
As AI technology progresses, models may acquire powerful capabilities that could be misused, resulting in significant risks in high-stakes domains such as autonomy, cybersecurity, biosecurity, and machine learning research and development. The key challenge is to ensure that any advancement in AI systems is developed and deployed safely, aligning with human values and societal goals while preventing potential misuse. Google DeepMind introduced the Frontier Safety Framework to address the future risks posed by advanced AI models, particularly the potential for these models to develop capabilities that could cause severe harm.
Existing protocols for AI safety focus on mitigating risks from existing AI systems. Some of these methods include alignment research, which trains models to act within human values, and implementing responsible AI practices to manage immediate threats. However, these approaches are mainly reactive and address present-day risks, without accounting for the potential future risks from more advanced AI capabilities. In contrast, the Frontier Safety Framework is a proactive set of protocols designed to identify and mitigate future risks from advanced AI models. The framework is exploratory and intended to evolve as more is learned about AI risks and evaluations. It focuses on severe risks resulting from powerful capabilities at the model level, such as exceptional agency or sophisticated cyber capabilities. The Framework aims to align with existing research and Google’s suite of AI responsibility and safety practices, providing a comprehensive approach to preventing any potential threats.
The Frontier Safety Framework comprises three stages of safety for addressing the risks posed by future advanced AI models:
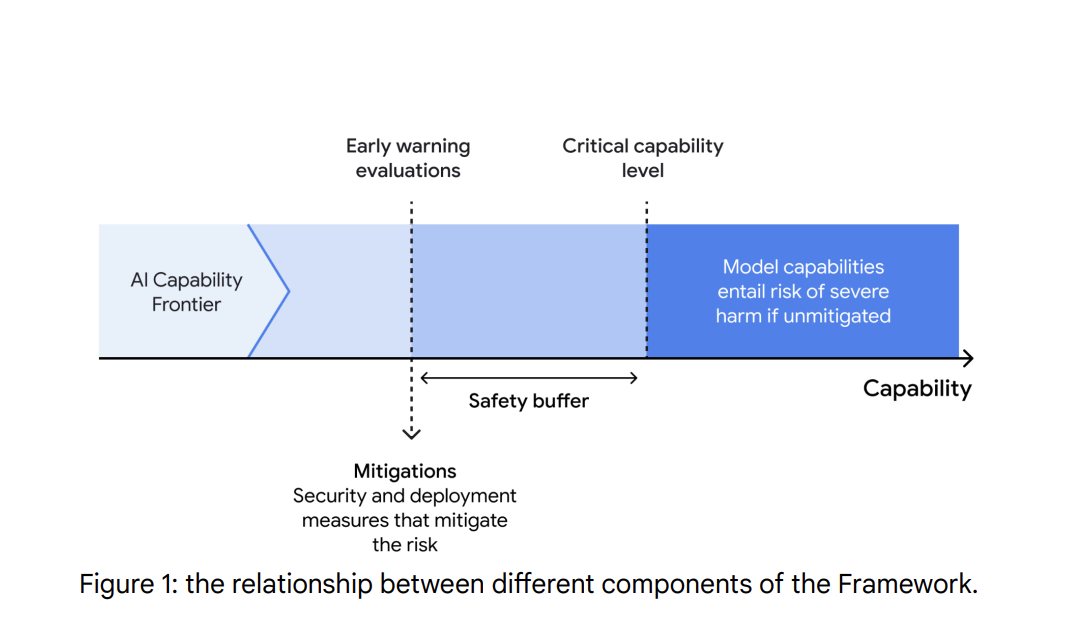
1. Identifying Critical Capability Levels (CCLs): This involves researching potential harm scenarios in high-risk domains and determining the minimal level of capabilities a model must have to cause such harm. By identifying these CCLs, researchers can focus their evaluation and mitigation efforts on the most significant threats. This process includes understanding how threat actors could use advanced AI capabilities in domains such as autonomy, biosecurity, cybersecurity, and machine learning R&D.
2. Evaluating Models for CCLs: The Framework includes the development of “early warning evaluations,” which are suites of model evaluations designed to detect when a model is approaching a CCL. These evaluations provide advance notice before a model reaches a dangerous capability threshold. This proactive monitoring allows for timely interventions. This assesses how close a model is to success at a task it currently fails to do, and predictions about future capabilities.
3. Applying Mitigation Plans: When a model passes the early warning evaluations and reaches a CCL, a mitigation plan is implemented. This plan considers the overall balance of benefits and risks, as well as the intended deployment contexts. Mitigations focus on security (preventing the exfiltration of models) and deployment (preventing misuse of critical capabilities). Higher-level mitigations provide greater protection against misuse or theft of advanced models but may also slow down innovation and reduce accessibility. The Framework highlights various levels of security and deployment mitigations to tailor the strength of the mitigations to each CCL.
The Framework initially focuses on four risk domains: autonomy, biosecurity, cybersecurity, and machine learning R&D. In these domains, the main goal is to assess how threat actors might use advanced capabilities to cause harm.
In conclusion, the Frontier Safety Framework represents a novel and forward-thinking approach to AI safety, shifting from reactive to proactive risk management. It builds on current methods by addressing not just present-day risks but also the potential future dangers posed by advanced AI capabilities. By identifying Critical Capability Levels, evaluating models for these capabilities, and applying tailored mitigation plans, the Framework aims to prevent severe harm from advanced AI models while balancing the need for innovation and accessibility.
The post Google DeepMind Introduces the Frontier Safety Framework: A Set of Protocols Designed to Identify & Mitigate Potential Harms Related to Future AI Systems appeared first on MarkTechPost.