
The capacity of large language models (LLMs) to produce adequate text in various application domains has caused a revolution in natural language creation. These models are essentially two types: 1) Most model weights and data sources are open source. 2) All model-related information is publicly available, including training data, data sampling ratios, training logs, intermediate checkpoints, and assessment methods (Tiny-Llama, OLMo, and StableLM 1.6B). Full access to open language models for the research community is vital for thoroughly investigating these models’ capabilities and limitations and understanding their inherent biases and potential risks. This is necessary despite the continued breakthroughs in the performance of community-released models.
Meet ChuXin 1.6B, a 1.6 billion parameter open-source language model. Various sources, including encyclopedias, online publications, public knowledge databases in English and Chinese, and 2.3 trillion tokens of open-source data, were utilized to train ChuXin. Other open-source projects inspired by this project include OLMo, Tiny-Llama, and StableLM 1.6B. To accomplish an input length of 1 million, the researchers have improved ChuXin’s context length capabilities by continuing pre-training on datasets derived from lengthier texts. The researchers strongly believe that cultivating a broad and diverse ecosystem of these models is the best way to improve their scientific understanding of open language models and drive technology advancements to make them more practical.
For their backbone, the team used LLaMA2, tweaked for about 1.6 billion parameters. The following provides further information regarding the design of ChuXin 1.6B as provided by the researchers.
- Positional embeddings that rotate (RoPE): They use the Rotary Positional Embedding (RoPE) technique to record the associations between sequence parts at different locations.
- Root-mean-squared norm: Pre-normalization, which involves normalizing the input before each sub-layer in the transformer, offers a more consistent training process. This work normalization strategy also uses RMSNorm, which improves training efficiency.
- Focus Cover: Following stableLM’s lead, the team implemented a block-diagonal attention mask architecture that resets attention masks at EOS (End of Sequence) tokens for all packed sequences. This method enhances the model’s performance even further by avoiding the problem of cross-attention during the model’s cool-down phase.
- Generator of tokens: The data was tokenized using the DeepSeek LLM tokenizer, which is based on the tokenizers library’s Byte-Level Byte-Pair Encoding (BBPE). The lexicon contains 102,400 words. The tokenizer’s training was done on a 24-gigabyte multilingual corpus. In addition, this tokenizer can improve the encoding of numerical data by dividing numbers into individual digits.
- Expanded information. The team used SwiGLU as their activation function.
The team’s training process involved utilizing all pre-training datasets obtained from HuggingFace, facilitating easier reproduction of their pre-trained model by others. They optimized their model’s training speed by starting from scratch, using a 4096-context length and several efficient implementations. The researchers began by enhancing the device’s throughput during training with FlashAttention-2. Training was executed using BFloat16 mixed precision, with all-reduce operations preserved in FP32. The research indicates that there is little difference in loss between training on unique data and training on repeated data over several epochs. As part of this effort, they trained for two epochs using 2 trillion (2T) tokens.
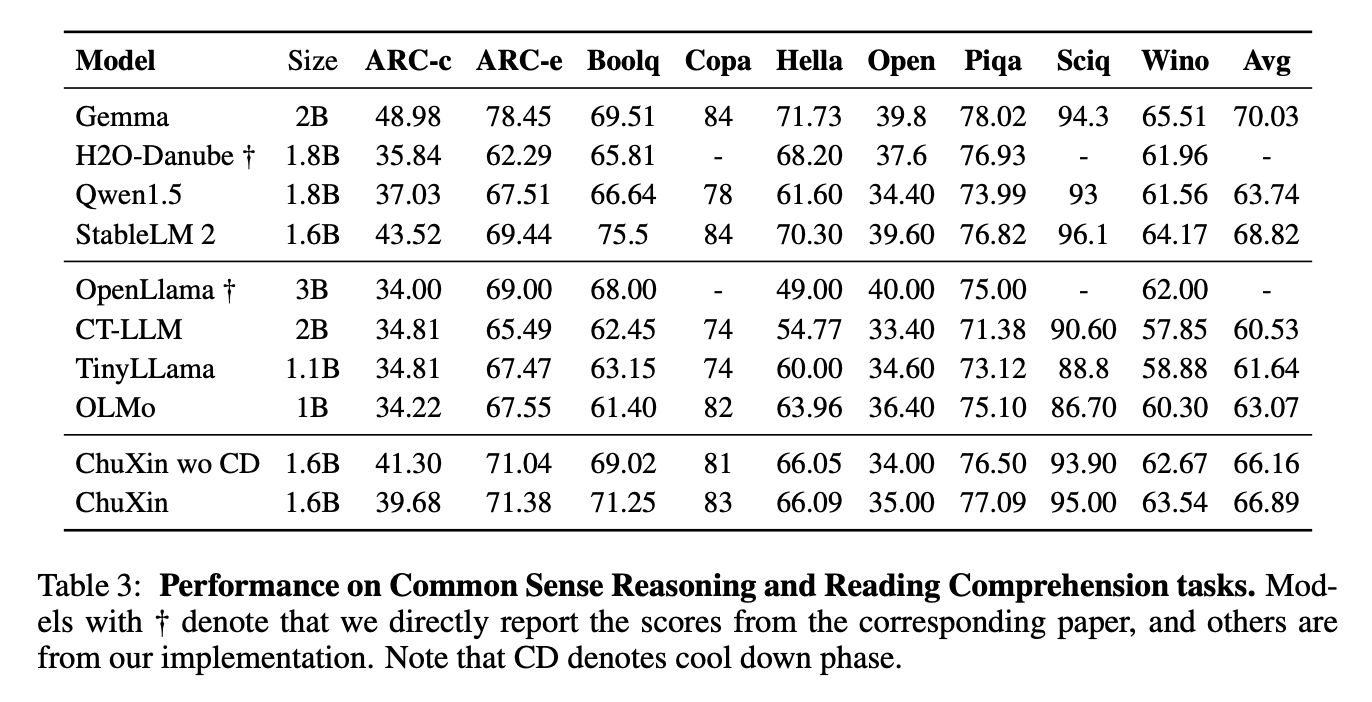
To test the model’s performance on Chinese tasks, the team uses the CMMLU and the C-Eval, two tests for Chinese comprehension and reasoning. They also use the HumanEval to test how well the model can generate code. The pre-training performance of ChuXin was tracked using commonsense reasoning benchmarks. The results demonstrate that except OpenbookQA, ChuXin’s performance on most tasks improves as the quantity of training tokens increases.
In the future, the team envisions providing larger and more advanced models, incorporating features like instruction tweaking and multi-modal integration. They also plan to share the challenges they faced and the solutions they devised while developing ChuXin, aiming to inspire the open-source community and stimulate further progress in language modeling.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 42k+ ML SubReddit
The post ChuXin: A Fully Open-Sourced Language Model with a Size of 1.6 Billion Parameters appeared first on MarkTechPost.