The success of many reinforcement learning (RL) techniques relies on dense reward functions, but designing them can be difficult due to expertise requirements and trial and error. Sparse rewards, like binary task completion signals, are easier to obtain but pose challenges for RL algorithms, such as exploration. Consequently, the question emerges: Can dense reward functions be learned in a data-driven manner to address these challenges?
Existing research on reward learning often overlooks the importance of reusing rewards for new tasks. In learning reward functions from demonstrations, known as inverse RL, methods like adversarial imitation learning (AIL) have gained traction. Inspired by GANs, AIL employs a policy network and a discriminator to generate and distinguish trajectories, respectively. However, AIL’s rewards are not reusable across tasks, limiting its ability to generalize to new tasks.
Researchers from UC San Diego present Dense reward learning from Stages (DrS), a unique approach to learning reusable rewards by incorporating sparse rewards as a supervision signal instead of the original signal for classifying demonstration and agent trajectories. This involves training a discriminator to classify success and failure trajectories based on binary sparse rewards. Higher rewards are assigned to transitions in success trajectories, and lower rewards are assigned to transitions within failure trajectories, ensuring consistency throughout training. Once training is completed, the rewards become reusable. Expert demonstrations can be included as success trajectories, but they are not mandatory, as only sparse rewards are needed, which is often inherent in task definitions.
DrS model consists of two phases: Reward Learning and Reward Reuse. In the Reward Learning phase, a classifier is trained to differentiate between successful and unsuccessful trajectories using sparse rewards. This classifier serves as a dense reward generator. The Reward Reuse phase applies the learned dense reward to train new RL agents in test tasks. Stage-specific discriminators are trained to provide dense rewards for multi-stage functions for each stage, ensuring effective guidance through task progression.
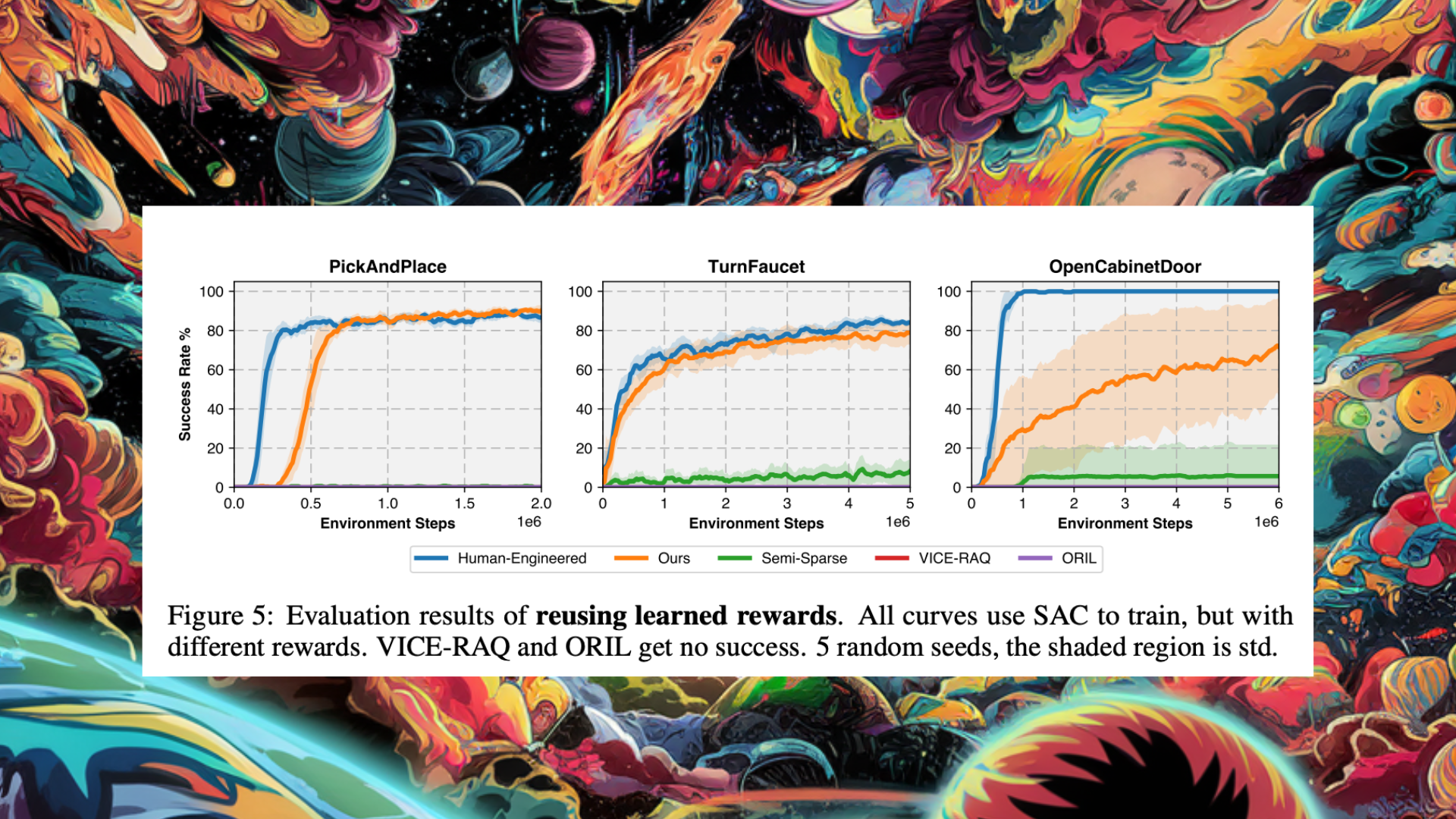
The proposed model was evaluated on three challenging physical manipulation tasks: Pick-and-Place, Turn Faucet, and Open Cabinet Door, each containing various objects. The evaluation focused on the reusability of learned rewards, utilizing non-overlapping training and test sets for each task family. During the Reward Learning phase, rewards were learned by training agents to manipulate training objects, and then these rewards were reused to train agents on test objects in the Reward Reuse phase. The study utilized the Soft Actor-Critic (SAC) algorithm for evaluation. Results demonstrated that the learned rewards outperformed baseline rewards across all task families, sometimes rivaling human-engineered rewards. Semi-sparse rewards exhibited limited success, while other reward learning methods failed to achieve success.
In conclusion, this research presents DrS, a data-driven approach for learning dense reward functions from sparse rewards Evaluated on robotic manipulation tasks, showcasing DrS’s effectiveness in transferring across tasks with varying object geometries. This simplification of the reward design process holds promise for scaling up RL applications in diverse scenarios. However, two main limitations arise with the multi-stage version of the approach. Firstly, the acquisition of task structure knowledge remains unexplored, which could be addressed using large language models or information-theoretic approaches. Secondly, relying on stage indicators may pose challenges in directly training RL agents in real-world settings. However, tactile sensors or visual detection/tracking methods can obtain stage information when necessary.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit
The post Researchers at UC San Diego Propose DrS: A Novel Machine Learning Approach for Learning Reusable Dense Rewards for Multi-Stage Tasks in a Data-Driven Manner appeared first on MarkTechPost.