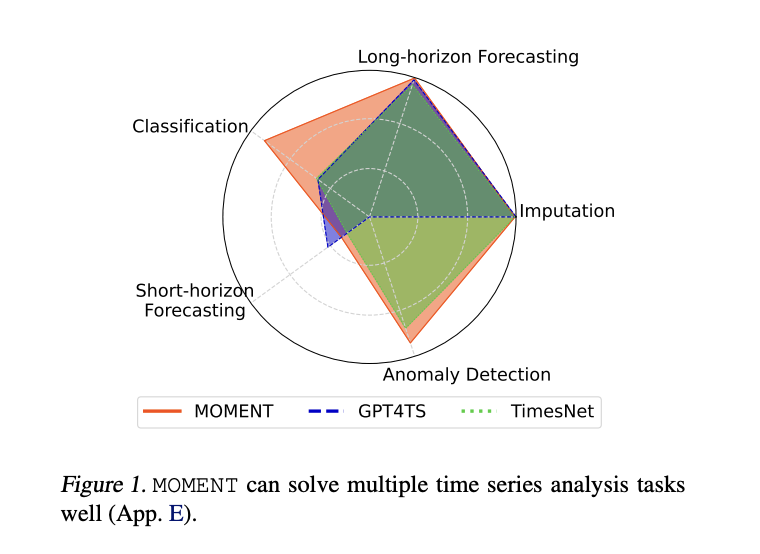
Pre-training large models on time series data faces several challenges: the lack of a comprehensive public time series repository, the complexity of diverse time series characteristics, and the infancy of experimental benchmarks for model evaluation, especially under resource-constrained and minimally supervised scenarios. Despite these hurdles, time series analysis remains vital across applications like weather forecasting, heart rate irregularity detection, and anomaly identification in software deployments. Utilizing pre-trained language, vision, and video models offers promise, though adaptation to time series data specifics is necessary for optimal performance.
Applying transformers to time series analysis presents challenges due to the quadratic growth of the self-attention mechanism with input token size. Treating time series sub-sequences as tokens enhances efficiency and effectiveness in forecasting. Utilizing cross-modal transfer learning from language models, ORCA extends pre-trained models to diverse modalities through align-then-refine fine-tuning. Recent studies have utilized this approach to reprogram language pre-trained transformers for time series analysis, albeit resource-intensive models require substantial memory and computational resources for optimal performance.
Researchers from Carnegie Mellon University and the University of Pennsylvania present MOMENT, an open-source family of foundation models for general-purpose time series analysis. It utilizes the Time series Pile, a diverse collection of public time series, to address time series-specific challenges and enable large-scale multi-dataset pretraining. These high-capacity transformer models are pre-trained using a masked time series prediction task on extensive data from various domains, offering versatility and robustness in tackling diverse time series analysis tasks.
MOMENT begins by assembling a diverse collection of public time series data called the Time Series Pile, combining datasets from various repositories to address the scarcity of comprehensive time-series datasets. These datasets encompass long-horizon forecasting, short-horizon forecasting, classification, and anomaly detection tasks. MOMENT’s architecture involves a transformer encoder and a lightweight reconstruction head pre-trained on a masked time series prediction task. The pre-training setup includes variations of MOMENT corresponding to different sizes of encoders, trained with Adam optimizer and gradient checkpointing for memory optimization. MOMENT is designed for fine-tuning downstream tasks such as forecasting, classification, anomaly detection, and imputation, either end-to-end or with linear probing, depending on the task requirements.
The study compares MOMENT with state-of-the-art deep learning and statistical machine learning models across various tasks, contrary to TimesNet, which mainly focuses on transformer-based approaches. These comparisons are essential for evaluating the practical applicability of the proposed methods. Interestingly, statistical and non-transformer-based methods, such as ARIMA for short-horizon forecasting, N-BEATS for long-horizon forecasting, and k-nearest neighbors for anomaly detection, demonstrate superior performance over many deep learning and transformer-based models.
To recapitulate, this research presents MOMENT, the first open-source family of time series foundation models developed through comprehensive stages of data compilation, model pre-training, and systematic addressing of time series-specific challenges. By utilizing the Time Series Pile and innovative strategies, MOMENT demonstrates high performance in pre-training transformer models of various sizes. Also, the study designs an experimental benchmark for evaluating time series foundation models across multiple practical tasks, particularly emphasizing scenarios with limited computational resources and supervision. MOMENT exhibits effectiveness across various tasks, showcasing superior performance, especially in anomaly detection and classification, attributed to its pre-training. The research also underscores the viability of smaller statistical and shallower deep learning methods across many tasks. Ultimately, the study aims to advance open science by releasing the Time Series Pile, along with code, model weights, and training logs, fostering collaboration and further advancements in time series analysis.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 42k+ ML SubReddit
The post CMU Researchers Propose MOMENT: A Family of Open-Source Machine Learning Foundation Models for General-Purpose Time Series Analysis appeared first on MarkTechPost.