It’s time to wrap up our work on data generation using diffusion models. Previously we laid the foundation for this by introducing the concept and providing a quick overview of promising methods. Then, in the second part, we focused on obtaining images along with semantic segmentation maps. In this blog post, we would like to touch on the topic of methods which allow supplementary inputs.
Generating images based on additional conditions
Using diffusion models can lead to creative, imaginary outputs. However, to use this data in real-world business projects, additional information is also required, whether it is the composition of the objects, the size, or even the overall appearance. For this reason, it could be helpful to incorporate another input besides the prompt and feed it to the network, so that it provides guidance on what we expect. At deepsense.ai we experimented with the most popular methods for guided image generation, and we are excited to share our thoughts.
Stable Diffusion Inpainting
Let’s start with a method that originates from the Stable Diffusion paper [1]. The Inpainting pipeline allows you to edit specific parts of an image by providing a mask and a text prompt. This allows the user to erase and replace parts of the picture. The inpainting functionality of Stable Diffusion relies on a modified UNet architecture. This specialized network incorporates five additional input channels: four dedicated to the encoded masked image and one specifically for the mask itself.

Fig. 1 Images generated using a Stable Diffusion Inpainting model with the prompt “a blue robot on a bench”
ControlNet
Sound familiar? Yes, we have mentioned the ControlNet architecture [2] before in our first blog post of this ‘Data generation with diffusion models’ series – you can check it out here [3]. But we are coming back to this topic with more experience and carefully considered conclusions.
ControlNet modifies diffusion models by adding a component ready to be trained with additional inputs. One copy of the encoder is frozen. It carries the wisdom of the original network, gained from studying billions of images. This ensures the preservation of the network’s incredible capabilities. There is no need to train this part of the network. The trainable copy of the encoder learns conditional control so that it is possible to direct outputs with segmentation masks, key points, edges, etc. The outputs from trainable and frozen neural network blocks are connected with a custom layer called “zero convolution” and passed to the remaining parts of the stable diffusion model.

Fig. 2 ControlNet architecture overview. Image from [2].
GLIGEN
