In this blog post we walk you through our journey creating an LLM-based code writing agent from scratch – fine tuned-for your needs and processes – and we share our experience of how to improve it iteratively.
Introduction
This article is the second part in our series on Coding Agents. The first part provides an in-depth look at existing solutions, exploring their unique attributes and inherent limitations. We recommend starting there for the full picture.
Riding the wave of AutoGPT’s initial popularity surge, we embarked on a mission to uncover its potential for more complex software development projects. Our focus was Data Science, a domain close to our hearts.
Upon realizing the pitfalls of AutoGPT and other Coding Agents, we decided to create an innovative tool of our own. However, it turned out that other powerful solutions had entered the arena in the meantime, nudging us to test all the agents on a common benchmark.
In this article, we invite you on a journey through the evolution of our own AI Agent solutions, from humble beginnings with a basic model to advanced context retrieval. We’ll evaluate both our agents and those currently available to the public, and we’ll also reveal the challenges and limitations we encountered during the development process. Finally, we’ll share the insights and lessons learned from our experience. So join us as we navigate the realm of Coding Agent development, detailing the peaks, the valleys, and all the intricate details in between.
Creating a Data Scientist Agent
All of the agents that we presented in the previous article were mainly evaluated on pure software engineering tasks such as building simple games or writing web servers with Rest API. But when tested on traditional Data Science problems such as image classification, object detection or sentiment analysis, their performance was far from perfect. That’s why we decided to build our own Agent to be better at solving Data Science problems.
From the beginning, we determined the two principal approaches to be explored:
- Approach A: The agent will initially generate the complete plan and subsequently execute it.
- Approach B: The agent will iteratively create a plan for problem-solving.
Each of these approaches has its own set of advantages and disadvantages. In the following sections, you will find a detailed exploration of these aspects.
We utilized the GPT-3.5 and GPT-4 models to engineer our coding agents. We did explore other models, like Claude 2, but their output paled in comparison to the quality of code produced by the OpenAI models.
We evaluated numerous benchmarks, all of which included only initial objective descriptions. Illustrated in Figure 1 is the description of the simplest benchmark among the seven we tested. This particular benchmark will serve as the example for demonstrating how the agents function in the next sections of this blog post.

Figure 1. Initial objective description for one of the benchmarks
Approach A: Generating the plan upfront
In this section, we’ll walk you through how our AI Agent evolved over time. We started with a basic implementation and gradually improved it until we reached a point where the agent could successfully write code and tests, refactor previously written code, and much more.
Baseline
We started with the implementation of a baseline agent to quickly assess whether this path made sense. Our baseline represents one of the simplest approaches you can create. It relies heavily on the underlying models and the initial problem description provided by the user. For example, we asked the models to produce a plan in the form of a valid JSON, only to discover that the models failed to do so, returning JSON that couldn’t be parsed. As a result, the entire program would fail (and you can imagine how challenging it is to carry out a Data Science project without a proper plan!).
We can identify three main stages in the execution of this workflow:
- Problem Definition: The user defines the problem.
- Planning: The planner agent decomposes the main goal into a comprehensive plan consisting of individual tasks. In this iteration, only two task types are permitted: “write code” or “finish”. (See Figure 2)
- Code Generation: Finally, we iterate through the plan, where the CodeWriter agent generates and stores the code into files – we use FileManagementToolkit from LangChain for that purpose, as it allows you to read, create and modify files (learn more here).

