Step by Step Coding Guide to Build a Neural Collaborative Filtering (NCF) Recommendation System with PyTorch
This tutorial will walk you through using PyTorch to implement a Neural Collaborative Filtering (NCF) recommendation system. NCF extends traditional matrix factorisation by using neural networks to model complex user-item interactions.
Introduction
Neural Collaborative Filtering (NCF) is a state-of-the-art approach for building recommendation systems. Unlike traditional collaborative filtering methods that rely on linear models, NCF utilizes to capture non-linear relationships between users and items.
In this tutorial, we&
Prepare and explore the MovieLens dataset
Implement the NCF model architecture
Train the model
Evaluate its performance
Generate recommendations for users
Setup and Environment
First, let& install the necessary libraries and import them:
Copy Code Copied Use a different Browser
!pip install torch numpy pandas matplotlib seaborn scikit-learn tqdm
import os
import numpy as np
import pandas as pd
import torch
import as nn
import as optim
from import Dataset, DataLoader
import t as plt
import seaborn as sns
from _selection import train_test_split
from ocessing import LabelEncoder
from tqdm import tqdm
import random
l_seed(42)
(42)
(42)
device = e(«cuda» if _available() else «cpu»)
print(f»Using device: device»)
Data Loading and Preparation
We& use the MovieLens 100K dataset, which contains 100,000 movie ratings from users:
Copy Code Copied Use a different Browser
!wget -nc
!unzip -q -n
ratings_df = _csv(‘ml-100k/’, sep=’t’, names=[‘user_id’, ‘item_id’, ‘rating’, ‘timestamp’])
movies_df = _csv(‘ml-100k/’, sep=’|’, encoding=’latin-1′,
names=[‘item_id’, ‘title’, ‘release_date’, ‘video_release_date’,
‘IMDb_URL’, ‘unknown’, ‘Action’, ‘Adventure’, ‘Animation’,
‘Children’, ‘Comedy’, ‘Crime’, ‘Documentary’, ‘Drama’, ‘Fantasy’,
‘Film-Noir’, ‘Horror’, ‘Musical’, ‘Mystery’, ‘Romance’, ‘Sci-Fi’,
‘Thriller’, ‘War’, ‘Western’])
print(«Ratings data:»)
print(ratings_())
print(«nMovies data:»)
print(movies_df[[‘item_id’, ‘title’]].head())
print(f»nTotal number of ratings: len(ratings_df)»)
print(f»Number of unique users: ratings_df[‘user_id’].nunique()»)
print(f»Number of unique movies: ratings_df[‘item_id’].nunique()»)
print(f»Rating range: ratings_df[‘rating’].min() to ratings_df[‘rating’].max()»)
print(f»Average rating: ratings_df[‘rating’].mean():.2f»)
e(figsize=(10, 6))
plot(x=’rating’, data=ratings_df)
