PyTorch introduced TK-GEMM, an optimized Triton FP8 GEMM kernel, to address the challenge of accelerating FP8 inference for large language models (LLMs) like Llama3 using Triton Kernels. Standard PyTorch execution often struggles with the overhead of launching multiple kernels on the GPU for each operation in LLMs, leading to inefficient inference. The researchers aim to overcome this limitation by leveraging SplitK parallelization to improve performance for Llama3-70B inference problem sizes on Nvidia H100 GPUs.
Current methods for running LLMs, especially with FP8 precision, often suffer from inefficiencies in PyTorch execution due to the overhead associated with launching multiple kernels on the GPU for each operation. The proposed method, Triton Kernels, offers custom kernel optimizations for specific hardware, like Nvidia GPUs. By integrating Triton kernels into PyTorch models via the torch.compile() function, developers can fuse multiple operations into a single kernel launch, reducing overhead and improving performance significantly. Additionally, Triton kernels leverage specialized FP8 Tensor Cores available on Nvidia GPUs, further enhancing computational efficiency compared to standard FP16 cores used by PyTorch’s cuBLAS library.
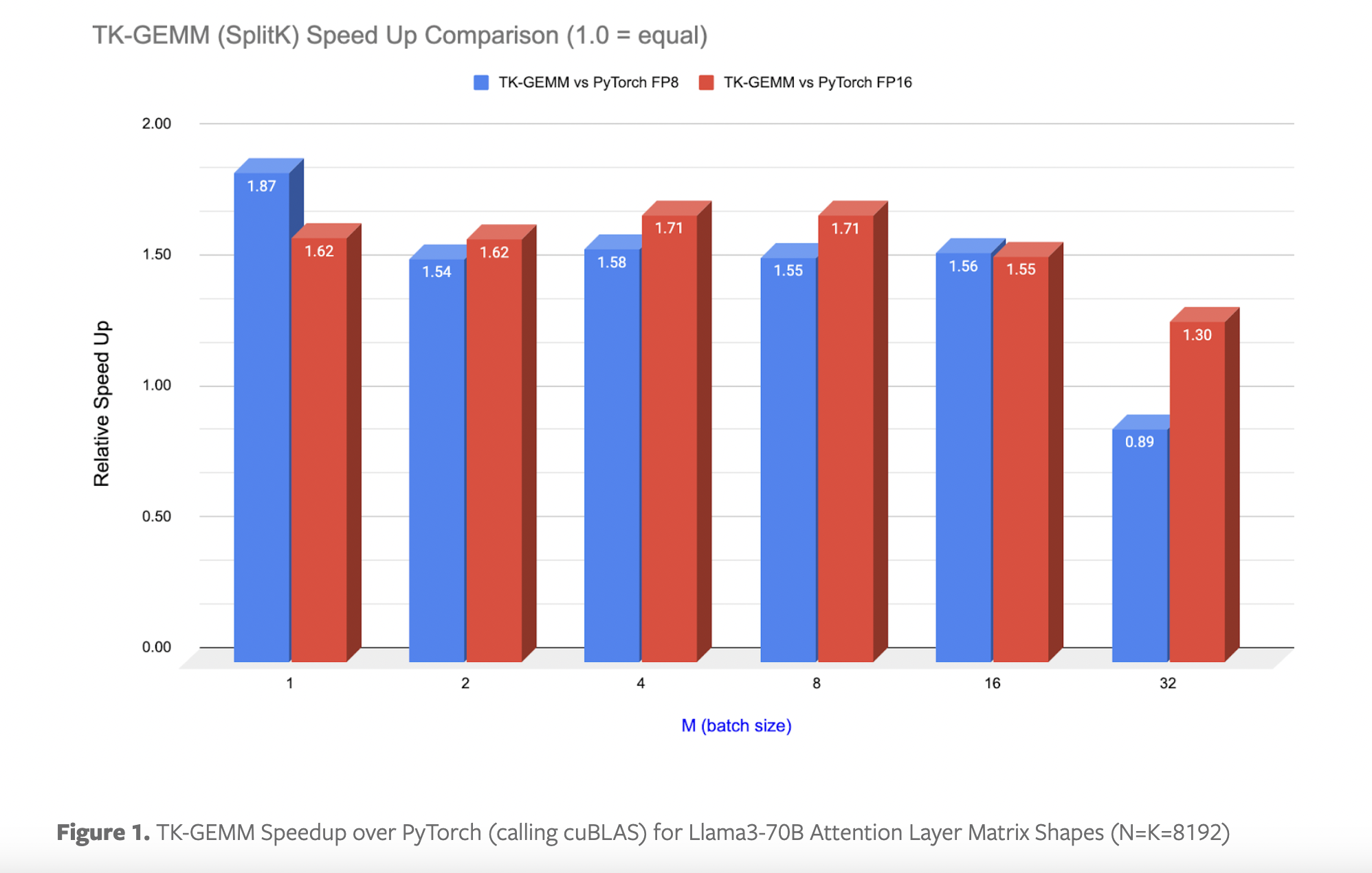
TK-GEMM utilizes SplitK parallelization to improve performance for Llama3-70B by decomposing work along the k dimension and launching additional thread blocks to calculate partial output sums. TK-GEMM achieves finer-grained work decomposition, resulting in significant speedups over the base Triton GEMM implementation. Experimental results show up to a 1.94 times speedup over the base Triton matmul implementation, 1.87 times speedup over cuBLAS FP8, and 1.71 times speedup over cuBLAS FP16 for Llama3-70B inference problem sizes. Moreover, the introduction of CUDA graphs further enhances end-to-end speedup by reducing kernel launch latencies. By creating and instantiating a graph instead of launching multiple kernels, developers can minimize CPU launch overhead and achieve significant performance gains in production settings.
In conclusion, PyTorch presents a novel approach to accelerating FP8 inference for large language models using Triton Kernels. The proposed method overcomes the inefficiencies of standard PyTorch execution and cuBLAS FP8 computations by introducing an optimized TK-GEMM kernel with SplitK parallelization and CUDA graphs for end-to-end speedup. The solution offers significant performance improvements for Llama3-70B inference problem sizes on Nvidia H100 GPUs, making it a promising advancement in the field of deep learning model inference optimization. Overall, the method successfully accelerates FP8 inference for large language models like Llama3 by optimizing kernels and improving performance.
The post PyTorch Researchers Introduce an Optimized Triton FP8 GEMM (General Matrix-Matrix Multiply) Kernel TK-GEMM that Leverages SplitK Parallelization appeared first on MarkTechPost.