Figure 2. Plan produced by the baseline Planner Agent, Source: own study
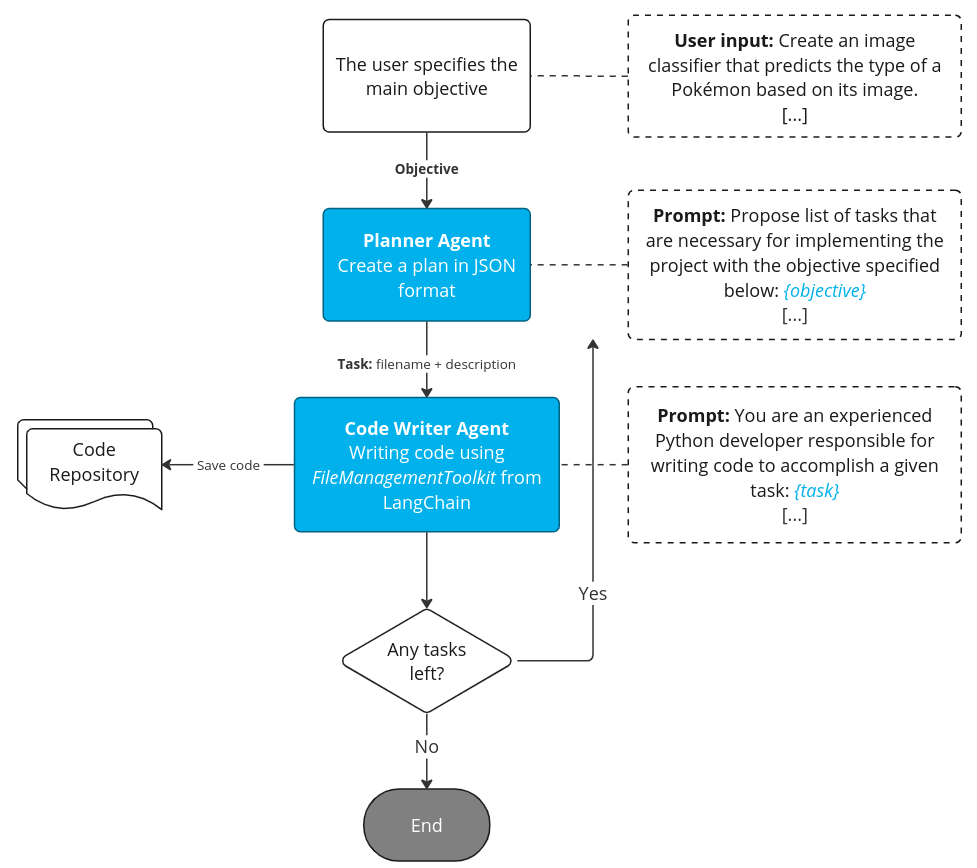
Figure 3. Architecture of the baseline, Source: own study
Problems encountered:
- Tasks are treated as independent, with no sharing of information among them – the model does not get the context and result from previous iterations and as a result it can’t import previously written functions, for example.
- We found out that LangChain’s FileManagementToolkit is unreliable. Agents tend to call the wrong tool quite often.
In the second iteration we solved both of these problems.
Extending the agent to include context knowledge
This approach fixes many of the downsides of our baseline. It generates more files, and they are more complete with fewer obvious issues.
One of the first improvements made over the baseline was the replacement of LangChain’s FileManagementToolkit. The original toolkit often failed to call the appropriate tool, but our implementation addressed this issue by removing the responsibility for determining when to utilize the correct tool from the Agents. In this particular scenario, it was clear when the code needed to be saved, allowing for the implementation of more conventional algorithms.
The second major improvement was the introduction of the context. In this context-aware approach, we started to inject whole files, previously generated by the agent, to the prompt. That allowed the model to use previously implemented functions, e.g., for loading data in the file with the model training code.
Apart from these two improvements, we have also added new roles:
-
- TestWriter – responsible for writing unit tests in pytest based on the context provided.
- CodeRefactorer – responsible for refactoring previously written code and tests (we thought it was a good idea based on how human Software Engineers and Data Scientists usually work – by implementing a rough version first and refactoring it later.)
- AdditionalFilesWriter – projects usually contain more files than just the code: we often have some kind of documentation, reade.me files, files with licenses, or files for package management. This agent was responsible for exactly that – generating the content of these additional files based on the context provided.
