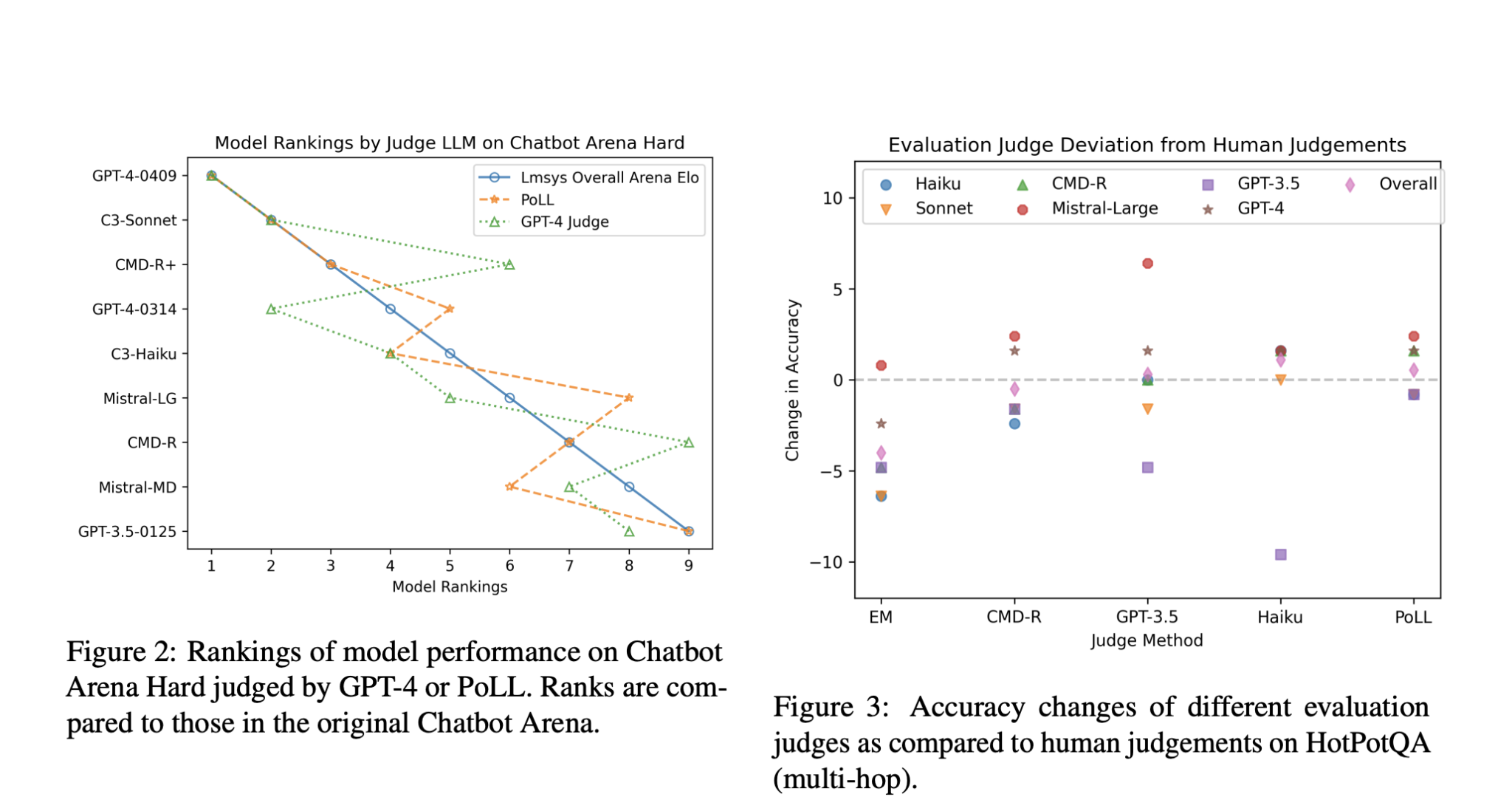
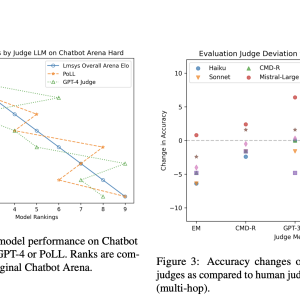
Large Language Models (LLMs) are advancing at a very fast pace in recent times. However, the lack of adequate data to thoroughly verify particular features of these models is one of the main obstacles. An additional layer of complication arises when evaluating the precision and caliber of a model’s free-form text production on its own.
In order to address these issues, a lot of evaluations now use LLMs as judges to score the caliber of results produced by other LLMs. This method often uses one huge model for evaluation, such as the GPT-4. Although this approach has become increasingly popular, it has disadvantages as well, including expensive costs, the possibility of intra-model bias, and the realization that very big models might not be required.
A different strategy has been suggested in response to these problems, which is model evaluation through the use of a Panel of LLM evaluators (PoLL). Instead of depending just on one huge model, this idea uses several smaller LLMs as judges. The PoLL architecture is composed of a variety of smaller LLMs that work together to evaluate the output quality as a whole.
Six different datasets and three different judge settings have been used to illustrate PoLL’s effectiveness. The results have shown that using a PoLL, a collection of several smaller LLMs, performs better than depending just on one large judge. This superiority is explained by the following:
- Decreased Intra-Model Bias: By assembling several smaller models from several model families into a PoLL, the bias that arises from relying solely on a single large model is lessened.
- Cost-Effectiveness: Utilising a PoLL offers a cost-saving advantage of more than seven times when compared to depending on a single large LLM for review.
This unique evaluation framework uses a panel of LLM evaluators to address practical issues of bias and expense while also improving performance. This methodology highlights the possibility of using cooperative evaluations from a heterogeneous group of smaller models to obtain more precise and economical assessments of LLMs.
The researchers have used six different datasets to conduct tests in three different settings, single-hop question answering (QA), multi-hop QA, and Chatbot Arena.
The team has summarized their primary contributions as follows.
- The PoLL Framework has been proposed. Rather than depending on a single large judge, it proposes a unique way to evaluate Large Language Models, which is a Panel of LLM evaluators (PoLL) drawn from several model families.
- The results have shown that utilizing PoLL is much more cost-effective and correlates more closely with human evaluations than using a single large judge like GPT-4.
- The situations in which GPT-4 deviates significantly from the norm in terms of ratings, even when prompts are changed slightly, have also been highlighted.
- The PoLL approach successfully reduces intra-model scoring biases by combining opinions from a varied panel of evaluator models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit
The post This AI Research from Cohere Discusses Model Evaluation Using a Panel of Large Language Models Evaluators (PoLL) appeared first on MarkTechPost.