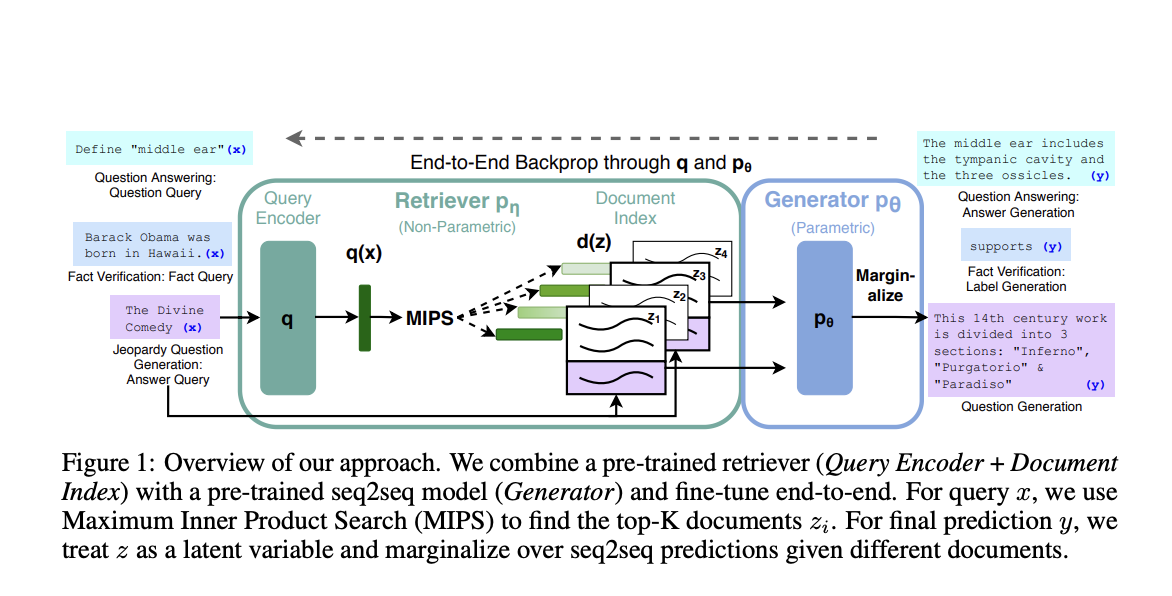
Knowledge-intensive Natural Language Processing (NLP) involves tasks requiring deep understanding and manipulation of extensive factual information. These tasks challenge models to effectively access, retrieve, and utilize external knowledge sources, producing accurate and relevant outputs. NLP models have evolved significantly, yet their ability to handle knowledge-intensive tasks still needs to be improved due to their static nature and inability to incorporate external knowledge dynamically.
The primary challenge in knowledge-intensive NLP tasks is that large pre-trained language models need help accessing and manipulating knowledge precisely. These models often need help to prove their decisions and update their knowledge base. This limitation results in models that cannot efficiently handle tasks requiring dynamic knowledge access and integration. Consequently, there is a need for new architectures that can incorporate external information dynamically and flexibly.
Existing research includes frameworks like REALM and ORQA, which integrate pre-trained neural language models with differentiable retrievers for enhanced knowledge access. Memory networks, stack-augmented networks, and memory layers enrich systems with non-parametric memory. General-purpose architectures like BERT, GPT-2, and BART perform strongly on various NLP tasks. Retrieval-based methods, such as Dense Passage Retrieval, improve performance across open-domain question answering, fact verification, and question generation, demonstrating the benefits of integrating retrieval mechanisms in NLP models.
Researchers from Facebook AI Research, University College London, and New York University introduced Retrieval-Augmented Generation (RAG) models to address these limitations. RAG models combine parametric memory from pre-trained seq2seq models with non-parametric memory from a dense vector index of Wikipedia. This hybrid approach enhances the performance of generative tasks by dynamically accessing and integrating external knowledge, thus overcoming the static nature of traditional models.
RAG models utilize a pre-trained neural retriever to access relevant passages from Wikipedia and a seq2seq transformer (BART) to generate responses. The retriever provides the top-K documents based on the input query, and the generator produces output by conditioning these documents. There are two RAG variants: RAG-Sequence, which uses the same document for all tokens, and RAG-Token, which allows different documents for each token. This structure enables the model to generate more accurate and contextually relevant responses by leveraging both parametric and non-parametric memory.
The performance of RAG models is notable across several knowledge-intensive tasks. On open-domain QA tasks, RAG models set new state-of-the-art results. For instance, in Natural Questions (NQ), TriviaQA, and WebQuestions, RAG achieved higher exact match scores, outperforming parametric seq2seq models and task-specific retrieve-and-extract architectures. RAG’s retriever, initialized using the DPR’s retriever with retrieval supervision on Natural Questions and TriviaQA, contributed significantly to these results. Additionally, for MS-MARCO NLG, RAG-Sequence outperformed BART by 2.6 Bleu points and 2.6 Rouge-L points, generating more factual, specific, and diverse language.
The researchers demonstrated that RAG models offer several advantages. They showed that combining parametric and non-parametric memory with generation tasks significantly improves performance. RAG models generated more factual and specific responses than BART, with human evaluators preferring RAG’s outputs. In FEVER fact verification, RAG achieved results within 4.3% of state-of-the-art models, demonstrating its efficacy in both generative and classification tasks.
In conclusion, the introduction of RAG models in handling knowledge-intensive NLP tasks represents a significant advancement. By effectively combining parametric and non-parametric memories, RAG models offer a robust solution for dynamic knowledge access and generation, setting a new benchmark in the field. The research team from Facebook AI Research, University College London, and New York University has paved the way for future developments in NLP, highlighting the potential for further improvements in dynamic knowledge integration.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 43k+ ML SubReddit | Also, check out our AI Events Platform
The post Combining the Best of Both Worlds: Retrieval-Augmented Generation for Knowledge-Intensive Natural Language Processing appeared first on MarkTechPost.