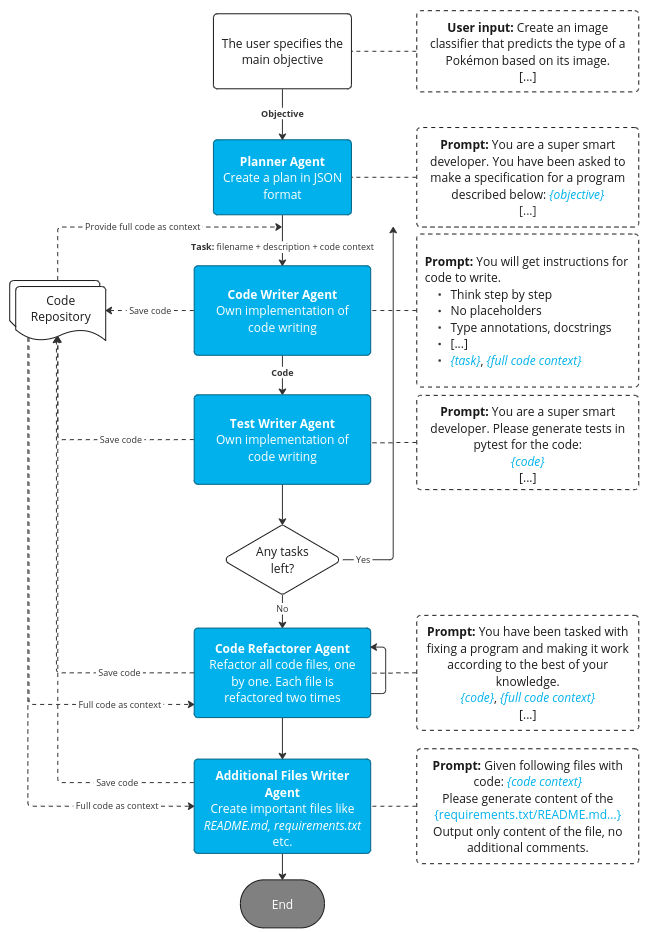
Figure 4. Architecture of context-aware implementation, Source: own study
Problems encountered:
- As we load entire files into the prompt, it quickly exceeds 16k GPT-4/GPT-3.5 context limits.
- The cost of generation is high due to the large size of the prompts.
- Code generation is time-consuming.
- Occasionally the planner returns an invalid JSON which leads to the application crashing.
Improving planning and context retrieval
In the next iteration, we paid more attention to reducing the size of the input context, thus optimizing latency and cost. This time, instead of returning the full files in the context, we decided to divide the files into chunks and return only the useful ones to the model.
Text Embeddings are a popular solution for storing text fragments and comparing them. Each document is represented by its mathematical equivalent (a vector). These vectors can be compared with each other, allowing us to retrieve the three most similar embeddings to our target vector X, for example. Text Embeddings are a popular method, so we encourage you to learn more here or here.
Embeddings are stored in the Vector Store, a database that enables the optimal storage and querying of vectors. We picked FAISS as our personal choice, but there are plenty of options – you can learn more about vector databases here. If you are wondering which database is worth choosing, this link takes you to an article comparing the most popular options.
The question now is how to split the code appropriately so that each document in the vector store contains specific and complete information:
- Storing the entire file as an embedding: this lengthens the context entered into the prompt, which not only adds to the cost but also poses a significant risk of surpassing the prompt length limit. Additionally, we store parts of the code that will not be of any use to Code Writer (e.g., imports from other files).
- Splitting each file using a specific separator or by the number of characters (such as CharacterTextSplitter from the LangChain library): while this can work in plain text, in code it can lead to poor division and incomplete embeddings.
- Our method: export only useful code fragments (functions and classes). In addition, only signatures and docstrings are stored, because the body of such a function itself is of little use – the most important thing is the input parameters and what it returns.
For example, this is what the evaluate.py file looked like before processing:

Figure 5. Function before processing, Source: own study
The following figure illustrates the result of how the function was processed by our custom Code Splitter. As you can see, all the relevant information has been preserved – the model will know how to use this function. By excluding the body, Code Writer will become more cost-effective, eliminating concerns about surpassing the maximum context length. Of course, with more functions, the splitter would produce more chunks.

