Large Language Models (LLMs) have advanced rapidly, especially in Natural Language Processing (NLP) and Natural Language Understanding (NLU). These models excel in text generation, summarization, translation, and question answering. With these capabilities, researchers are keen to explore their potential in tasks that require reasoning and planning. This study evaluates the effectiveness of specific prompting techniques in enhancing the decision-making abilities of LLMs in complex, sequential tasks.
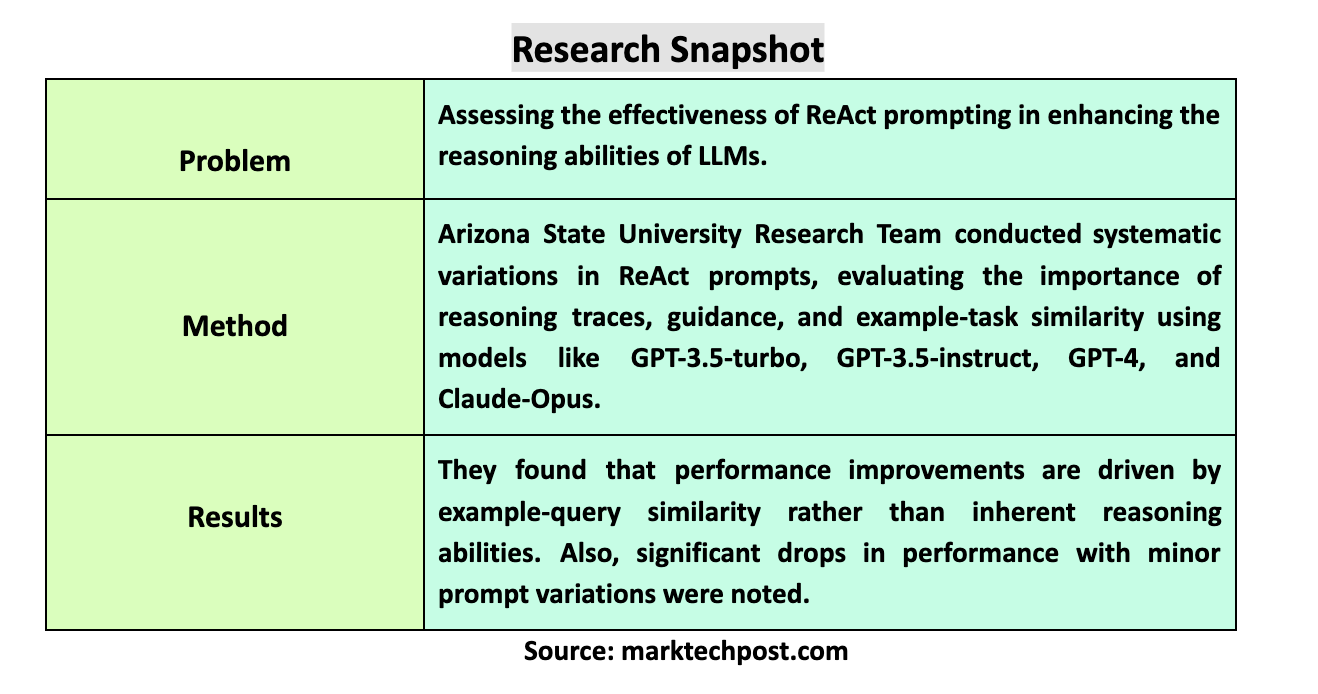
A significant challenge in leveraging LLMs for reasoning tasks is determining whether the improvements are genuine or superficial. The ReAct prompting method, which integrates reasoning traces with action execution, claims to enhance LLM performance in sequential decision-making. However, an ongoing debate exists about whether these enhancements are due to true reasoning abilities or merely pattern recognition based on the input examples. This study aims to dissect these claims & provide a clearer understanding of the factors influencing LLM performance.
Existing methods for improving LLM performance on reasoning tasks include various forms of prompt engineering. Techniques such as Chain of Thought (CoT) and ReAct prompting guide LLMs through complex tasks by embedding structured reasoning or instructions within the prompts. These methods are designed to make the LLMs simulate a step-by-step problem-solving process, which is believed to help in tasks that require logical progression and planning.
