NuMind introduces NuExtract, a cutting-edge text-to-JSON language model that represents a significant advancement in structured data extraction from text. This model aims to transform unstructured text into structured data highly efficiently. The innovative design and training methodologies used in NuExtract position it as a superior alternative to existing models, providing high performance and cost-efficiency.
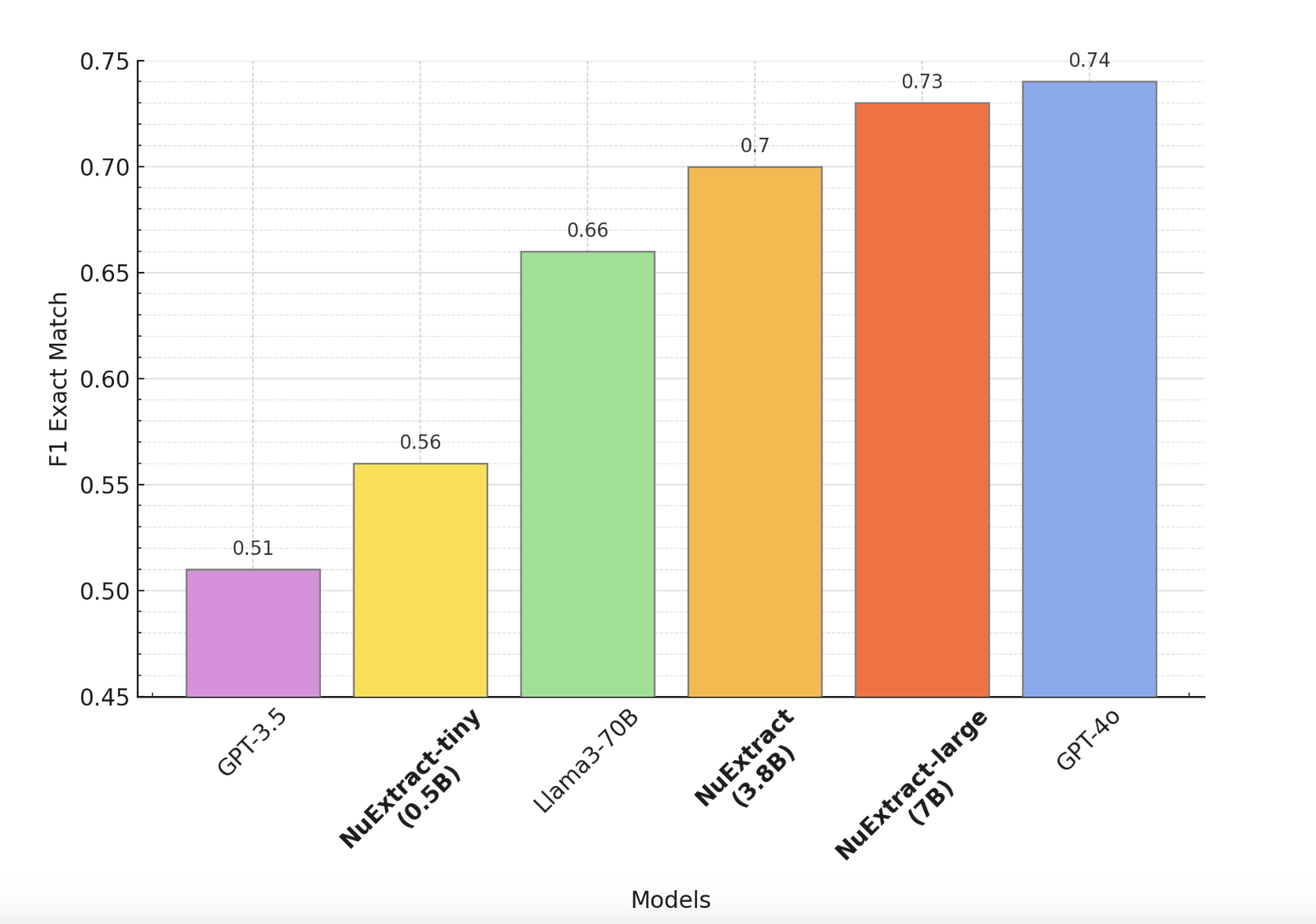
NuExtract is engineered to operate efficiently with models ranging from 0.5 billion to 7 billion parameters, achieving similar or superior extraction capabilities compared to larger, popular language models (LLMs). This efficiency is achieved by creating three distinct models within the NuExtract family: NuExtract-tiny, NuExtract, and NuExtract-large. These models have demonstrated remarkable performance in various extraction tasks, often outperforming significantly larger LLMs.