A similar concept of freezing the original weights of pre-trained diffusion models can be seen in the implementation of GLIGEN [4] (Grounded-Language-to-Image Generation). Apart from creating a copy of the entire encoder as in ControlNet, it introduces new layers called Gated Self-Attention (GSA), which are responsible for processing grounding input, within the encoder. A key distinction between GLIGEN and ControlNet is the way they deal with conditions and visual features. GLIGEN operates by processing a concatenation of inputs using the Transformer layer. ControlNet adopts the approach of concatenating the condition and visual features. This design choice positions GLIGEN as a more versatile choice. Both architectures exhibit impressive performance based on conditions like edge maps and segmentation maps. However, GLIGEN goes further by demonstrating great results based on conditions such as bounding boxes and reference images.
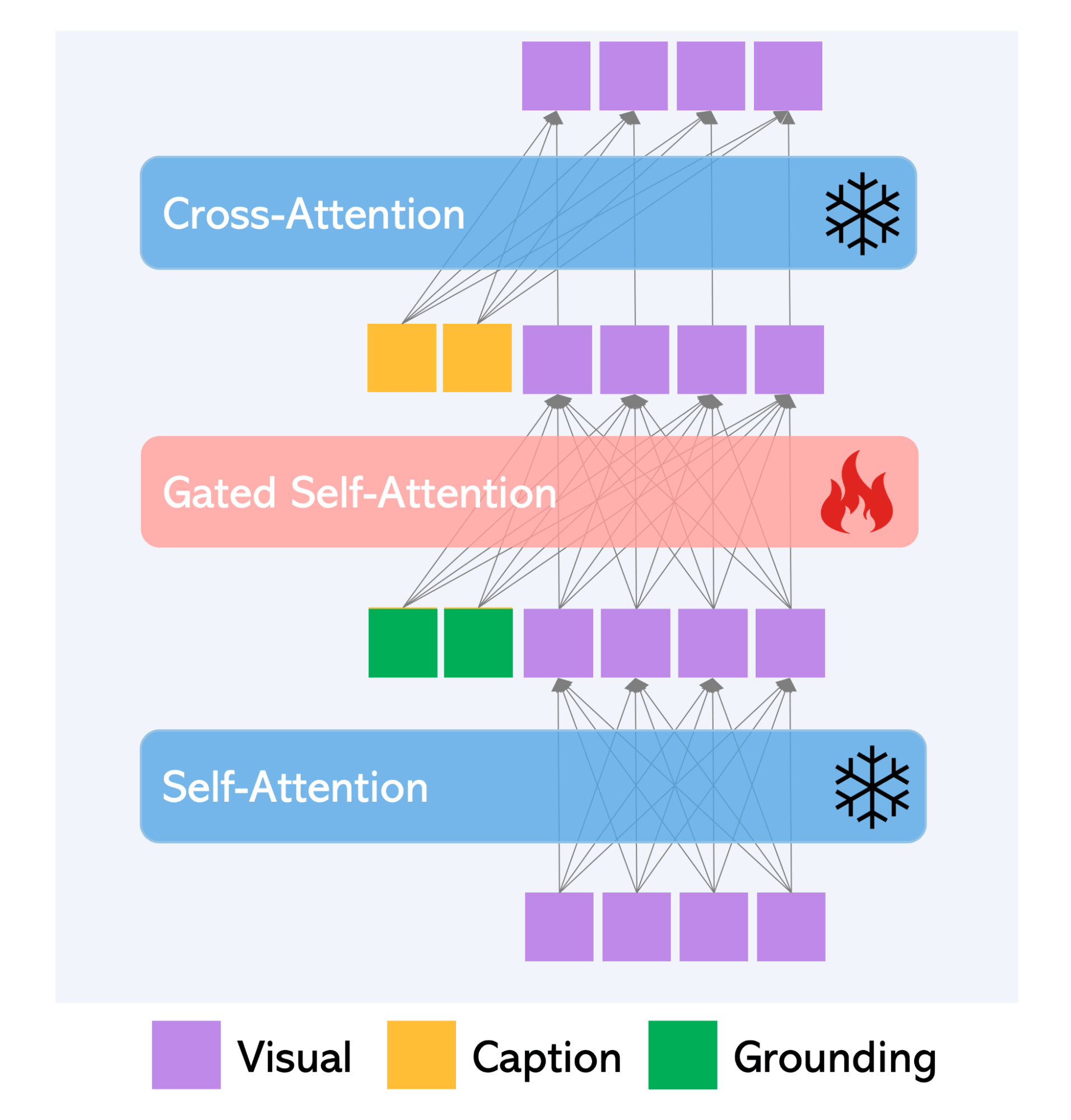
Fig. 3 Gated Self-Attention layer from the GLIGEN architecture. Image from [4].
Training the models
Pre-trained models are undoubtedly impressive, but we often find that they don’t meet the exact needs of business projects. Their inputs are often hyperrealistic, imaginary, and do not fit custom, specialized datasets. One can combat this with prompt engineering, but such a solution is poorly scalable. In this case, a re-training process is necessary.
 |
However, training large diffusion models is not an easy task. First of all, a large dataset is needed. Stable-Diffusion-Inpainting uses LAION which contains 5 billion images. ControlNet, on the other hand, was trained on the ADE20K dataset with over 25,000 images for segmentation and a custom dataset for edges as control images: 3 million edge-image-caption pairs from the internet. In business cases, often only a few thousand images are at their disposal. When it comes to hardware and computational power, GLIGEN was trained with 16 V100 GPUs for 100,000 iterations, and ControlNet for segmentation – with 200 GPU-hours on Nvidia A100 80G.
From a business perspective, it can be impractical to experimentally train such large models due to deadlines and other limitations. Therefore, we have adopted suitable training strategies to overcome these issues, which can lead to satisfactory results for the chosen project.
LoRA to rule them all
In typical text-to-image techniques, where images are generated solely based on text prompts, several methods have been developed to effectively train new concepts. These fine-tuning methods enable swift and efficient learning of new styles or objects, even when the available data is extremely limited. One of these methods is the Low-Rank Adaptation method, commonly referred to as LoRA. At deepsense.ai, we have extensively explored and evaluated this method, uncovering its remarkable flexibility and versatility. You will soon witness its capabilities firsthand. But first, let’s delve into what exactly LoRA is.
Custom models with LoRA
LoRA was initially introduced in the LoRA: Low-Rank Adaptation of Large Language Models paper [5] as a fine-tuning method for Large Language Models like GPT-3. In the paper, it is demonstrated that by fine-tuning only a small portion of the parameters, the fine-tuned model outperformed the pre-trained ones. This technique has since been applied to Stable Diffusion, where it has exhibited remarkable effectiveness in fine-tuning diffusion models as well.
