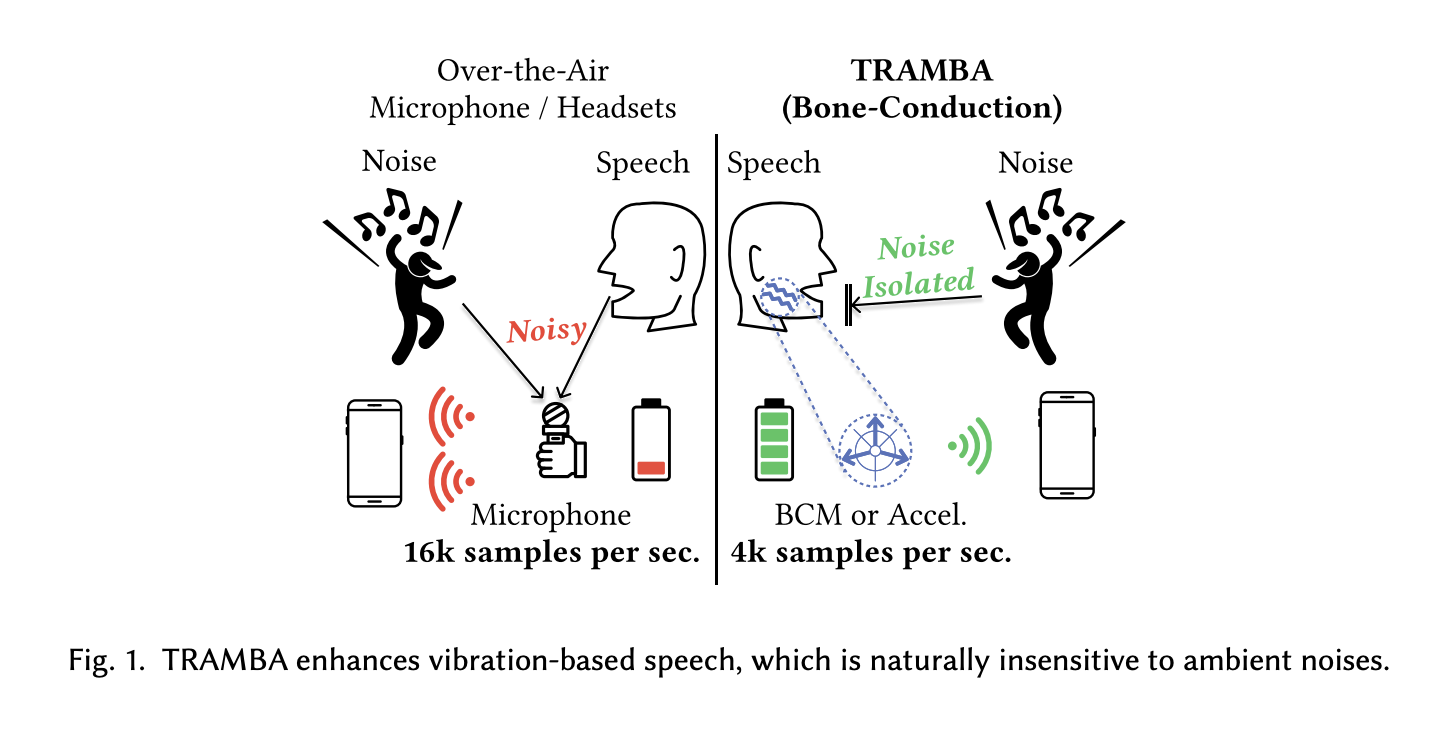
Wearables have transformed human-technology interaction, facilitating continuous health monitoring. The wearables market is projected to surge from 70 billion USD in 2023 to 230 billion USD by 2032, with head-worn devices, including earphones and glasses, experiencing rapid growth (71 billion USD in 2023 to 172 billion USD by 2030). This growth is propelled by the rising significance of wearables, augmented reality (AR), and virtual reality (VR). Head-worn wearables uniquely capture speech signals, traditionally collected by over-the-air (OTA) microphones near or on the head, converting air pressure fluctuations into electrical signals for various applications. However, OTA microphones, typically located near the mouth, easily capture background noise, potentially compromising speech quality, particularly in noisy environments.
