Computer vision, machine learning, and data analysis across many fields have all seen a surge in the usage of synthetic data in the past few years. Synthetic means to mimic complicated situations that would be challenging, if not impossible, to record in the actual world. Information about individuals, such as patients, citizens, or customers, along with their unique attributes, can be found in tabular records at the personal level. These records are ideal for knowledge discovery tasks and the creation of advanced predictive models to help with decision-making and product development. The privacy implications of tabular information are substantial, though, and they should not be openly disclosed. Data protection regulations are essential for safeguarding individuals’ rights against harmful designs, blackmail, frauds, or discrimination in the event that sensitive data is compromised. While they may slow down scientific development, they are necessary to prevent such harm.
In theory, synthetic data improves upon conventional methods of anonymization by enabling access to tabular datasets while simultaneously shielding people’ identities from prying eyes. In addition to strengthening, balancing, and reducing data bias, synthetic data can improve downstream models. Although we have achieved remarkable success with text and image data, it is still difficult to simulate tabular data, and the privacy and quality of synthetic data can differ greatly based on the algorithms used to create it, the parameters used for optimization, and the assessment methodology. Particularly, it is difficult to compare current models and, by extension, to objectively assess the efficacy of a new algorithm due to the absence of consensus on assessment methodologies.
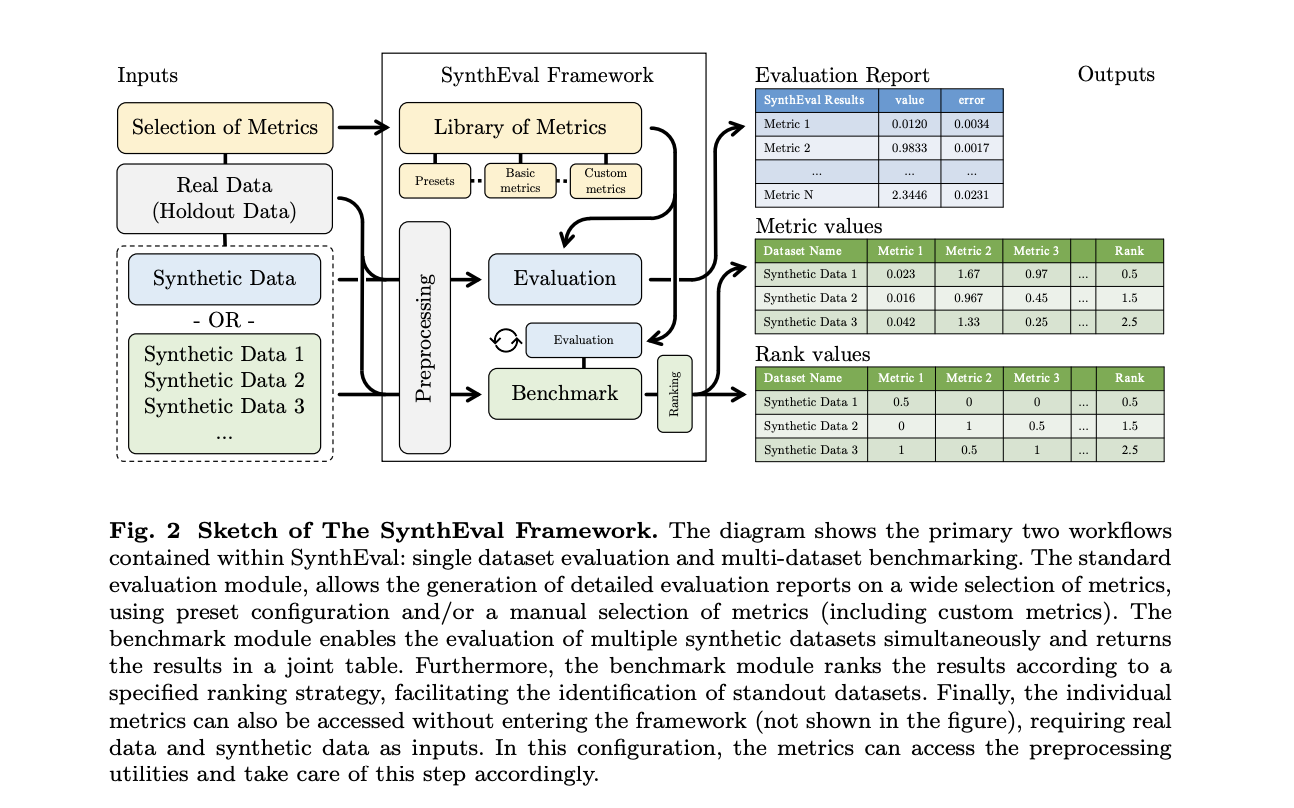
A new study by University of Southern Denmark researchers introduces SynthEval, a novel evaluation framework in the Python package. Its purpose is to facilitate the easy and consistent evaluation of synthetic tabular data. Their motivation comes from the belief that the SynthEval framework may significantly influence the research community and provide a much-needed answer to the evaluation scene. SynthEval incorporates a large collection of metrics that can be used to create user-specific benchmarks. With the press of a button, users can access predefined benchmarks in the presets, and the given components make it easy to construct your own unique settings. Adding custom metrics to benchmarks is a breeze and doesn’t need editing the source code.
A robust shell for accessing a large library of measurements and condensing them into evaluation reports or benchmark configurations is the primary function of SynthEval. The metrics object and the SynthEval interface object are the two primary building blocks that do this. The former specifies how the metric modules are structured and how the SynthEval workflow can access them. Evaluation and benchmark modules are mostly hosted by the SynthEval interface object, which is an object that may be interacted with. If non-numerical values are not supplied, the SynthEval utilities will automatically determine them. They handle any data preprocessing that is required.