Figure 6. Function after processing, Source: own study
The case is slightly different with classes. In this case, in addition to the class signature and docstring, we also store the full __init__ method so that Code Writer knows the contents of that class. As for methods, we process them in the same way as functions. This is what it looks like before splitting:

Figure 7. Class before processing, Source: Own study
And this is the final result, after using Code Splitter:

Figure 8. Class after processing, Source: own study
We store the code processed this way in a vector database. The question, given the task, is how to add the relevant code chunks to the context. We have already shown above that we can compare all vectors and return the most similar ones. A prerequisite creating function in Planner retrieves the relevant text, which can be used to query the vector database. It is implemented using the prompt below:

Figure 9. Prompt for prerequisites specification
The prompt should also include information that these prerequisites do not have to be included in each task. For example, this is what the first two created tasks look like – as they are not dependent on others, they do not have any prerequisites:

Figure 10. Initial tasks, Source: own study
The third task already uses elements from the previous files, so we write them out specifically as a list. This way, we can turn each element in the list into an embedding, and then compare it with the code fragments and return the ones we need.

Figure 11. The next task, this time with prerequisites, Source: own study
The full architecture of the third iteration is shown in the image below:
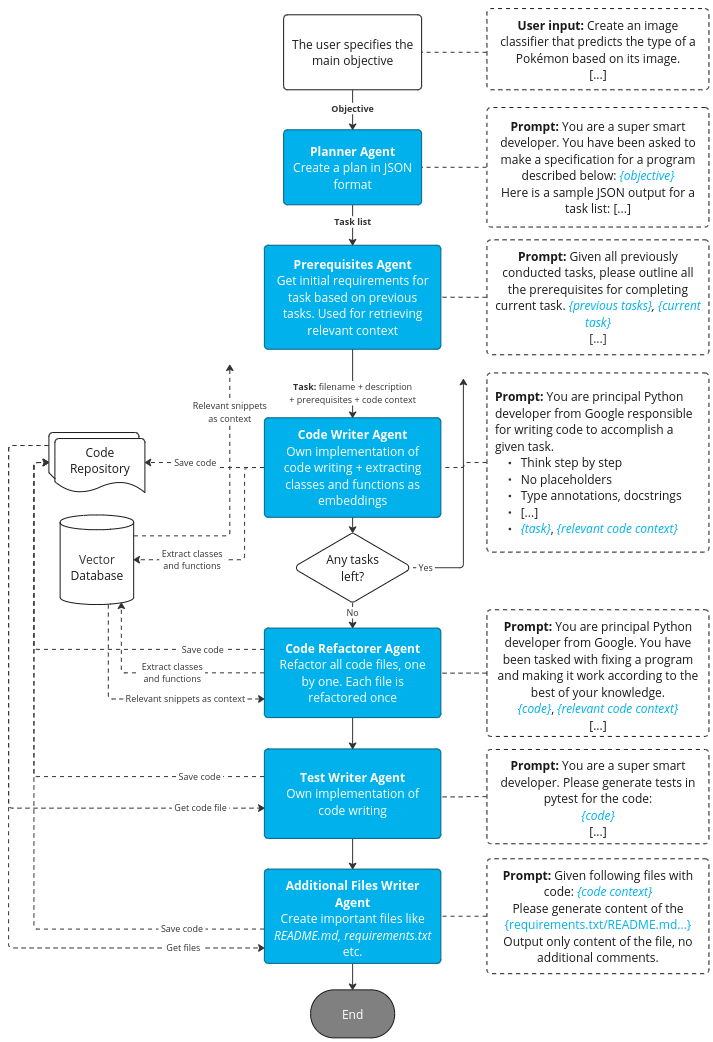
Figure 12. Architecture of the enhanced context solution, Source: own study
Problems encountered:
- Lack of state-of-the-art knowledge – current GPT models were trained on data (and codebases) produced up to and including 2021 – this means that they have no knowledge of any news released after 2021. Two years is a very long time, especially in the IT industry, where technologies are developing at a galloping pace. Code developed by both our agents and others (MetaGPT, GPT Engineer) is therefore outdated.
