Large Language Models (LLMs) have become increasingly prominent in natural language processing because they can perform a wide range of tasks with high accuracy. These models require fine-tuning to adapt to specific tasks, which typically involves adjusting many parameters, thereby consuming substantial computational resources and memory.
The fine-tuning process of LLMs presents a significant challenge as it becomes highly resource-intensive, particularly when dealing with complex, knowledge-intensive tasks. The need to update many parameters during fine-tuning can exceed the capacity of standard computational setups.
Existing work includes methods like Parameter Efficient Fine-Tuning (PEFT), such as LoRA and Parallel Adapter, which adjust a small fraction of model parameters to reduce memory usage. Other approaches involve adapter-based tuning, prompt, sparse, and reparametrization-based tuning. Techniques like Switch Transformers and StableMoE utilize a Mixture of Experts for efficient computation. Furthermore, models like QLoRA and methods like CPU-offload and LST focus on memory efficiency, while SparseGPT explores sparsity to enhance performance.
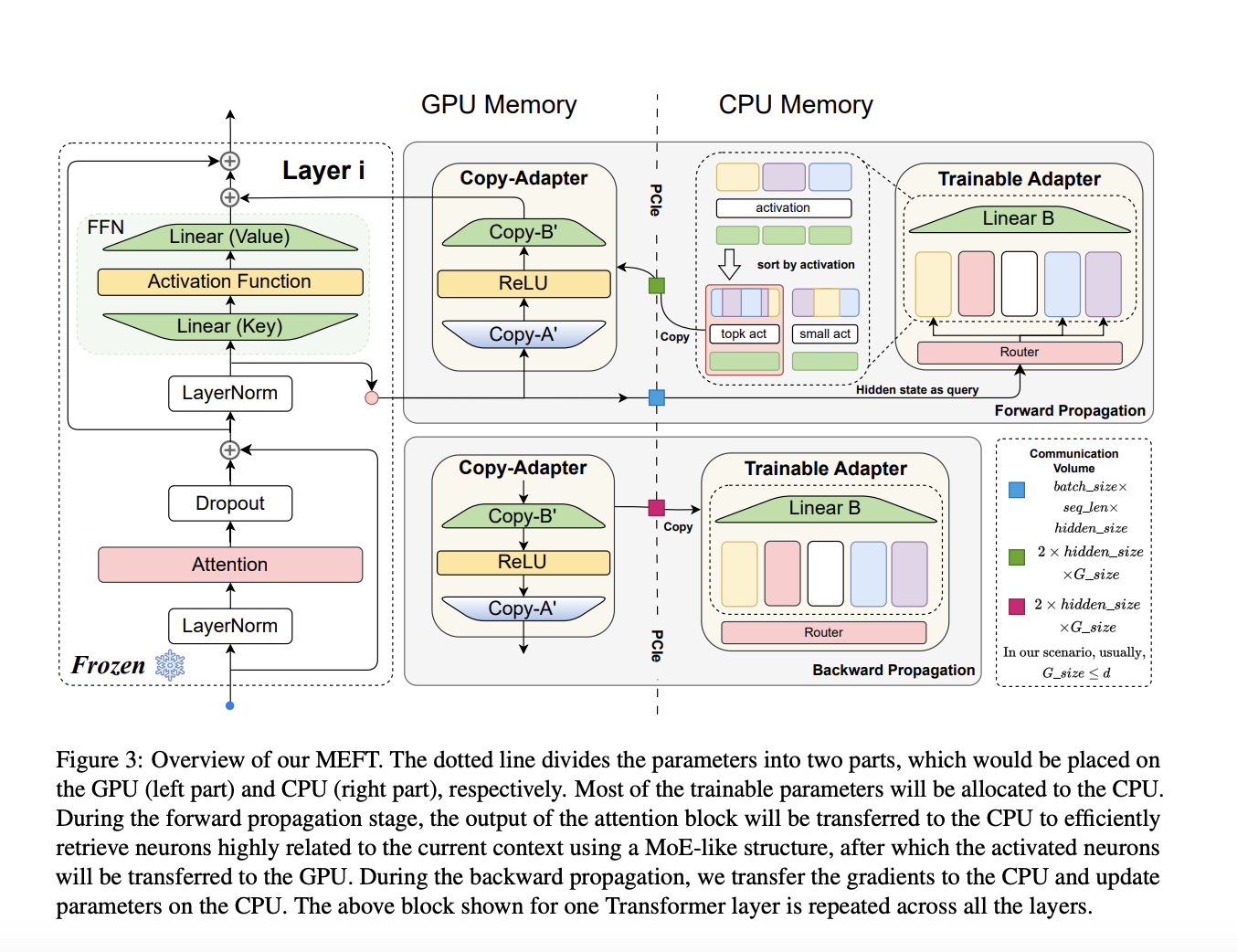
Researchers from Shandong University, Carnegie Mellon University, Academy of Mathematics and Systems Science, and Leiden University have introduced MEFT, a novel fine-tuning method designed to be memory-efficient. This method leverages the inherent activation sparsity in the Feed-Forward Networks (FFNs) of LLMs and the larger capacity of CPU memory compared to GPU memory. MEFT stores and updates larger adapter parameters on the CPU, using a Mixture of Experts (MoE)-like architecture to optimize computations and reduce GPU-CPU communication.
MEFT dynamically loads parameters from CPU memory to GPU for training, activating only a subset of relevant neurons to the input. This selective activation minimizes GPU memory usage and computational overhead. The method involves sparse activation, where only highly relevant neurons based on input similarity are activated, and a Key-Experts mechanism that uses a routing mechanism to activate a subset of the network, reducing computational complexity and memory transfer between CPU and GPU. Specifically, during the forward computation, the method retrieves the top K keys with the highest similarity to the input, forming a smaller matrix of relevant parameters, which is then moved to the GPU for further processing. This approach ensures that most parameters remain on the CPU, reducing the communication volume and memory usage on the GPU.