Theoretically, there are just two lines of code needed to perform evaluation and benchmarking: creating the SynthEval object and calling either method. The command line interface is another way that SynthEval is made available to you.
The team has given multiple ways to get the metrics to make SynthEval to be as versatile as possible. There are now three preset setups available, or metrics can be selected manually from the library. Bulk selection is also an option. If you specify a file path as a preset, SynthEval will try to load the file. If users use any non-standard setup, a new config file will be saved in JSON format for repeatability.
As an additional useful feature, SynthEval’s benchmark module permits the simultaneous evaluation of multiple synthetic renditions of the same dataset. The outcomes are combined, evaluated internally, and then sent forth. The user can easily and thoroughly assess several datasets using various metrics thanks to this. Generative model skills can be thoroughly evaluated with the use of datasets generated by frameworks like SynthEval. Concerning tabular data, one of the biggest obstacles is maintaining consistency when dealing with fluctuating percentages of numerical and categorical data. This problem has been addressed in earlier evaluation systems in various ways, for example by limiting the metrics that may be used or by limiting the sorts of data that can be accepted. In contrast, SynthEval builds mixed correlation matrix equivalents, uses similarity functions instead of classical distances to account for heterogeneity, and uses empirical approximation of p-values to try to portray the complexities of real data.
The team employs the linear ranking strategy and a bespoke evaluation configuration in SynthEval’s benchmark module. It appears that the generative models have a tough time competing with the baselines. The “random sample” baseline in particular stands out as a formidable opponent, ranking among the top overall and boasting privacy and utility ratings that are not matched anywhere else in the benchmark. The findings make it clear that guaranteeing high utility does not automatically mean good privacy. When it comes to privacy, the most useful datasets—unoptimized BN and CART models—are also among the lowest ranked, posing unacceptable risks of identifying.
The accessible metrics in SynthEval each take dataset heterogeneity into consideration in their own unique manner, which is a limitation in and of itself. Preprocessing has its limits, and future metric integrations must take into account the fact that synthetic data is very heterogeneous in order to adhere to it. The researchers intend to incorporate additional metrics asked for or provided by the community and aim to continue improving the performance of the several algorithms and the framework that is already in place.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit
The post SynthEval: A Novel Open-Source Machine Learning Framework for Detailed Utility and Privacy Evaluation of Tabular Synthetic Data appeared first on MarkTechPost.