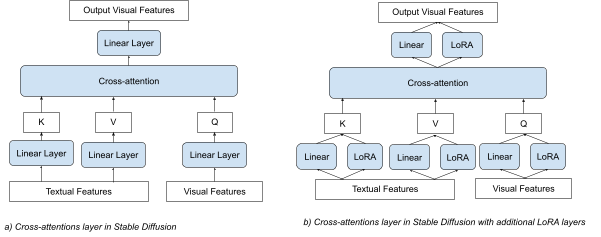
Fig. 5 Comparison of a cross-attention schematic view without and with additional LoRA layers
LoRA achieves this by incorporating additional linear layers into the cross-attention layer. Fig. 5 provides a schematic representation of how it works. In the Stable Diffusion model, the cross-attention layers play a vital role in image generation as they facilitate the interaction between the processed textual prompt and the generated image. During fine-tuning, only the additional layers, which use significantly fewer weights compared to the entire model, are trained. As a result, the training process is quick, and powerful computing resources are not required.
However, the most remarkable aspect of LoRA is its adaptability to pre-trained weights. Despite the existence of various methods built upon Stable Diffusion – ControlNet, GLIGEN, etc. – and each functioning differently, the cross-attention layers connecting a textual prompt with an image maintain a consistent structure and remain a crucial element. As a result, the weights trained using LoRA on one model can be seamlessly transferred to another model, even if these models represent different methods. This interoperability showcases the versatility of LoRA and its ability to facilitate knowledge transfer across diverse model architectures.

Fig. 6 Our proposed process for customizing models using LoRA
Now let’s look at how it works in practice.
Results for Cityscapes
We chose the “Cityscapes” dataset [5] to present the results of the Stable Diffusion model with the LoRA layers.
“Cityscapes” consist of images and corresponding segmentation masks captured in 50 different cities in Germany. The images can be easily recognized by a specific color scheme, a slight degree of blurriness, and the presence of the Mercedes hood. We assumed that specific characteristics of the Cityscapes dataset would be a good example by means of which to present the capabilities of the LoRA method. With just under 3,000 training images, the dataset may appear small for training deep-learning models. Nevertheless, it remains widely utilized for evaluating semantic segmentation techniques.
 |
 |
 |
 |
Stable Diffusion + LoRA
The Stable Diffusion model, trained on the Cityscapes dataset using the LoRA method, demonstrates great fidelity in generating images that mimic the training dataset. Most notably, the training process takes only several dozen minutes on a single GPU card!
 |
 |
 |
 |
Stable Diffusion Inpainting + LoRA
Now we are ready to customize Stable Diffusion models with additional conditions. Let’s begin with inpainting with Stable Diffusion. The model is great for removing objects from scenes. It can also handle the insertion of completely new objects. However, one limitation is that the inpainted objects may not always align seamlessly with the overall style of the image. This disparity is particularly noticeable in the distinctive images from Cityscapes. Fortunately, incorporating LoRA weights trained on Cityscapes into the generation process significantly improves the integration of inpainted objects, resulting in a much smoother blend.
 |
 |
 |
 |
ControlNet + LoRA
The inpainting technique relies on basic binary masks, which can limit its functionality to some extent. However, more advanced techniques such as ControlNet and GLIGEN offer enhanced flexibility, enabling the usage of various additional conditionals. Let’s explore how ControlNet excels in reconstructing Cityscapes data based on segmentation masks. The model processes the segmentation mask and creates a result based on the information therein.
 |
 |
 |
 |
 |
 |
GLIGEN + LoRA
A similar effect can be obtained for the GLIGEN method. Here, let’s focus on conditioning with bounding boxes. Each bounding box has a text prompt associated with it that determines what should be inside. Although GLIGEN works in a completely different way than ControlNet or Stable-Diffusion-Inpainting methods, LoRA also matches it and works really well.
 |
 |
 |
 |
 |
 |
Summary
In this article, we have introduced various approaches to generating data using additional conditioning. Techniques like Stable Diffusion Inpainting, ControlNet, and GLIGEN offer impressive capabilities that can greatly assist in data generation for business projects. However, retraining these methods typically requires time and a relatively large amount of data.
In this blog post, we have presented a method that addresses this challenge by taking advantage of fine-tuning with the Low-Rank Optimization technique. This approach allows for the efficient and seamless adaptation of these methods to specific use cases. By adopting this method, it becomes feasible to enrich business project data with data generated by diffusion models, opening up new possibilities for enhancing data diversity and quality.
References
- “High-Resolution Image Synthesis with Latent Diffusion Models”, Rombach, R., Blattmann, A., Lorenz, D., et al. 2021
- ”Adding Conditional Control to Text-to-Image Diffusion Models” Lvmin Zhang et al., 2023
- “Data generation with diffusion models – part 1”
- “GLIGEN: Open-Set Grounded Text-to-Image Generation” Yuheng Li et al., 2023
- “LoRA: Low-Rank Adaptation of Large Language Models”, Hu, E. J., Shen, Y., Wallis, P., et al., 2021
- Cityscapes dataset
The post Data generation with diffusion models. Part 3: Generating custom data in the blink of an eye appeared first on deepsense.ai.