- Due to the predefined plan, the agent is not flexible and cannot modify the tasks during execution.
The code generated by GPT was fairly good but far from perfect. The code was adequately divided across various files, and everything fit together seamlessly, although occasionally there were difficulties with proper importing. The AI agent maintained compliance with pre-established patterns such as proper docstring formatting, using the specified technologies, and loading data from the correct locations. Launching a project using GPT-4 incurs a cost of slightly over $1.
Approach B: Generating a plan on the fly
This approach is different from the others, because it is inspired by the fact that developers are never able to plan every little step that will be taken when starting a new project. Python scripts are not written once from top to bottom, but instead are constantly changed and improved.
The Agent consists of these main components:
- Problem Definition: The user defines the problem.
- PrepAgent: Takes the project requirements and returns the output in the format:
```- Domain:
- Problem type:
- Model:
- Metrics:
- Dataset to use:
- Raw Dataset location:
```
- ActionAgent: The step repeats in a loop. Based on the history of previous tasks (file structure and content), the agent selects one of the following actions:
- CREATE <file_name> – creates a file
- EDIT <file_name> – modifying an existing file
- DELETE <file_name> – deletes a file
- PEEK <file_name> – allows you to preview the content of the indicated file and stores it in the prompt. Right now, only CSV files have been handled – it previews the first 5 lines.
- FINISH – ends the loop. This option is available to the agent only after several warm-up steps; the number is determined by the parameter.
Secondary agents are also implemented in the main flow:
-
- BobTheBuilderAgent – responsible for managing files
- ScriptKiddieAgent – modifies the content of the selected file
Its architecture is shown in the image below:
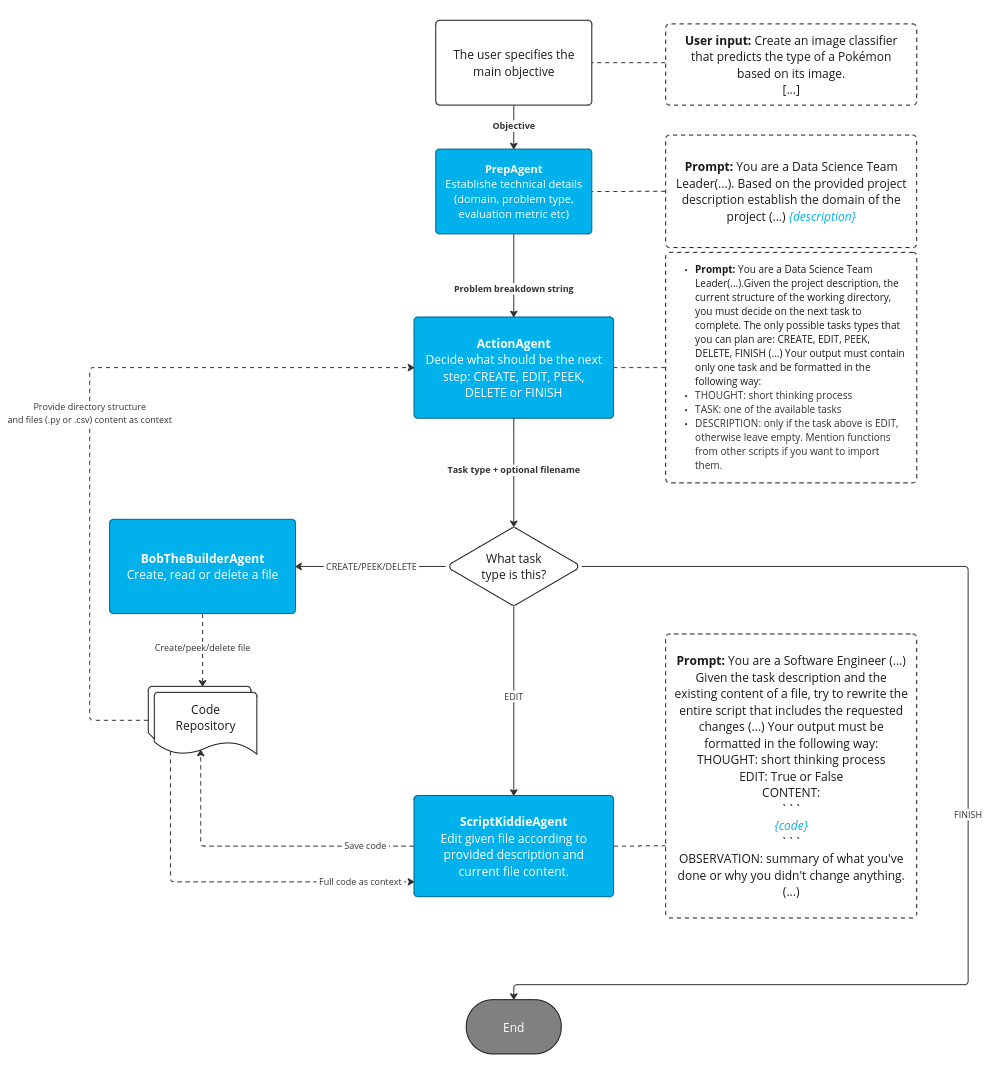
Figure 13. Architecture of Approach B, Source: own study
Encountered problems:
- Once again, a lack of state-of-the-art knowledge
- The possibility of an infinite loop
