Anthropic Launches Claude Sonnet 4.5 with New Coding and Agentic State-of-the-Art Results
Anthropic has released Claude Sonnet 4.5, setting a new benchmark for end-to-end software engineering and real-world computer use. This update includes significant product enhancements such as Claude Code checkpoints, a native VS Code extension, API memory/context tools, and an Agent SDK that replicates the internal scaffolding used by Anthropic. The pricing remains unchanged from Sonnet 4 at $3 input / $15 output per million tokens.
What’s Actually New?
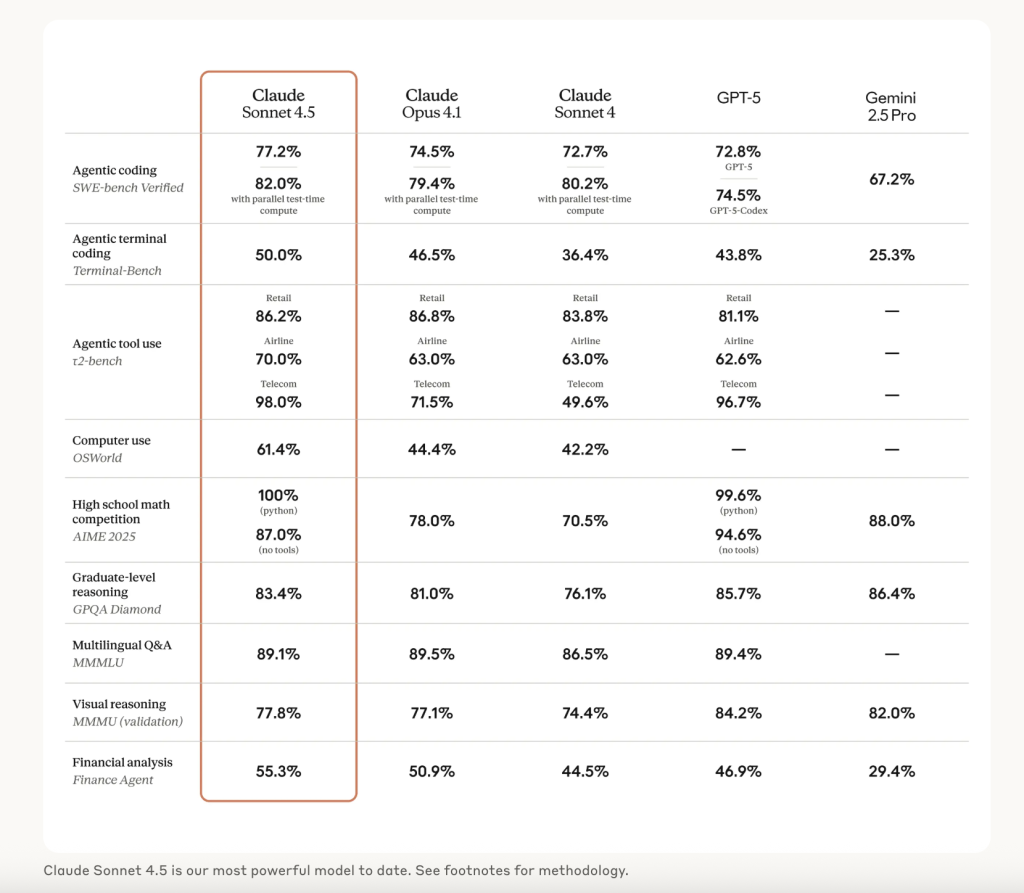
- SWE-bench Verified Record: Anthropic reports a 77.2% accuracy on the 500-problem SWE-bench Verified dataset using a simple two-tool scaffold (bash + file edit), averaged over 10 runs, with no test-time compute and a 200K “thinking” budget. A 1M-context setting reaches 78.2%, and a higher-compute setting with parallel sampling and rejection raises this to 82.0%.
- Computer-use SOTA: On OSWorld-Verified, Sonnet 4.5 leads at 61.4%, up from Sonnet 4’s 42.2%, reflecting improved tool control and UI manipulation for browser and desktop tasks.
- Long-horizon Autonomy: The team observed over 30 hours of uninterrupted focus on multi-step coding tasks, a significant improvement over earlier limits and directly relevant to agent reliability.
- Reasoning/Math: The release notes indicate “substantial gains” across common reasoning and math evaluations, with a safety posture of ASL-3 and enhanced defenses against prompt-injection.
What’s There for Agents?
Sonnet 4.5 addresses the fragile aspects of real agents, including extended planning, memory, and reliable tool orchestration. The Claude Agent SDK exposes production patterns (memory management for long-running tasks, permissioning, sub-agent coordination) rather than just a basic LLM endpoint. This allows teams to replicate the same scaffolding used by Claude Code, now featuring checkpoints, a refreshed terminal, and VS Code integration, to maintain coherence and reversibility in multi-hour jobs.
On measured tasks that simulate “using a computer,” the 19-point jump on OSWorld-Verified is notable, tracking with the model’s ability to navigate, fill spreadsheets, and complete web flows in Anthropic’s browser demo. For enterprises exploring agentic RPA-style work, higher OSWorld scores typically correlate with lower intervention rates during execution.
Where You Can Run It?
- Anthropic API & Apps: Model ID claude-sonnet-4-5; price parity with Sonnet 4. File creation and code execution are now available directly in Claude apps for paid tiers.
- AWS Bedrock: Available via Bedrock with integration paths to AgentCore; AWS highlights long-horizon agent sessions, memory/context features, and operational controls (observability, session isolation).
- Google Cloud Vertex AI: GA on Vertex AI with support for multi-agent orchestration via ADK/Agent Engine, provisioned throughput, 1M-token analysis jobs, and prompt caching.
- GitHub Copilot: Public preview rollout across Copilot Chat (VS Code, web, mobile) and Copilot CLI; organizations can enable via policy, and BYO key is supported in VS Code.
Summary
With a documented 77.2% SWE-bench Verified score under transparent constraints, a 61.4% OSWorld-Verified computer-use lead, and practical updates (checkpoints, SDK, Copilot/Bedrock/Vertex availability), Claude Sonnet 4.5 is designed for long-running, tool-heavy agent workloads rather than short demo prompts. Independent replication will determine the durability of the “best for coding” claim, but the design targets (autonomy, scaffolding, and computer control) align with current production pain points.
Introducing Claude Sonnet 4.5—the best coding model in the world. It is the strongest model for building complex agents, excels at using computers, and shows substantial gains on tests of reasoning and math.