Many developers and researchers working with large language models face the challenge of fine-tuning the models efficiently and effectively. Fine-tuning is essential for adapting a model to specific tasks or improving its performance, but it often requires significant computational resources and time.
Existing solutions for fine-tuning large models, like the common practice of adjusting all model weights, can be very resource-intensive. This process demands substantial memory and computational power, making it impractical for many users. Some advanced techniques and tools can help optimize this process, but they often require a deep understanding of the process, which can be a hurdle for many users.
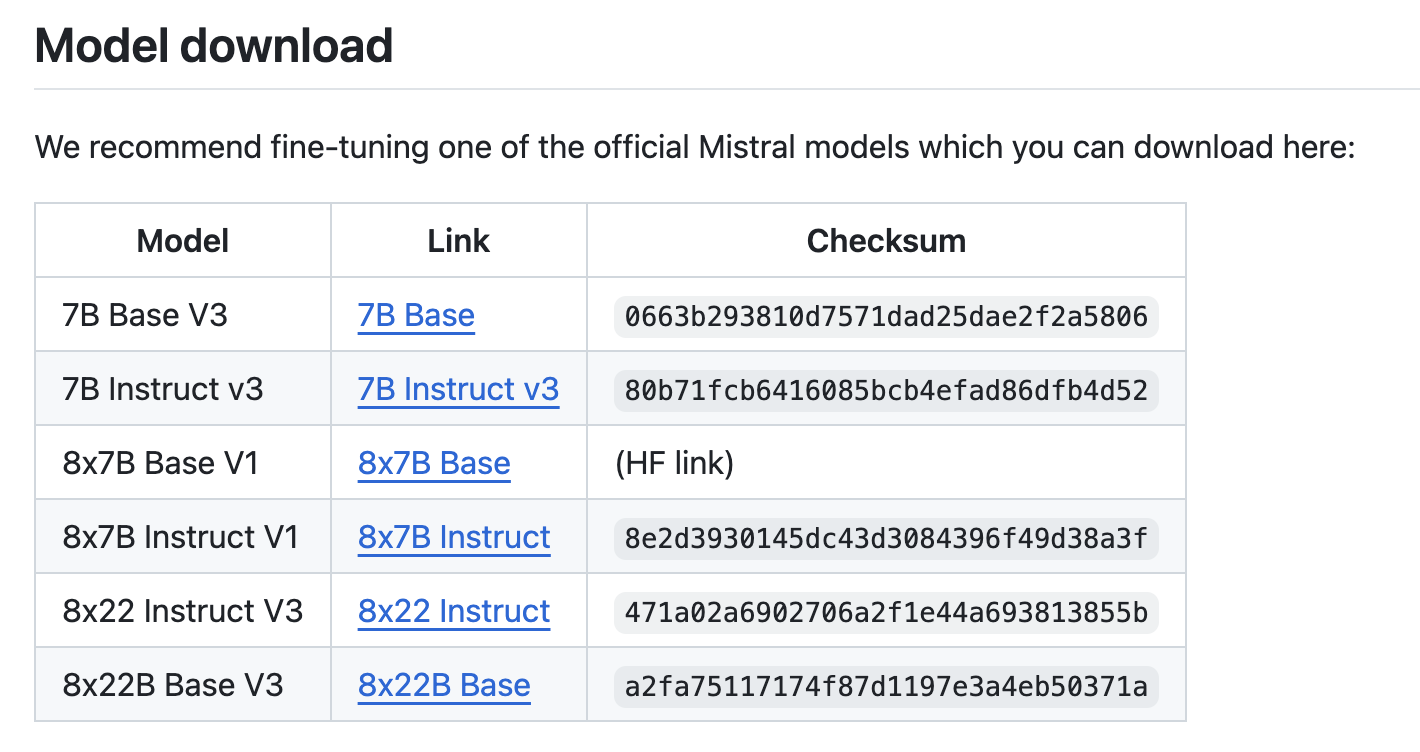
Meet Mistral-finetune: a promising solution to this problem. Mistral-finetune is a lightweight codebase designed for the memory-efficient and performant fine-tuning of large language models developed by Mistral. It leverages a method known as Low-Rank Adaptation (LoRA), where only a small percentage of the model’s weights are adjusted during training. This approach significantly reduces computational requirements and speeds up fine-tuning, making it more accessible to a broader audience.
Mistral-finetune is optimized for use with powerful GPUs like the A100 or H100, which enhances its performance. However, for smaller models, such as the 7 billion parameter (7B) versions, even a single GPU can suffice. This flexibility allows users with varying levels of hardware resources to take advantage of this tool. The codebase supports multi-GPU setups for larger models, ensuring scalability for more demanding tasks.
The tool’s effectiveness is demonstrated through its ability to fine-tune models quickly and efficiently. For example, training a model on a dataset like Ultra-Chat using an 8xH100 GPU cluster can be completed in around 30 minutes, yielding a strong performance score. This efficiency represents a major advancement over traditional methods, which can take much longer and require more resources. The capability to handle different data formats, such as instruction-following and function-calling datasets, further showcases its versatility and robustness.
In conclusion, mistral-finetune addresses the common challenges of fine-tuning large language models by offering a more efficient and accessible approach. Its use of LoRA significantly reduces the need for extensive computational resources, enabling a broader range of users to fine-tune models effectively. This tool not only saves time but also opens up new possibilities for those working with large language models, making advanced AI research and development more achievable.
The post Mistral-finetune: A Light-Weight Codebase that Enables Memory-Efficient and Performant Finetuning of Mistral’s Models appeared first on MarkTechPost.