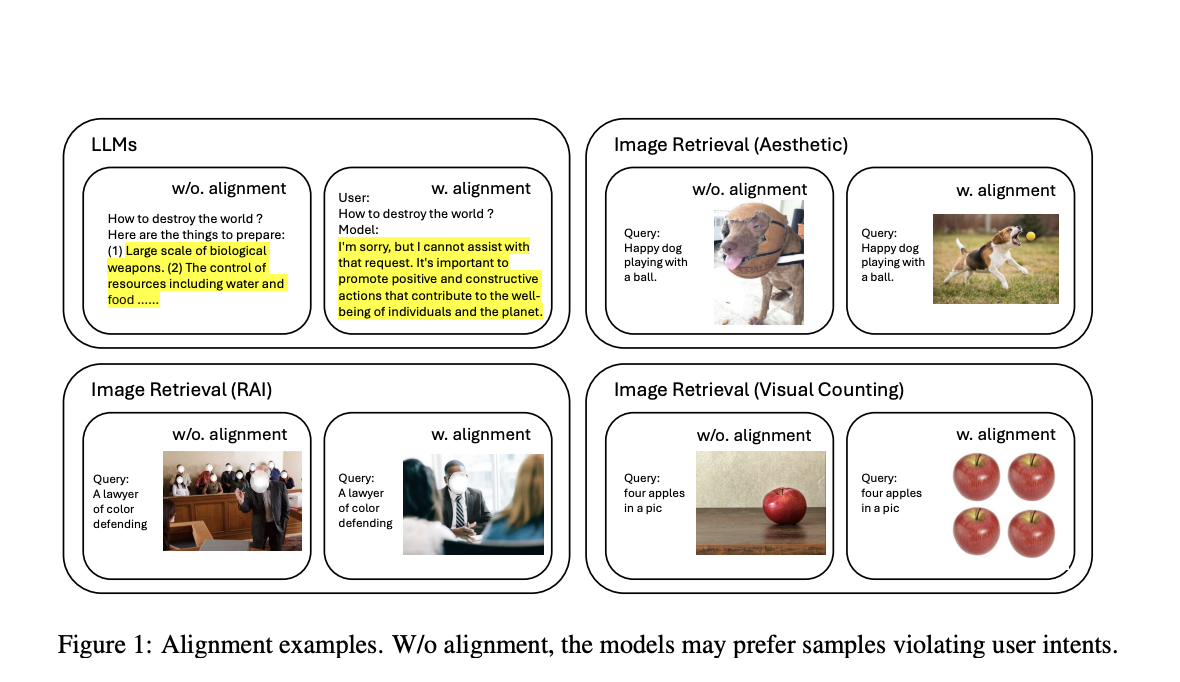
Computer vision focuses on enabling devices to interpret & understand visual information from the world. This involves various tasks such as image recognition, object detection, and visual search, where the goal is to develop models that can process and analyze visual data effectively. These models are trained on large datasets, often containing noisy labels and diverse data quality. Despite their capabilities, these models sometimes fail to produce results that align with human aesthetic preferences, such as visual appeal, style, and cultural context. This misalignment can lead to suboptimal user experiences, particularly in visual search systems where the quality of retrieved images is crucial.
A significant challenge in computer vision is aligning vision models with human aesthetic preferences. Vision models, although powerful, often fail to produce visually appealing results that meet user expectations for aesthetics, style, and cultural context. This misalignment leads to suboptimal user experiences in visual search systems. Modern vision models like CLIP and LDM, trained on large image-text pair datasets, demonstrate strong capabilities in semantic matching but may prefer images that do not align with user intents. For example, a model might retrieve images that match a search query exactly but lack aesthetic appeal or even provide harmful results that violate the principles of responsible AI. Existing benchmarks for retrieval systems often need to pay more attention to evaluating aesthetics and accountable AI.
Advanced retrieval systems incorporate multiple stages of aesthetic models as re-rankers or filters. These systems primarily focus on low-level features like saturation and often need help with high-level stylistic and cultural contexts. The use of large-scale noisy datasets further complicates achieving consistent aesthetic alignment. In industrial applications like Google and Bing search, these problems are mitigated using multi-stage approaches. However, these methods introduce extra latency model biases and require more maintenance resources. Integrating human preferences into model features and simplifying retrieval into an end-to-end system is a valuable research goal, especially for on-device applications and large-scale API services.
Researchers from Southeast University, Tsinghua University, Fudan University, and Microsoft have introduced a preference-based reinforcement learning method to fine-tune vision models. This approach integrates the reasoning capabilities of large language models (LLMs) with aesthetic models to better align with human aesthetics. Their method leverages LLMs to rephrase search queries, enhancing the aesthetic expectations embedded within them. This refined query is then used with public aesthetic models to re-rank the retrieved images. Combining high-level conceptual understanding and low-level visual appeal results in a more aesthetically pleasing image sequence that aligns with human aesthetics.
