Large language models (LLMs) have significantly advanced the field of natural language processing (NLP). These models, renowned for their ability to generate and understand human language, are applied in various domains such as chatbots, translation services, and content creation. Continuous development in this field aims to enhance the efficiency and effectiveness of these models, making them more responsive and accurate for real-time applications.
A major challenge LLMs face is the substantial computational cost and time required for inference. As these models increase, generating each token during autoregressive tasks becomes slower, impeding real-time applications. Addressing this issue is crucial to improving applications’ performance and user experience relying on LLMs, particularly when quick responses are essential.
Current methods to alleviate this issue include speculative sampling techniques, which generate and verify tokens in parallel to reduce latency. Traditional speculative sampling methods often rely on static draft trees that do not account for context, leading to inefficiencies and suboptimal acceptance rates of draft tokens. These methods aim to reduce inference time but still face limitations in performance.
Researchers from Peking University, Microsoft Research, the University of Waterloo and Vector Institute introduced EAGLE-2, a method leveraging a context-aware dynamic draft tree to enhance speculative sampling. EAGLE-2 builds upon the previous EAGLE method, offering significant improvements in speed while maintaining the quality of generated text. This method dynamically adjusts the draft tree based on context, using confidence scores from the draft model to approximate acceptance rates.
EAGLE-2 dynamically adjusts the draft tree based on context, enhancing speculative sampling. Its methodology includes two main phases: expansion and reranking. The process begins with the expansion phase, where the draft model inputs the most promising nodes from the latest layer of the draft tree to form the next layer. Confidence scores from the draft model approximate acceptance rates, allowing efficient prediction and verification of tokens. During the reranking phase, tokens with higher acceptance probabilities are selected for the original LLM’s input during verification. This two-phase approach ensures the draft tree adapts to the context, significantly improving token acceptance rates and overall efficiency. This method eliminates the need for multiple forward passes, thus accelerating the inference process without compromising the quality of the generated text.
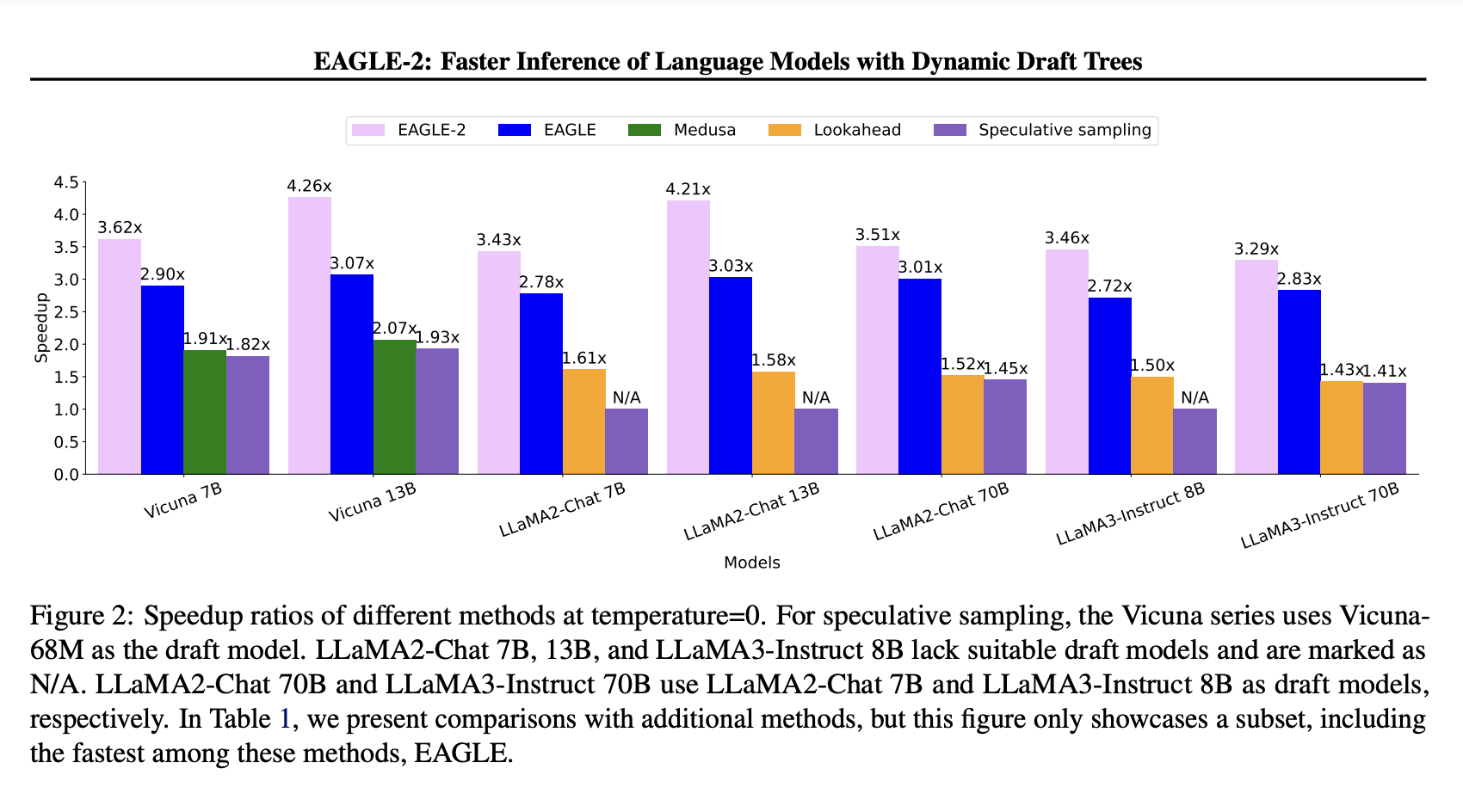
The proposed method showed remarkable results. For instance, in multi-turn conversations, EAGLE-2 achieved a speedup of approximately 4.26x, while in code generation tasks, it reached up to 5x. The average number of tokens generated per drafting-verification cycle was significantly higher than other methods, roughly twice that of standard speculative sampling. This performance boost makes EAGLE-2 a valuable tool for real-time NLP applications.
Performance evaluations also show that EAGLE-2 achieves speedup ratios between 3.05x and 4.26x across various tasks and LLMs, outperforming the previous EAGLE method by 20%-40%. It maintains the distribution of the generated text, ensuring no loss in the output quality despite the increased speed. EAGLE-2 demonstrated the best performance in extensive tests across six tasks and three series of LLMs, confirming its robustness and efficiency.
In conclusion, EAGLE-2 effectively addresses computational inefficiencies in LLM inference by introducing a context-aware dynamic draft tree. This method offers a substantial performance boost without compromising the quality of the generated text, making it a significant advancement in NLP. Future research and applications should consider integrating dynamic context adjustments to enhance the performance of LLMs further.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 45k+ ML SubReddit
The post EAGLE-2: An Efficient and Lossless Speculative Sampling Method Achieving Speedup Ratios 3.05x – 4.26x which is 20% – 40% Faster than EAGLE-1 appeared first on MarkTechPost.