MEFT was tested on two models, LLaMA-7B and Mistral-7B, and four datasets: Natural Questions (NQ), SQuAD, ToolBench, and GSM8K. The researchers found that MEFT significantly reduces GPU memory usage by 50%, from 48GB to 24GB, while achieving performance comparable to full fine-tuning methods. For instance, MEFT achieved 0.413 and 0.427 exact match (EM) scores on the NQ dataset using LLaMA-7B and Mistral-7B, respectively. These scores are notably higher than baseline methods like Parallel Adapter and LoRA. The researchers from Shandong University, Carnegie Mellon University, the Academy of Mathematics and Systems Science, and Leiden University found that MEFT’s efficiency in resource utilization allows it to fit a higher proportion of trainable parameters within the limited 24GB GPU capacity.
MEFT’s performance on the SQuAD dataset further demonstrated its effectiveness, achieving EM scores of 0.377 and 0.415 with LLaMA-7B and Mistral-7B, respectively. Additionally, on the ToolBench dataset, MEFT, with its adaptability, outperformed other methods with an intersection-over-union (IoU) score of 0.645 using LLaMA-7B. For GSM8K, a dataset with a strong logical component, MEFT achieved a significant score of 0.525, indicating that sparse training does not compromise performance on logical tasks. The researchers concluded that MEFT’s ability to reduce memory usage without sacrificing performance makes it a valuable tool for fine-tuning LLMs under resource-constrained conditions.
In conclusion, MEFT provides a viable solution to the resource-intensive challenge of fine-tuning large language models. Leveraging sparsity and MoE reduces memory usage and computational demands, making it an effective method for fine-tuning LLMs with limited resources. This innovation addresses the critical scalability problem in model fine-tuning, providing a more efficient and scalable approach. The researchers’ findings suggest that MEFT can achieve results comparable to full-model fine-tuning, making it a significant advancement in natural language processing.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 44k+ ML SubReddit
The post Training on a Dime: MEFT Achieves Performance Parity with Reduced Memory Footprint in LLM Fine-Tuning appeared first on MarkTechPost.