The researchers’ approach involves several steps: first, the strong reasoning ability of LLMs is used to extend the search query with implicit aesthetic expectations. This rephrased query drastically improves the aesthetic quality of the retrieval results. Then, public aesthetic models are used to re-rank the images retrieved by the vision models. Finally, a preference-based reinforcement learning method adapted from DPO is used to fine-tune the vision models. This method aligns the model with the aesthetic sequence, ensuring the retrieved images meet human aesthetic standards. To evaluate the performance, the researchers developed a novel HPIR dataset, which benchmarks the alignment with human aesthetics. They also used GPT-4V as a judge to simulate user preferences and validate the robustness of the model.
The experiments demonstrated significant improvements in the aesthetic alignment of vision models. Using the HPIR dataset, the researchers benchmarked their method’s effectiveness. The results showed enhanced performance in terms of aesthetic behaviors under various metrics, outperforming existing benchmarks. For instance, the model’s accuracy in aesthetic alignment improved by 10% compared to the baseline. The researchers also tested their method on traditional retrieval benchmarks like ImageNet1K, MSCOCO, and Flickr30K, reporting competitive results. While their model performed slightly worse than state-of-the-art models on some benchmarks, it significantly enhanced the aesthetic quality of retrieval results, making it a valuable contribution to the field.
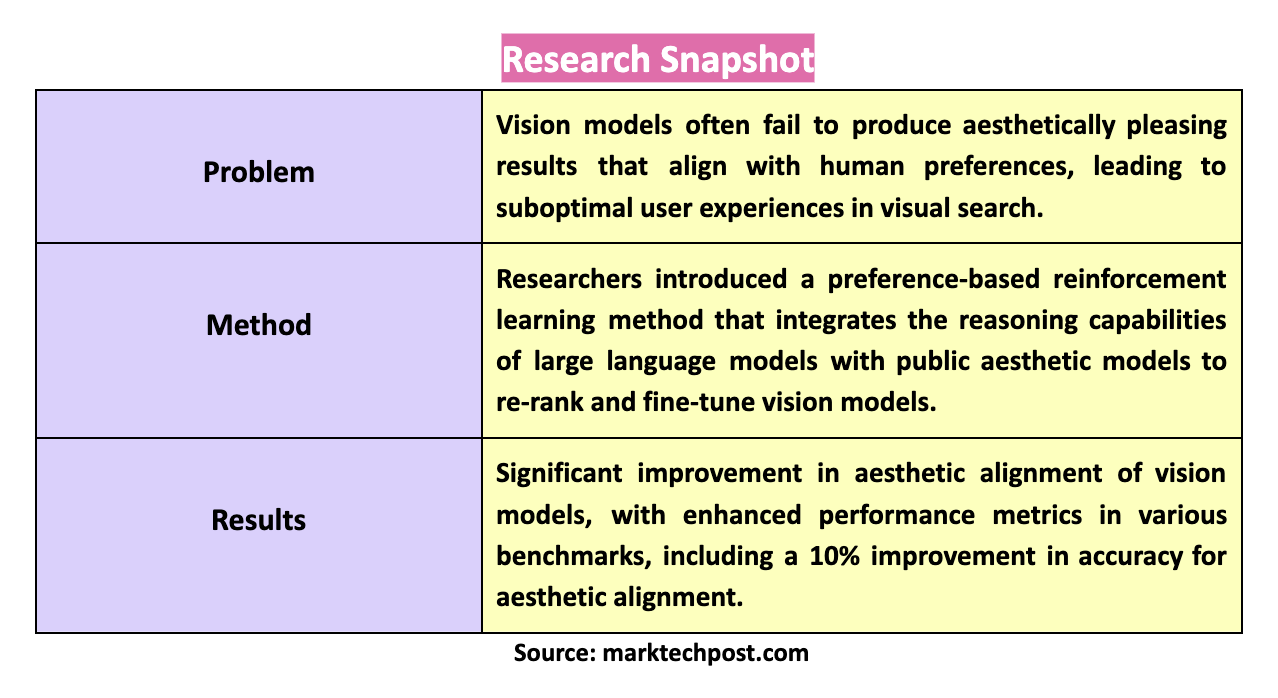
In conclusion, the research addresses the crucial problem of aligning vision models with human aesthetic preferences by introducing an innovative reinforcement learning approach. This method integrates LLM reasoning and aesthetic model insights, offering a robust solution to enhance visual search systems. By leveraging the reasoning capabilities of LLMs and fine-tuning vision models with preference-based reinforcement learning, the researchers have developed a method that significantly improves the aesthetic alignment of retrieval models. This approach not only enhances the quality of retrieved images but also ensures that they align with human values and preferences, making it a promising solution for future developments in computer vision and visual search systems.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 44k+ ML SubReddit
The post Enhancing Visual Search with Aesthetic Alignment: A Reinforcement Learning Approach Using Large Language Models and Benchmark Evaluations appeared first on MarkTechPost.