(‘Distribution of Ratings’)
l(‘Rating’)
l(‘Count’)
()
ratings_df[‘label’] = (ratings_df[‘rating’] >= 4).astype(32)
Data Preparation for NCF
Now, let& prepare the data for our NCF model:
Copy Code Copied Use a different Browser
train_df, test_df = train_test_split(ratings_df, test_size=0.2, random_state=42)
print(f»Training set size: len(train_df)»)
print(f»Test set size: len(test_df)»)
num_users = ratings_df[‘user_id’].max()
num_items = ratings_df[‘item_id’].max()
print(f»Number of users: num_users»)
print(f»Number of items: num_items»)
class NCFDataset(Dataset):
def __init__(self, df):
_ids = r(df[‘user_id’].values, dtype=)
_ids = r(df[‘item_id’].values, dtype=)
s = r(df[‘label’].values, dtype=)
def __len__(self):
return len(_ids)
def __getitem__(self, idx):
return
‘user_id’: _ids[idx],
‘item_id’: _ids[idx],
‘label’: s[idx]
train_dataset = NCFDataset(train_df)
test_dataset = NCFDataset(test_df)
batch_size = 256
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
Model Architecture
Now we& implement the Neural Collaborative Filtering (NCF) model, which combines Generalized Matrix Factorization (GMF) and Multi-Layer Perceptron (MLP) components:
Copy Code Copied Use a different Browser
class NCF(nn.Module):
def __init__(self, num_users, num_items, embedding_dim=32, mlp_layers=[64, 32, 16]):
super(NCF, self).__init__()
_embedding_gmf = nn.Embedding(num_users + 1, embedding_dim)
_embedding_gmf = nn.Embedding(num_items + 1, embedding_dim)
_embedding_mlp = nn.Embedding(num_users + 1, embedding_dim)
_embedding_mlp = nn.Embedding(num_items + 1, embedding_dim)
mlp_input_dim = 2 * embedding_dim
_layers = nn.ModuleList()
for idx, layer_size in enumerate(mlp_layers):
if idx == 0:
_d(nn.Linear(mlp_input_dim, layer_size))
else:
_d(nn.Linear(mlp_layers[idx-1], layer_size))
_d(nn.ReLU())
t_layer = nn.Linear(embedding_dim + mlp_layers[-1], 1)
id = nn.Sigmoid()
self._init_weights()
def _init_weights(self):
for m in es():
if isinstance(m, nn.Embedding):
l_(t, mean=0.0, std=0.01)
elif isinstance(m, nn.Linear):
ng_uniform_(t)
if is not None:
_()
def forward(self, user_ids, item_ids):
user_embedding_gmf = _embedding_gmf(user_ids)
item_embedding_gmf = _embedding_gmf(item_ids)
gmf_vector = user_embedding_gmf * item_embedding_gmf
user_embedding_mlp = _embedding_mlp(user_ids)
item_embedding_mlp = _embedding_mlp(item_ids)
mlp_vector = ([user_embedding_mlp, item_embedding_mlp], dim=-1)
for layer in _layers:
mlp_vector = layer(mlp_vector)
