Generic transport equations, comprising time-dependent partial differential equations (PDEs), delineate the evolution of extensive properties in physical systems, encompassing mass, momentum, and energy. Derived from conservation laws, they underpin comprehension of diverse physical phenomena, from mass diffusion to Navier–Stokes equations. Widely applicable across science and engineering, these equations support high-fidelity simulations vital for addressing design and prediction challenges in varied domains. Conventional approaches to solving these PDEs through discretized methods like finite difference, finite element, and finite volume techniques result in a cubic growth in computation cost concerning domain resolution. Thus, a tenfold augmentation in resolution corresponds to a thousandfold surge in computational expense, presenting a significant hurdle, especially in real-world scenarios.
Physics-informed neural networks (PINNs) utilize PDE residuals in training to learn smooth solutions of known nonlinear PDEs, proving valuable in solving inverse problems. However, each PINN model is trained for a specific PDE instance, necessitating retraining for new instances, which incurs significant training costs. Data-driven models, learning from data alone, offer promise in overcoming computation bottlenecks, but their architecture’s compatibility with generic transport PDEs’ local dependency poses challenges to generalization. Unlike data scoping, domain decomposition methods parallelize computations but share limitations with PINNs, requiring tailored training for specific instances.
Researchers from Carnegie Mellon University present a data scoping technique to augment the generalizability of data-driven models forecasting time-dependent physics properties in generic transport issues by disentangling the expressiveness and local dependency of the neural operator. They solve this problem by suggesting a distributed data scoping approach with linear time complexity, strictly constraining information scope to predict local properties. Numerical experiments across various physics domains demonstrate that their data scoping technique significantly hastens training convergence and enhances the benchmark models’ generalizability in extensive engineering simulations.
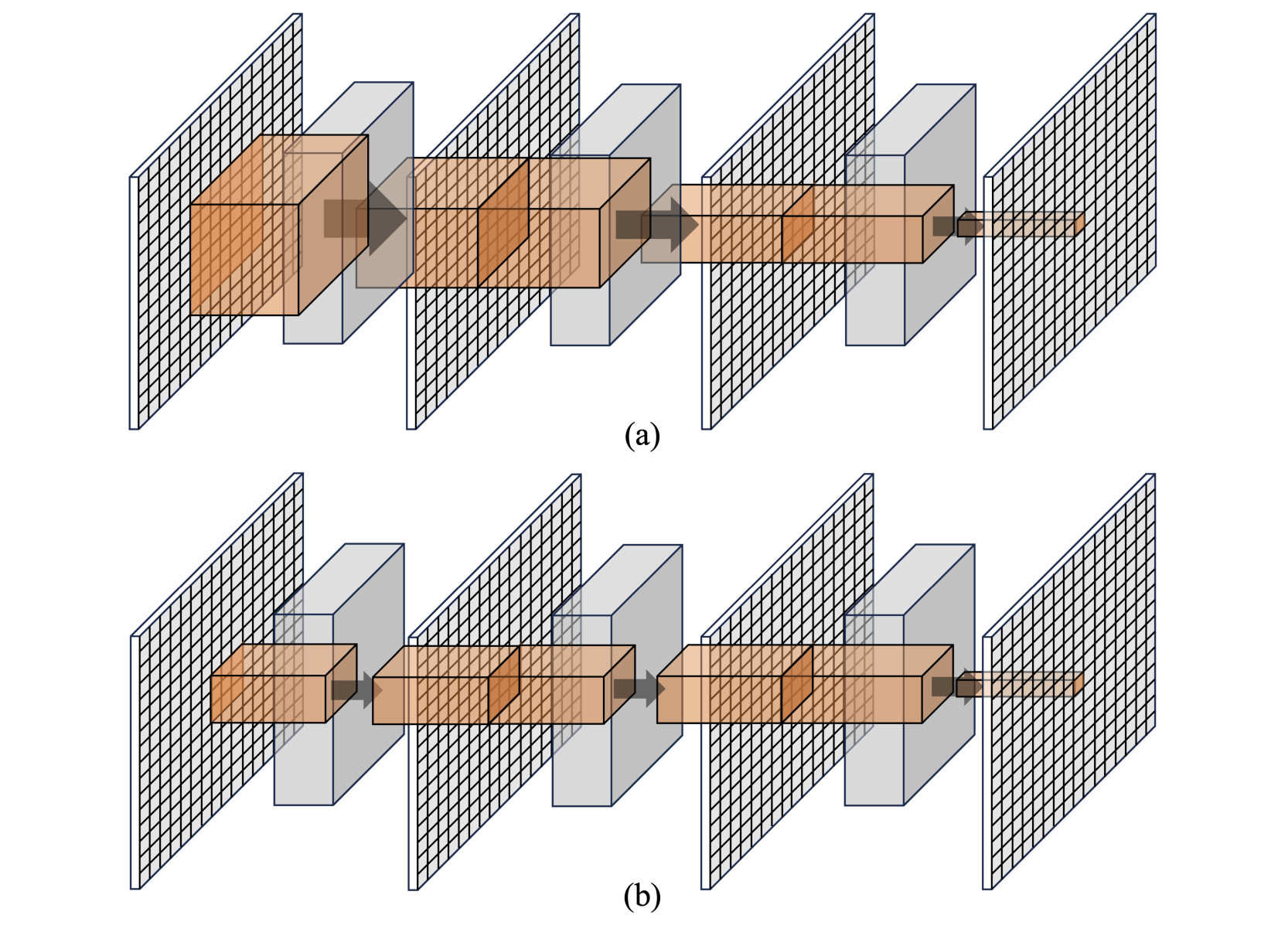
They outline a generic transport system’s domain in d-dimensional space. Introducing a nonlinear operator evolving the system, aiming to approximate it via a neural operator trained using observations from a probability measure. The discretization of functions allows for mesh-independent neural operators in practical computations. The physical information in a generic transport system travels at a limited speed, and they defined the local-dependent operator for the generic transport system. They also clarify how the deep learning structure of neural operators dilutes local dependency. A neural operator comprises layers of linear operators followed by non-linear activations. As layers increase to capture nonlinearity, the local-dependency region expands, potentially conflicting with time-dependent PDEs’ local nature. Instead of limiting the scope of the linear operator to one layer, they directly limit the scope of input data. The data scoping method decomposes the data so that each operator only works on the segmentation.
By validating R2, they confirmed the geometric generalizability of the models. The data scoping method significantly enhances accuracy across all validation data, with CNNs improving by 21.7% on average and FNOs by 38.5%. This supports the assumption that more data doesn’t always yield better results. Specifically, in generic transport problems, information beyond the local-dependent region introduces noise, impeding the ML model’s ability to capture genuine physical patterns. Limiting input scope effectively filters out noise, aiding the model in capturing real physical patterns.
In conclusion, this paper reveals the incompatibility between deep learning architecture and generic transport problems, demonstrating how the local-dependent region expands with layer increase. This leads to input complexity and noise, impacting model convergence and generalizability. Researchers proposed a data-scoping method to address this issue efficiently. Numerical experiments on data from three generic transport PDEs validate its efficacy in accelerating convergence and enhancing model generalizability. While this method is currently applied to structured data, the approach shows promise for extension to unstructured data like graphs, potentially benefiting from parallel computation to expedite prediction integration.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 41k+ ML SubReddit
The post CMU Researchers Propose a Distributed Data Scoping Method: Revealing the Incompatibility between the Deep Learning Architecture and the Generic Transport PDEs appeared first on MarkTechPost.