The emergence of large language models (LLMs) has profoundly influenced the field of biomedicine, providing critical support for synthesizing vast data. These models are instrumental in distilling complex information into understandable and actionable insights. However, they face significant challenges, such as generating incorrect or misleading information. This phenomenon, known as hallucination, can negatively impact the quality and reliability of the information supplied by these models.
Existing methods have begun to employ retrieval-augmented generation, which allows LLMs to update and refine their knowledge based on external data sources. By incorporating relevant information, LLMs can improve their performance, reducing errors and enhancing the utility of their outputs. These retrieval-augmented approaches are crucial for overcoming inherent model limitations, such as static knowledge bases that can lead to outdated information.
Researchers from the University of Minnesota, the University of Illinois at Urbana-Champaign, and Yale University have introduced BiomedRAG, a novel retrieval-augmented generation model tailored specifically for the biomedical domain. This model adopts a simpler design than previous retrieval-augmented LLMs, directly incorporating chunks of relevant information into the model’s input. This approach simplifies retrieval and enhances accuracy by enabling the model to bypass noisy details, particularly in noise-intensive tasks like triple extraction and relation extraction.
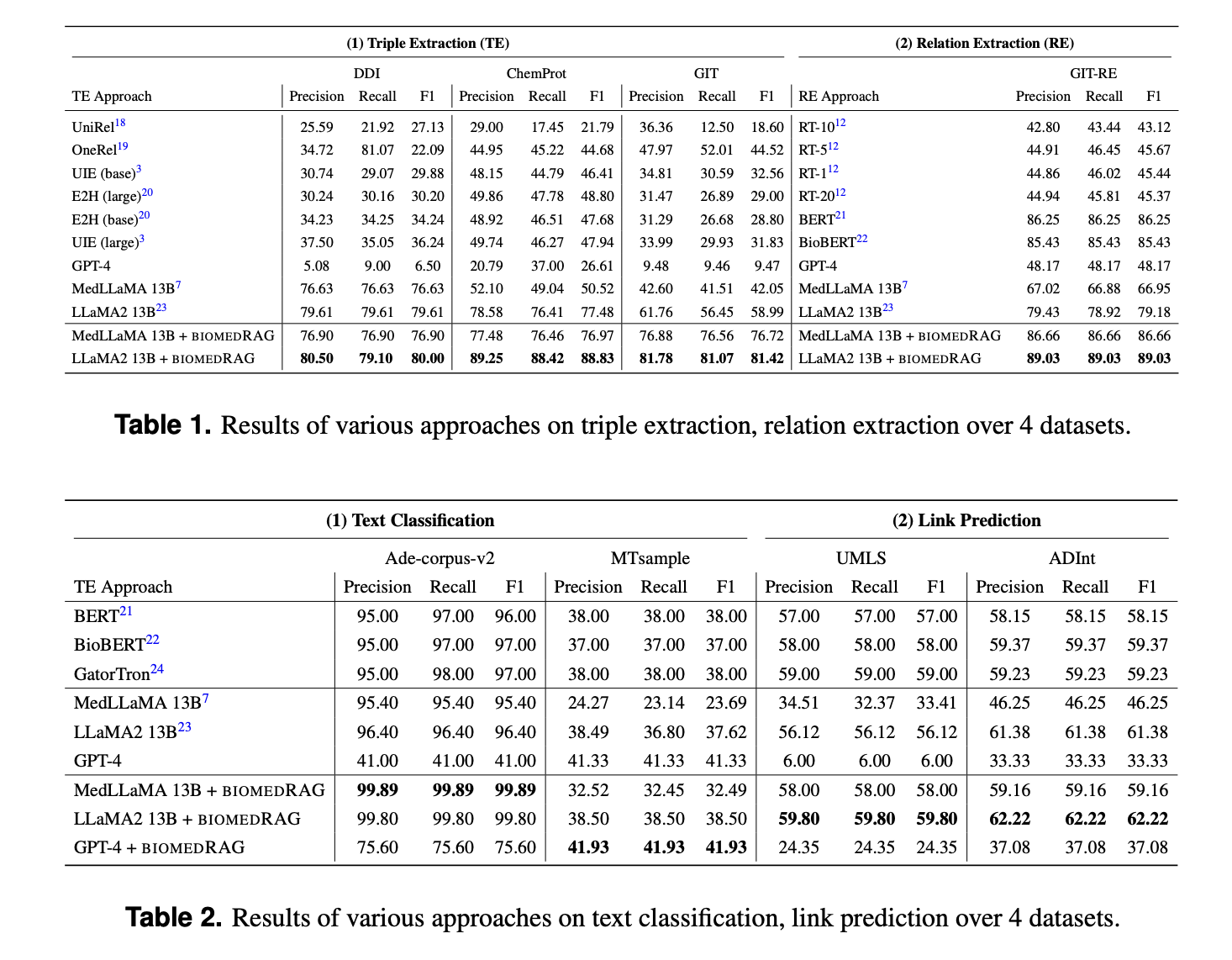
BiomedRAG relies on a tailored chunk scorer to identify and retrieve the most pertinent information from diverse documents. This tailored scorer is designed to align with the LLM’s internal structure, ensuring the retrieved data is highly relevant to the query. The model’s effectiveness is to dynamically integrate the retrieved chunky, significantly improving performance across tasks such as text classification & link prediction. The research demonstrates that the model achieves superior results, with micro-F1 scores reaching 88.83 on the ChemProt corpus for triple extraction, highlighting its capability to construct effective biomedical intervention systems.
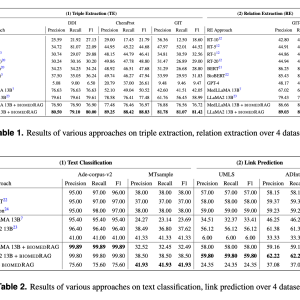
The results of the BiomedRAG approach reveal substantial improvements compared to existing models. Regarding triple extraction, the model outperformed traditional methods by 26.45% in the F1 score on the ChemProt dataset. For relation extraction, the model demonstrated an increase of 9.85% compared to previous methods. In link prediction tasks, BiomedRAG showed an improvement of up to 24.59% in the F1 score on the UMLS dataset. This significant enhancement underscores the potential of retrieval-augmented generation in refining the accuracy and applicability of large language models in biomedicine.
In practical terms, BiomedRAG simplifies the integration of new information into LLMs by eliminating the need for complex mechanisms like cross-attention. Instead, it directly feeds the relevant data into the LLM, ensuring seamless and efficient knowledge integration. This innovative design makes it easily applicable to existing retrieval and language models, enhancing adaptability and efficiency. Moreover, the model’s architecture allows it to supervise the retrieval process, refining its ability to fetch the most relevant data.
BiomedRAG’s performance demonstrates its potential to revolutionize biomedical NLP tasks. For instance, on the task of triple extraction, it achieved micro-F1 scores of 81.42 and 88.83 on the GIT and ChemProt datasets, respectively. Similarly, it significantly improved the performance of large language models like GPT-4 and LLaMA2 13B, elevating their effectiveness in handling complex biomedical data.
In conclusion, BiomedRAG enhances the capabilities of large language models in the biomedical domain. Its innovative retrieval-augmented generation framework addresses the limitations of traditional LLMs, offering a robust solution that improves data accuracy and reliability. The model’s impressive performance across multiple tasks demonstrates its potential to set new standards in biomedical data analysis.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 41k+ ML SubReddit
The post BiomedRAG: Elevating Biomedical Data Analysis with Retrieval-Augmented Generation in Large Language Models appeared first on MarkTechPost.