflecting the community’s interests.
In conclusion, the Open LLM Leaderboard v2 by Hugging Face represents a major milestone in evaluating language models. With its more challenging benchmarks, fairer scoring system, and improved reproducibility, it aims to push the boundaries of model development and provide more reliable insights into model capabilities. The Hugging Face team is optimistic about the future, expecting continued innovation and improvement as more models are evaluated on this new, more rigorous leaderboard.
Check out the Leaderboard and Details. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 45k+ ML SubReddit
The post Hugging Face Releases Open LLM Leaderboard 2: A Major Upgrade Featuring Tougher Benchmarks, Fairer Scoring, and Enhanced Community Collaboration for Evaluating Language Models appeared first on MarkTechPost.