The creative applications and management of pretrained language models have led to some great improvements in the quality of information retrieval (IR). Existing IR models are usually trained on large datasets comprising hundreds of thousands or even millions of queries and relevance judgments, especially those that can generalize to new, uncommon topics.
The usefulness and necessity of such large-scale data for language model optimization for information retrieval tasks are questioned, raising scientific and engineering issues. In particular, it is not apparent from a scientific standpoint whether this massive amount of data is necessary, and from an engineering standpoint, it is not evident how to train IR models for languages with little or no labeled IR data or for niche domains.
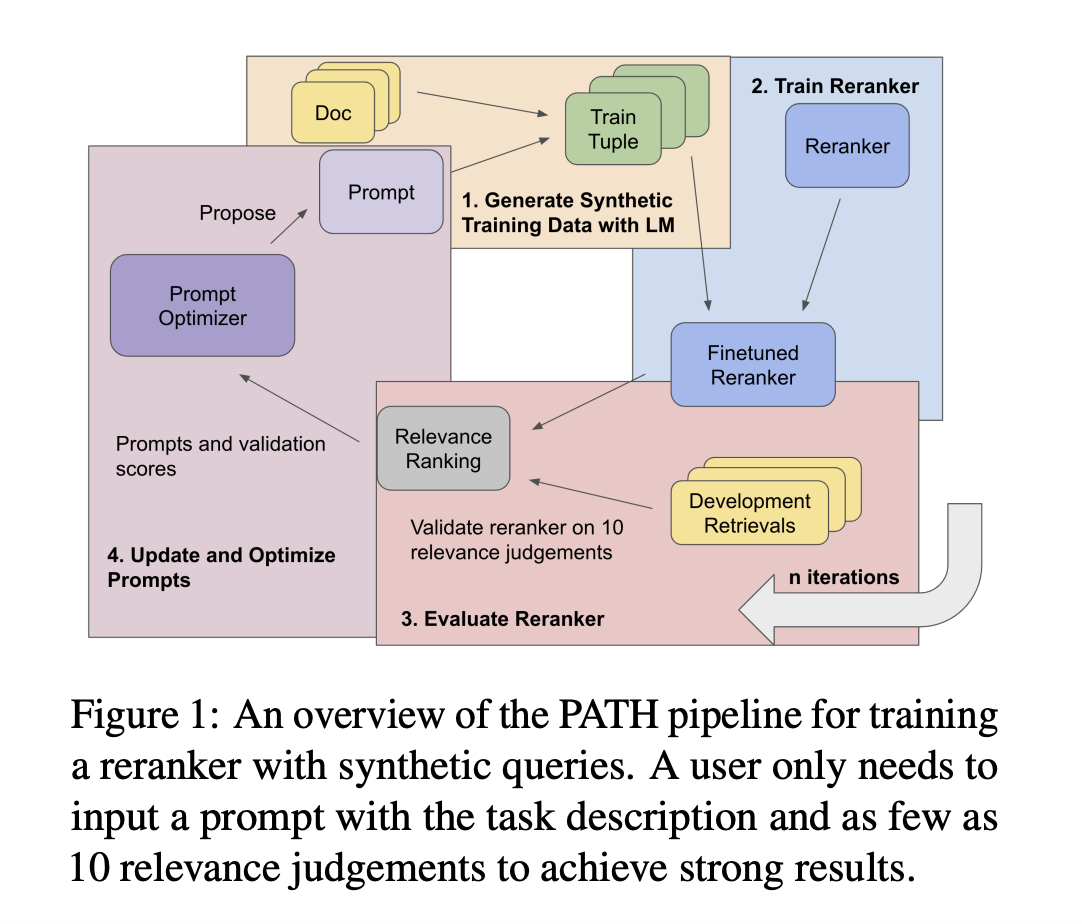
In recent research, a team of researchers from the University of Waterloo, Stanford University, and IBM Research AI has presented a technique for training small-scale neural information retrieval models using as few as ten gold relevance labels, that is, models with less than 100 million parameters. This approach has been named PATH – Prompts as Auto-optimized Training Hyperparameters.
The foundation of this method is the creation of fictitious document queries via a language model (LM). The key innovation is that the language model automatically optimizes the prompt it uses to create these fictitious queries, guaranteeing that the training quality is optimized.
The team has shared the procedure, which is as follows. A text corpus and a very small number of relevant labels are the starting points. Then potential search queries are created that might be pertinent to the documents in the corpus using an LM. In order to create training data, pairs of queries and passages must be created. Optimizing the LM prompt, which directs the creation of the inquiry, is a crucial step in raising the caliber of the synthetic data in response to input from the training procedure.
Using the BIRCO benchmark, which consists of difficult and unusual IR tasks, the team has conducted trials and discovered that this approach greatly improves the performance of the trained models. In particular, the small-scale models outperform RankZephyr and are competitive with RankLLama, having been trained with minimally labeled data and optimized prompts. These later models, which included 7 billion parameters and were trained on datasets with more than 100,000 labels, are significantly larger.
These outcomes demonstrate how well automatic rapid optimization produces artificial datasets of superior quality. This approach not only shows that effective IR models can be trained with fewer resources, but it also shows that, with the right adjustments to the data creation process, smaller models can outperform much bigger models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 45k+ ML SubReddit
The post Path: A Machine Learning Method for Training Small-Scale (Under 100M Parameter) Neural Information Retrieval Models with as few as 10 Gold Relevance Labels appeared first on MarkTechPost.