With such an architecture, it is extremely easy to get stuck in an infinite loop and suspend agent execution. The lack of a plan sometimes causes it to go in strange directions – and the non-determinism of language models encourages this. There are situations when instead of choosing one action from the previously listed ones, an agent decides to create a new one. Once it claimed that he would perform the CONTACT_CLIENT action – so perhaps our next step should be to implement meeting scheduling and face-to-face (or rather matrix-to-face) conversations 😉.
While the lack of advance planning for each task seems to have great potential, it is also much more unstable and requires the consideration of many edge cases. It seems to us that combining the robustness of Approach A with the flexibility of Approach B could yield interesting results.
Evaluation
In order to measure and compare our open-source AI agent and others, we have prepared a set of benchmark tasks. We’ve evaluated coding writing agents over a total of seven small-scale data science projects, which included tasks like:
- Detection of license plates in the image (CV)
- Text summarizer (NLP)
- Spotify genre classification (tabular)
We provided task descriptions and a dataset path as input, which were taken up by the AI agents. These benchmarks measured the ability of the AI models to understand instructions and apply their acquired knowledge to complete a project successfully.
Once the agents completed their tasks, we evaluated the outcomes of the projects they generated. The evaluation was undertaken in two steps:
First, we assessed the quantitative aspects by looking at:
- Whether the code can be executed without any issues/failures.
- How much it cost to generate the code and how long it took.
Then, we conducted a human review to assess:
- The amount and complexity of work required either to run the generated code or fix any issues.
- Whether the solution is reasonable, comprehensive, and solves the issue entirely.
- The code style, to make sure that it adheres to best practices.
A full diagram showing how the evaluation process was conducted is shown below:
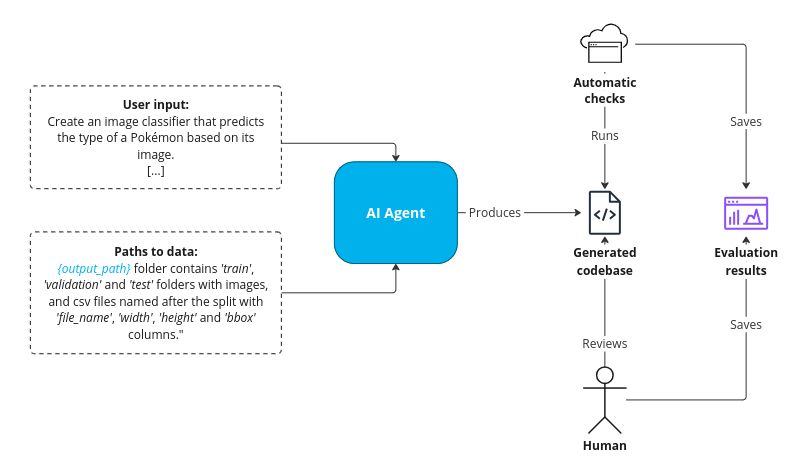
Figure 14. Full evaluation process, Source: own study
The conclusions of our analysis are as follows:
- We identified MetaGPT and the 3rd iteration of our Approach A as the top performers in producing high-quality code, with GPT Engineer falling slightly behind.