concat_vector = ([gmf_vector, mlp_vector], dim=-1)
prediction = id(t_layer(concat_vector)).squeeze()
return prediction
embedding_dim = 32
mlp_layers = [64, 32, 16]
model = NCF(num_users, num_items, embedding_dim, mlp_layers).to(device)
print(model)
Training the Model
Let& train our NCF model:
Copy Code Copied Use a different Browser
criterion = nn.BCELoss()
optimizer = optim.Adam(eters(), lr=0.001, weight_decay=1e-5)
def train_epoch(model, data_loader, criterion, optimizer, device):
()
total_loss = 0
for batch in tqdm(data_loader, desc=»Training»):
user_ids = batch[‘user_id’].to(device)
item_ids = batch[‘item_id’].to(device)
labels = batch[‘label’].to(device)
_grad()
outputs = model(user_ids, item_ids)
loss = criterion(outputs, labels)
ard()
()
total_loss += ()
return total_loss / len(data_loader)
def evaluate(model, data_loader, criterion, device):
()
total_loss = 0
predictions = []
true_labels = []
with _grad():
for batch in tqdm(data_loader, desc=»Evaluating»):
user_ids = batch[‘user_id’].to(device)
item_ids = batch[‘item_id’].to(device)
labels = batch[‘label’].to(device)
outputs = model(user_ids, item_ids)
loss = criterion(outputs, labels)
total_loss += ()
d(().numpy())
true_d(().numpy())
from cs import roc_auc_score, average_precision_score
auc = roc_auc_score(true_labels, predictions)
ap = average_precision_score(true_labels, predictions)
return
‘loss’: total_loss / len(data_loader),
‘auc’: auc,
‘ap’: ap
num_epochs = 10
history = ‘train_loss’: [], ‘val_loss’: [], ‘val_auc’: [], ‘val_ap’: []
for epoch in range(num_epochs):
train_loss = train_epoch(model, train_loader, criterion, optimizer, device)
eval_metrics = evaluate(model, test_loader, criterion, device)
history[‘train_loss’].append(train_loss)
history[‘val_loss’].append(eval_metrics[‘loss’])
history[‘val_auc’].append(eval_metrics[‘auc’])
history[‘val_ap’].append(eval_metrics[‘ap’])
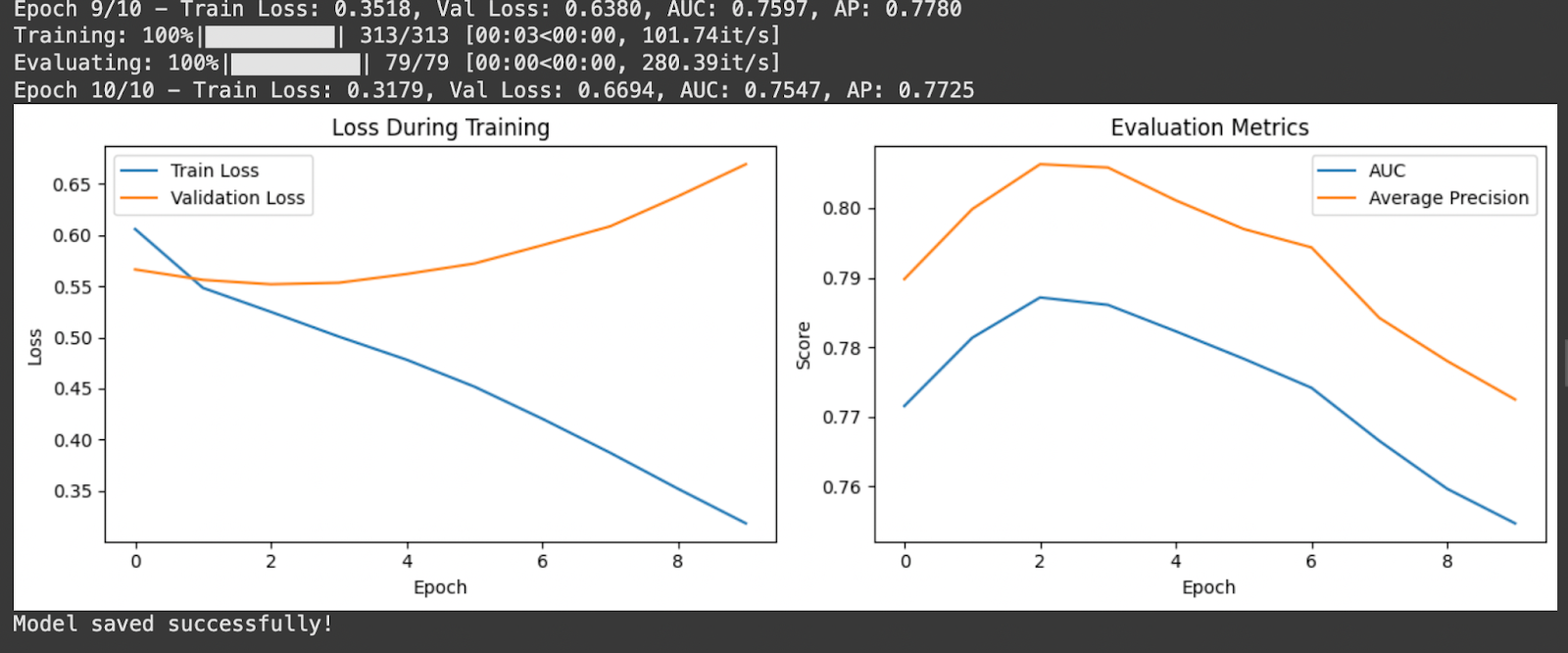
print(f»Epoch epoch+1/num_epochs — »
f»Train Loss: train_loss:.4f, »
f»Val Loss: eval_metrics[‘loss’]:.4f, »
f»AUC: eval_metrics[‘auc’]:.4f, »
f»AP: eval_metrics[‘ap’]:.4f»)
e(figsize=(12, 4))
ot(1, 2, 1)
(history[‘train_loss’], label=’Train Loss’)
(history[‘val_loss’], label=’Validation Loss’)
(‘Loss During Training’)
l(‘Epoch’)
l(‘Loss’)
d()
ot(1, 2, 2)
(history[‘val_auc’], label=’AUC’)
(history[‘val_ap’], label=’Average Precision’)
(‘Evaluation Metrics’)
l(‘Epoch’)
l(‘Score’)
d()
_layout()
()
(_dict(), ‘ncf_’)
print(«Model saved successfully!»)