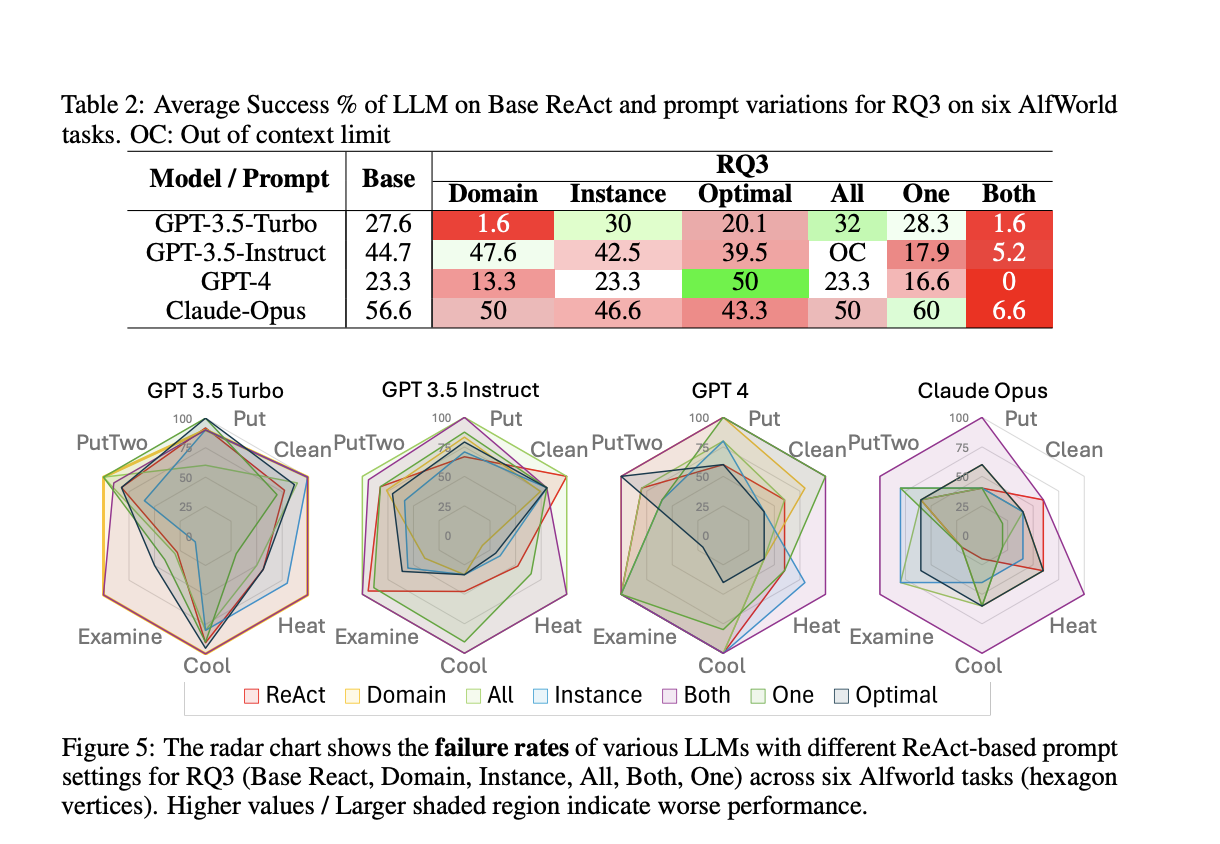
The research team from Arizona State University introduced a comprehensive analysis to evaluate the ReAct framework’s claims. The ReAct method asserts that interleaving reasoning traces with actions enhances LLMs’ decision-making capabilities. The researchers conducted experiments using different models, including GPT-3.5-turbo, GPT-3.5-instruct, GPT-4, and Claude-Opus, within a simulated environment known as AlfWorld. By systematically varying the input prompts, they aimed to identify the true source of performance improvements attributed to the ReAct method.
In their detailed analysis, the researchers introduced several variations to the ReAct prompts to test different aspects of the method. They examined the importance of interleaving reasoning traces with actions, the type and structure of guidance provided, and the similarity between example and query tasks. Their findings were revealing. The performance of LLMs was minimally influenced by the interleaving of reasoning traces with action execution. Instead, the critical factor was the similarity between the input examples and the queries, suggesting that the improvements were due to pattern matching rather than enhanced reasoning abilities.
The experiments yielded quantitative results that underscored the limitations of the ReAct framework. For instance, the success rate for GPT-3.5-turbo on six different tasks in AlfWorld was 27.6% with the base ReAct prompts but improved to 46.6% when using exemplar-based CoT prompts. Similarly, GPT-4’s performance dropped significantly when the similarity between the example and query tasks was reduced, highlighting the method’s brittleness. These results indicate that while ReAct may seem effective, its success heavily depends on the specific examples in the prompts.
One notable finding was that providing irrelevant or placebo guidance did not significantly degrade performance. For instance, using weaker or placebo guidance, where the text provided no relevant information, showed comparable results to strong reasoning trace-based guidance. This challenges the assumption that the content of the reasoning trace is crucial for LLM performance. Instead, the success stems from the similarity between the examples and the tasks rather than the inherent reasoning capabilities of the LLMs.
Research Snapshot
In conclusion, this study challenges the claims of the ReAct framework by demonstrating that its perceived benefits are primarily due to the similarity between example tasks and query tasks. The need for instance-specific examples to achieve high performance poses scalability issues for broader applications. The findings emphasize the importance of closely evaluating prompt-engineering methods and their purported abilities to enhance LLM performance in reasoning and planning tasks.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 43k+ ML SubReddit | Also, check out our AI Events Platform
The post Researchers at Arizona State University Evaluates ReAct Prompting: The Role of Example Similarity in Enhancing Large Language Model Reasoning appeared first on MarkTechPost.