Sleep is a vital physiological process that is intricately linked to overall health. However, accurately assessing sleep and diagnosing sleep disorders remains a complex task due to the need for multi-modal data interpretation, typically obtained through polysomnography (PSG). Current methods for sleep monitoring and analysis often rely on extensive manual evaluation by trained technicians, which is time-consuming and susceptible to variability. Researchers from Stanford University and the Technical University of Denmark have introduced SleepFM to capture the richness of sleep recording fully.
Existing methods for sleep analysis utilizing deep learning models, predominantly involve end-to-end convolutional neural networks (CNNs) trained on raw PSG data. While these models can automate some aspects of sleep analysis, they often need to improve in performance, particularly when dealing with multi-modal data from different physiological sources. SleepFM is the first multi-modal foundation model for sleep analysis that addresses existing models’ limitations. SleepFM leverages a large dataset of PSG records from over 14,000 participants to learn robust embeddings through contrastive learning (CL). The model employs a novel leave-one-out approach to CL, which improves the performance of downstream tasks compared to the standard pairwise CL.
The researchers curated an extensive PSG dataset, encompassing 100,000 hours of recordings, and employed a multi-step preprocessing strategy to preserve crucial signal characteristics. SleepFM’s architecture involves three 1D CNNs, each generating embeddings for different modalities (brain activity signals, ECG, and respiratory signals). These CNNs are based on EfficientNet architecture, optimized for efficiency and complexity reduction. The innovative leave-one-out CL framework allows the model to learn representations by aligning each modality with an aggregate representation of the remaining modalities, encouraging holistic learning of multi-modal data.
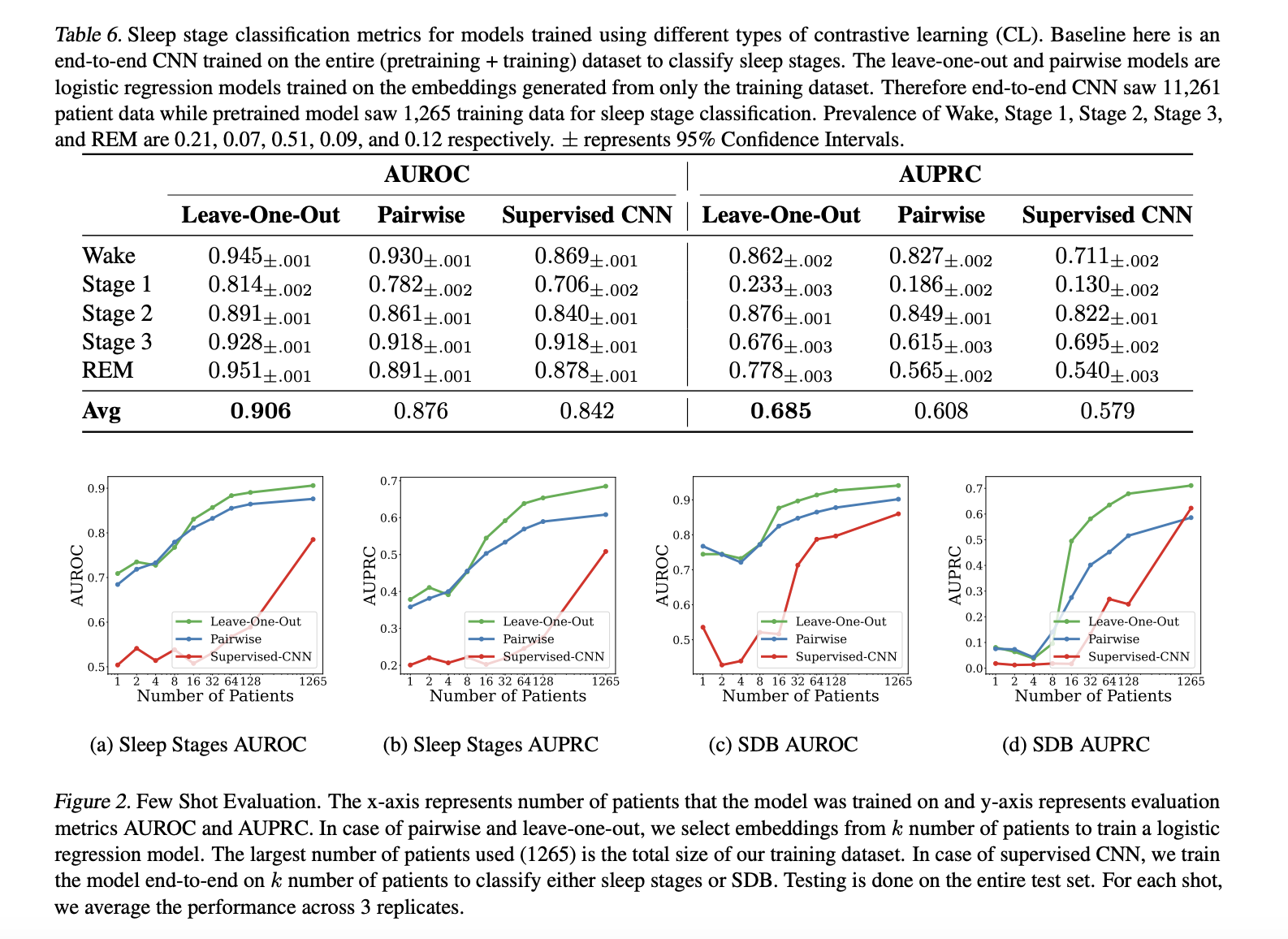
In performance evaluations, SleepFM demonstrated significant improvements over end-to-end CNNs. For sleep stage classification, the logistic regression model trained on SleepFM’s embeddings achieved a macro AUROC of 0.88 compared to 0.72 from CNNs, and a macro AUPRC of 0.72 versus 0.48. In sleep-disordered breathing (SDB) detection, SleepFM similarly outperformed CNNs, with an AUROC of 0.85 and an AUPRC of 0.77. Additionally, SleepFM excelled in retrieving corresponding recording clips from different modalities, showcasing a 48% top-1 average accuracy among 90,000 candidates. These results underscore the model’s ability to capture rich, multi-modal sleep data representations effectively.
In summary, the proposed model addresses the challenges of sleep monitoring and disorder diagnosis and significantly outperforms traditional CNNs in various sleep-related tasks. The innovative leave-one-out contrastive learning approach and robust dataset curation highlight the potential of holistic multi-modal modeling to advance sleep analysis. SleepFM’s superior performance in sleep stage classification and SDB detection, along with its robust generalization to external datasets, makes it a promising tool for enhancing sleep research and clinical applications.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 45k+ ML SubReddit
The post Researchers at Stanford University Propose SleepFM: The First Multi-Modal Foundation Model for Sleep Analysis appeared first on MarkTechPost.