NuExtract is available in three trained versions:
- NuExtract-tiny (0.5B): This lightweight model is ideal for applications requiring efficient performance with minimal computational resources. Despite its small size, NuExtract-tiny performs better than some larger models, making it suitable for tasks where resource constraints are a priority.
- NuExtract (3.8B): This model balances size and performance, making it well-suited for more demanding extraction tasks. It leverages a moderate number of parameters to deliver high accuracy and versatility, handling a wide range of structured extraction tasks efficiently.
- NuExtract-large (7B): The most powerful version, designed for the most complex and intensive extraction tasks. With 7 billion parameters, NuExtract-large achieves performance levels comparable to top-tier LLMs like GPT-4 while being significantly smaller and more cost-effective. This model is perfect for applications requiring the highest accuracy and detail in data extraction.
The primary challenge NuExtract addresses is structured extraction, which involves extracting diverse information types such as entities, quantities, dates, and hierarchical relationships from documents. The extracted information is structured into a JSON format, making it easier to parse & integrate into databases or use for automated actions. For instance, extracting data from a document and organizing it into a hierarchical tree structure in JSON format is a task NuExtract handles with high precision and efficiency.
Structured extraction tasks vary significantly in complexity. While traditional methods like regular expressions or non-generative machine learning models could handle simple entity extraction, they must improve when dealing with more complex tasks requiring deeper hierarchical extraction. Modern generative LLMs, including GPT-4, have advanced these capabilities by enabling the generation of deep extraction trees. However, NuExtract has shown that it can achieve similar results with much smaller models, making it a more practical solution for many applications.
One of NuExtract’s key advantages is its ability to handle zero-shot and fine-tuned extraction scenarios. The model can extract information based solely on a predefined template or schema in a zero-shot setting without requiring task-specific training data. This capability is particularly valuable for applications where creating large annotated datasets is impractical. Additionally, NuExtract can be fine-tuned for specific applications, enhancing its performance further for specialized tasks.
To train NuExtract, the developers employed a novel approach: They used a large and diverse corpus of text from the C4 dataset, which was annotated using a modern LLM with carefully crafted prompts. This synthetic data was then used to fine-tune a compact, generic foundation model, resulting in a highly specialized task-specific model. This training methodology ensures that NuExtract can generalize well across different domains, making it versatile for various structured extraction tasks.
The model consistently produces valid JSON outputs, adheres to the schema, and accurately extracts relevant information. For example, in tests involving the parsing of chemical reactions, NuExtract successfully identified, classified, and extracted quantities of chemical substances and reaction conditions such as duration and temperature. This high accuracy demonstrates NuExtract’s potential to tackle complex chemistry, medicine, law, and finance extraction tasks.
NuExtract’s compact size offers several practical benefits. Smaller models are less expensive to run, allowing for cost-effective inference. They also enable local deployment, essential for applications requiring data privacy. The ease of fine-tuning these models makes them adaptable to specific use cases, further enhancing their utility.
In conclusion, NuExtract by NuMind represents a significant leap forward in structured data extraction from text. Its innovative design, efficient training methodology, and impressive performance across various tasks make it a valuable tool for transforming unstructured text into structured data. The model’s ability to perform well in both zero-shot and fine-tuned settings, coupled with its cost-efficiency and ease of deployment, positions it as a leading solution for modern data extraction challenges.
The post NuMind Releases NuExtract: A Lightweight Text-to-JSON LLM Specialized for the Task of Structured Extraction appeared first on MarkTechPost.