Various studies have tackled the challenge of separating speech from background noise through denoising, sound source separation, and speech enhancement techniques. However, this approach is hindered by the model’s inability to anticipate the diverse types of background noises and the prevalence of noisy environments, such as bustling cafeterias or construction sites. Unlike OTA microphones, bone conduction microphones (BCM) placed directly on the head are resilient to ambient noise, detecting vibrations from the skin and skull during speech. Although BCMs offer noise robustness, vibration-based methods suffer from frequency attenuation, affecting speech intelligibility. Some research endeavors explore vibration and bone-conduction super-resolution methods to reconstruct higher frequencies for improved speech quality, yet practical implementation for real-time wearable systems faces challenges. These include the heavy processing demands of state-of-the-art speech super-resolution models like generative adversarial networks (GANs), which require substantial memory and computational resources, resulting in performance gaps compared to smaller footprint methods. Optimization considerations, such as sampling rate and deployment strategies, remain crucial for enhancing real-time system efficiency.
Researchers from Northwestern University and Columbia University introduced TRAMBA, a hybrid transformer, and Mamba architecture for enhancing acoustic and bone conduction speech in mobile and wearable platforms. Previously, adopting bone conduction speech enhancement in such platforms faced challenges due to labor-intensive data collection and performance gaps between models. TRAMBA addresses this by pre-training with widely available audio speech datasets and fine-tuning with a small amount of bone conduction data. It achieves reconstructing intelligible speech using a single wearable accelerometer, demonstrating generalizability across multiple acoustic modalities. Integrated into wearable and mobile platforms, TRAMBA enables real-time speech super-resolution and significant power consumption reduction. This is also the first study to sense intelligible speech using only a single head-worn accelerometer.
At a macro level, TRAMBA architecture integrates a modified U-Net structure with self-attention in the downsampling and upsampling layers, along with Mamba in the narrow bottleneck layer. TRAMBA operates on 512ms windows of single-channel audio and preprocesses acceleration data from an accelerometer. Each downsampling block consists of a 1D convolutional layer with LeakyReLU activations, followed by a robust conditioning layer called Scale-only Attention-based Feature-wise Linear Modulation (SAFiLM). SAFiLM utilizes a multi-head attention mechanism to learn scaling factors for enhancing feature representations. The bottleneck layer employs Mamba, known for its efficient memory usage and attention mechanisms akin to transformers. However, due to gradient vanishing issues, transformers are retained only in the downsampling and upsampling blocks. Residual connections are employed to facilitate gradient flow and optimize deeper networks, enhancing training efficiency.
TRAMBA exhibits superior performance across various metrics and sampling rates compared to other models, including U-Net architectures. Although the Aero GAN method slightly outperforms TRAMBA in the LSD metric, TRAMBA excels in perceptual and noise metrics such as SNR, PESQ, and STOI. This highlights the effectiveness of integrating transformers and Mamba in enhancing local speech formants compared to traditional architectures. Also, transformer and Mamba-based models demonstrate superior performance over state-of-the-art GANs with significantly reduced memory and inference time requirements. Notably, TRAMBA’s efficient processing allows for real-time operation, unlike Aero GAN, which exceeds the window size, making it impractical for real-time applications. Comparisons with the top-performing U-Net architecture (TUNet) are also made.
In conclusion, this study presents TRAMBA, a hybrid architecture combining transformer and Mamba elements for speech super-resolution and enhancement on mobile and wearable platforms. It surpasses existing methods across various acoustic modalities while maintaining a compact memory footprint of only 19.7 MBs, contrasting with GANs requiring at least hundreds of MBs. Integrated into real mobile and head-worn wearable systems, TRAMBA exhibits superior speech quality in noisy environments compared to traditional denoising approaches. Also, it extends battery life by up to 160% by reducing the resolution of audio that needs to be sampled and transmitted. TRAMBA represents a crucial advancement for integrating speech enhancement into practical mobile and wearable platforms.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 41k+ ML SubReddit
The post TRAMBA: A Novel Hybrid Transformer and Mamba-based Architecture for Speech Super Resolution and Enhancement for Mobile and Wearable Platforms appeared first on MarkTechPost.