MARS5 TTS, a game changer in open-source text-to-speech systems, has been released by the Camb AI team. This innovative model offers exceptional prosodic control and voice cloning capabilities, requiring less than 5 seconds of audio input. The system employs a two-stage architecture consisting of a 750M Auto-Regressive (AR) model and a 450M Non-Auto-Regressive (NAR) model. MARS5 utilizes a BPE tokenizer, enabling precise control over punctuation, pauses, and stops, thus advancing the field of speech synthesis.
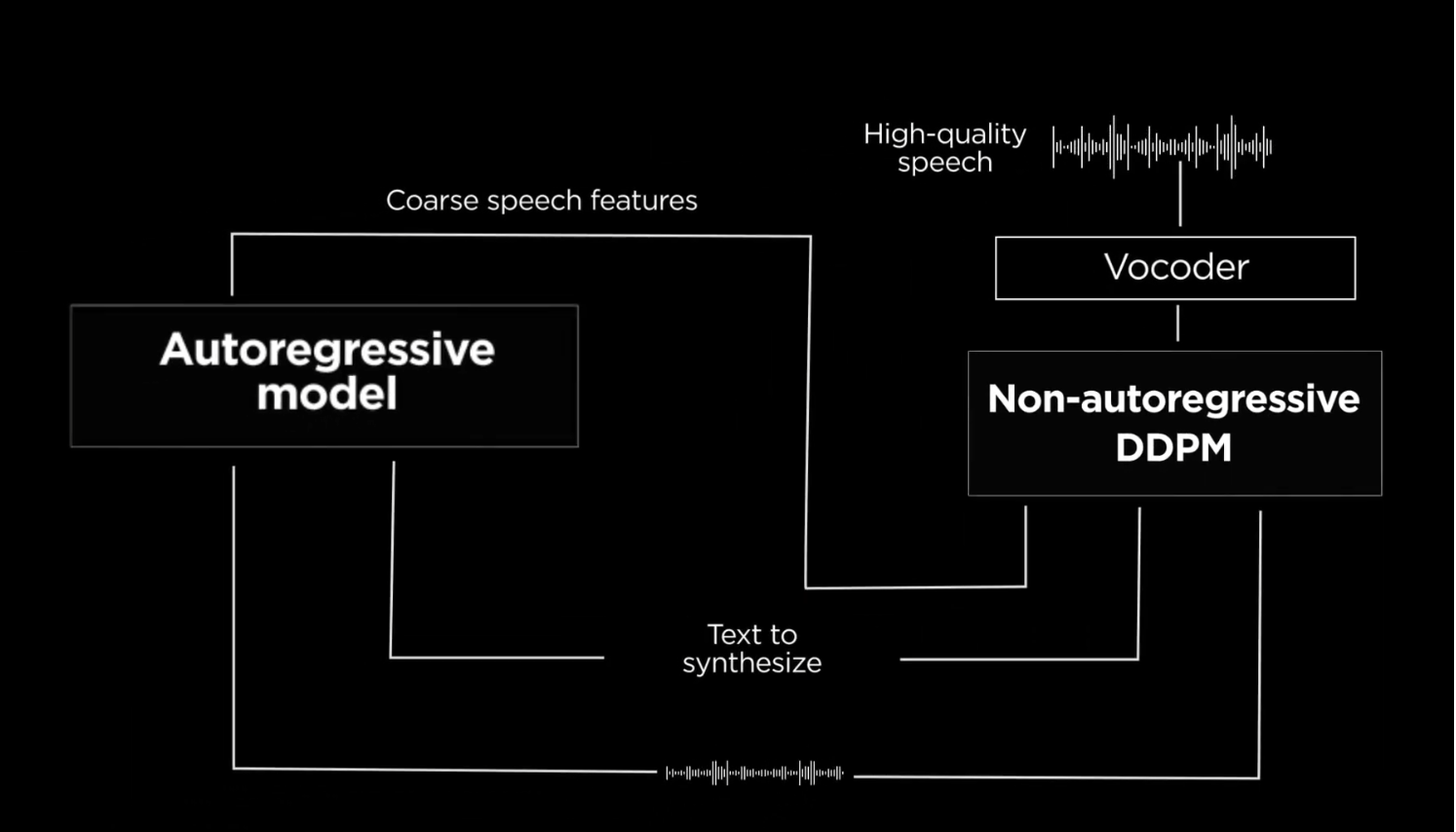
The model’s architecture follows a unique two-stage AR-NAR pipeline. In the initial stage, an autoregressive transformer model generates coarse (L0) encodec speech features from the input text and reference audio. Subsequently, these features, along with the text and reference, are refined using a multinomial Denoising Diffusion Probabilistic Model (DDPM) to produce the remaining encodec codebook values. Finally, a vocoder transforms the DDPM output into the final audio.
The AR component of MARS5 predicts L0 coarse tokens, which are then further refined by the NAR DDPM model. This refined output is processed by the vocoder to generate the final audio. The model’s training on raw audio in conjunction with byte-pair-encoded text allows for nuanced control over prosody through punctuation and capitalization. For instance, adding commas introduces pauses, while capitalizing words emphasizes them, providing a natural method for guiding the generated output’s prosody.
Compared to other leading language models like GPT and Gemini, MARS5 distinguishes itself through its specialized focus on text-to-speech synthesis and its unique AR-NAR architecture. While GPT and Gemini are primarily designed for text generation and understanding, MARS5 is optimized for producing high-quality, controllable speech output. Its use of DDPM in the NAR stage and the incorporation of prosodic control through text formatting sets it apart in speech synthesis.
MARS5 demonstrates impressive results in voice cloning and prosodic control. The system supports two inference modes: a fast “shallow clone” that doesn’t require the reference audio’s transcript, and a slower but higher-quality “deep clone” that utilizes the prompt transcript. With just 5 seconds of audio and a text snippet, MARS5 can generate speech for diverse and challenging scenarios, including sports commentary and anime voiceovers, showcasing its versatility and effectiveness.
To use MARS5, a reference audio file between 2-12 seconds long, with 6-second samples yielding optimal results is provided. The system accepts text input with punctuation and capitalization for prosodic control. Users can perform a “deep clone” for enhanced quality by providing the reference audio’s transcript, though this process takes longer. MARS5’s ability to handle complex prosodic scenarios makes it suitable for various applications in entertainment, education, and accessibility.
MARS5 TTS represents a significant advancement in open-source text-to-speech technology. Its innovative architecture, combining AR and NAR models with DDPM, enables unprecedented control over speech synthesis. The system’s ability to clone voices with minimal input and generate high-quality, prosodically rich speech positions it as a valuable tool for developers and researchers in the field of artificial intelligence and speech technology.
Check out the Model and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 45k+ ML SubReddit
The post Camb AI Releases MARS5 TTS: A Novel Open Source Text to Speech Model for Insane Prosody appeared first on MarkTechPost.