- Our solution excels in planning due to effective prompt engineering with few-shot examples. The plan is solid, ensuring the model consistently produces correct JSON, an achievement other solutions may not always guarantee. In some instances, other agents initially failed during the planning stage itself. What is more, creating prerequisites enriches the plan with useful context.
- In terms of cost efficiency, our model didn’t perform as well as both the GPT Engineer and MetaGPT – with a relatively minor difference (well, we are still dealing with very small figures).
Note: This rating demonstrates our team’s findings; however, it’s important to include the caveat that these are based on our criteria and the specific projects that were assessed, so it’s a subjective list. Other trial conditions or assessment criteria could potentially yield different rankings.
Limitations
While AI Agents show surprising autonomy in the coding task performance, they still face several limitations, with some critical ones being:
- Difficulty in selecting the optimal tool for a task, leading to problem-solving failures.
- Existing memory implementations in Agents are not flawless, particularly in providing extensive information to LLM due to limited context length.
- Underlying models, like those from OpenAI, have notable writing code capabilities for generic tasks similar to internet code. However, they struggle when faced with variations or unconventional data formats.
- Moreover, these models often include outdated approaches – at today’s pace of advancement in the IT field, a model trained on data up to and including 2021 (GPT-4) will not be able to offer the best solutions.
- Larger projects may require many iterations leading to substantial LLM usage and consequently high costs. However, we are optimistic that future iterations of open-source models, like LLAMA2 and Gorilla, will be capable of replacing current paid, state-of-the-art LLMs, like GPT4, without any loss in performance.
Lessons learned
We wish to share some of our insights and useful tricks that we learned from our experiments that you may find useful when experimenting with your own AI agents:
- GPT-4 is the best model for code generation, but it is also one of the most expensive ones.
- Specialization beats generalization – try to use specialized roles in your agent: code reviewer, code writer, project manager, etc.
- Models often fail when we ask for output in a specific format (e.g., JSON), as this research paper illustrated well. It helps significantly to use few-shot prompting, that is, to put in an example of the output we require from the LLM.
- Mix different models: for example GPT-4 for code generation but the cheaper GPT-3.5 for other tasks like summarization.
- Structured answers output are better than plain text: some problems are easier/much cheaper when just implemented in code.
- Add monitoring, tracing and logging of execution. LLM-based applications can quickly grow and you may find it hard to debug them without proper tools.
Creating Coding Agents: final thoughts
In this article, we presented the process of creating our unique Coding Agents and compared them to the currently available solutions. Initially, our solution surpassed the available counterparts. However, the dynamic nature of technology soon brought new contenders like MetaGPT, which at the time of writing exceeds the efficiency of all others and also stands as an equal rival for our agent.
Nonetheless, it’s essential to remember that despite its advanced performance, MetaGPT, like all other solutions, has its share of limitations. They excel in tasks with well-defined objectives, such as creating a snake game, compared to tasks lacking clear directions, like developing a generalized classification model for data provided. In the section dedicated to limitations above, we describe some of the issues with these AI agents, but we believe that these challenges will be overcome in the near future, paving the way for a surge in AI Agent-powered applications, particularly those focused on code generation.
Interested in streamlining your projects with AI-based software development? Feel free to reach out to us for comprehensive solutions tailored to your specific needs.
The post Creating your own code writing agent. How to get results fast and avoid the most common pitfalls appeared first on deepsense.ai.