Generating Recommendations
Now let& create a function to generate recommendations for users:
Copy Code Copied Use a different Browser
def generate_recommendations(model, user_id, n=10):
()
user_ids = r([user_id] * num_items, dtype=).to(device)
item_ids = r(range(1, num_items + 1), dtype=).to(device)
with _grad():
predictions = model(user_ids, item_ids).cpu().numpy()
items_df = pd.DataFrame(
‘item_id’: range(1, num_items + 1),
‘score’: predictions
)
user_rated_items = set(ratings_df[ratings_df[‘user_id’] == user_id]
[‘item_id’].values)
items_df = items_df[~items_df[‘item_id’].isin(user_rated_items)]
top_n_items = items__values(‘score’, ascending=False).head(n)
recommendations = (top_n_items, movies_df[[‘item_id’, ‘title’]], on=’item_id’)
return recommendations[[‘item_id’, ‘title’, ‘score’]]
test_users = [1, 42, 100]
for user_id in test_users:
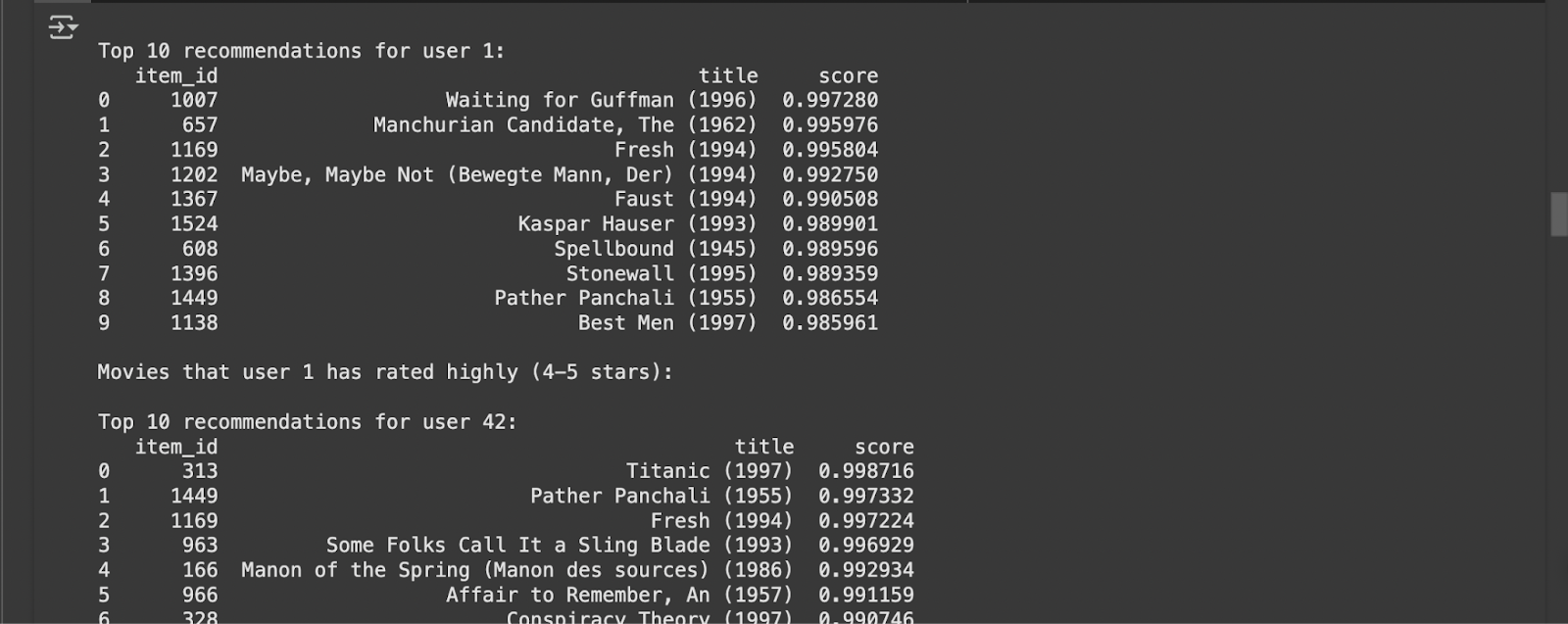
print(f»nTop 10 recommendations for user user_id:»)
recommendations = generate_recommendations(model, user_id, n=10)
print(recommendations)
print(f»nMovies that user user_id has rated highly (4-5 stars):»)
user_liked = ratings_df[(ratings_df[‘user_id’] == user_id) & (ratings_df[‘rating’] >= 4)]
user_liked = (user_liked, movies_df[[‘item_id’, ‘title’]], on=’item_id’)
user_liked[[‘item_id’, ‘title’, ‘rating’]]
Evaluating the Model Further
Let& evaluate our model further by computing some additional metrics:
Copy Code Copied Use a different Browser
def evaluate_model_with_metrics(model, test_loader, device):
()
predictions = []
true_labels = []
with _grad():
for batch in tqdm(test_loader, desc=»Evaluating»):
user_ids = batch[‘user_id’].to(device)
item_ids = batch[‘item_id’].to(device)
labels = batch[‘label’].to(device)
outputs = model(user_ids, item_ids)
d(().numpy())
true_d(().numpy())
from cs import roc_auc_score, average_precision_score, precision_recall_curve, accuracy_score
binary_preds = [1 if p >= 0.5 else 0 for p in predictions]
auc = roc_auc_score(true_labels, predictions)
ap = average_precision_score(true_labels, predictions)
accuracy = accuracy_score(true_labels, binary_preds)
precision, recall, thresholds = precision_recall_curve(true_labels, predictions)
e(figsize=(10, 6))
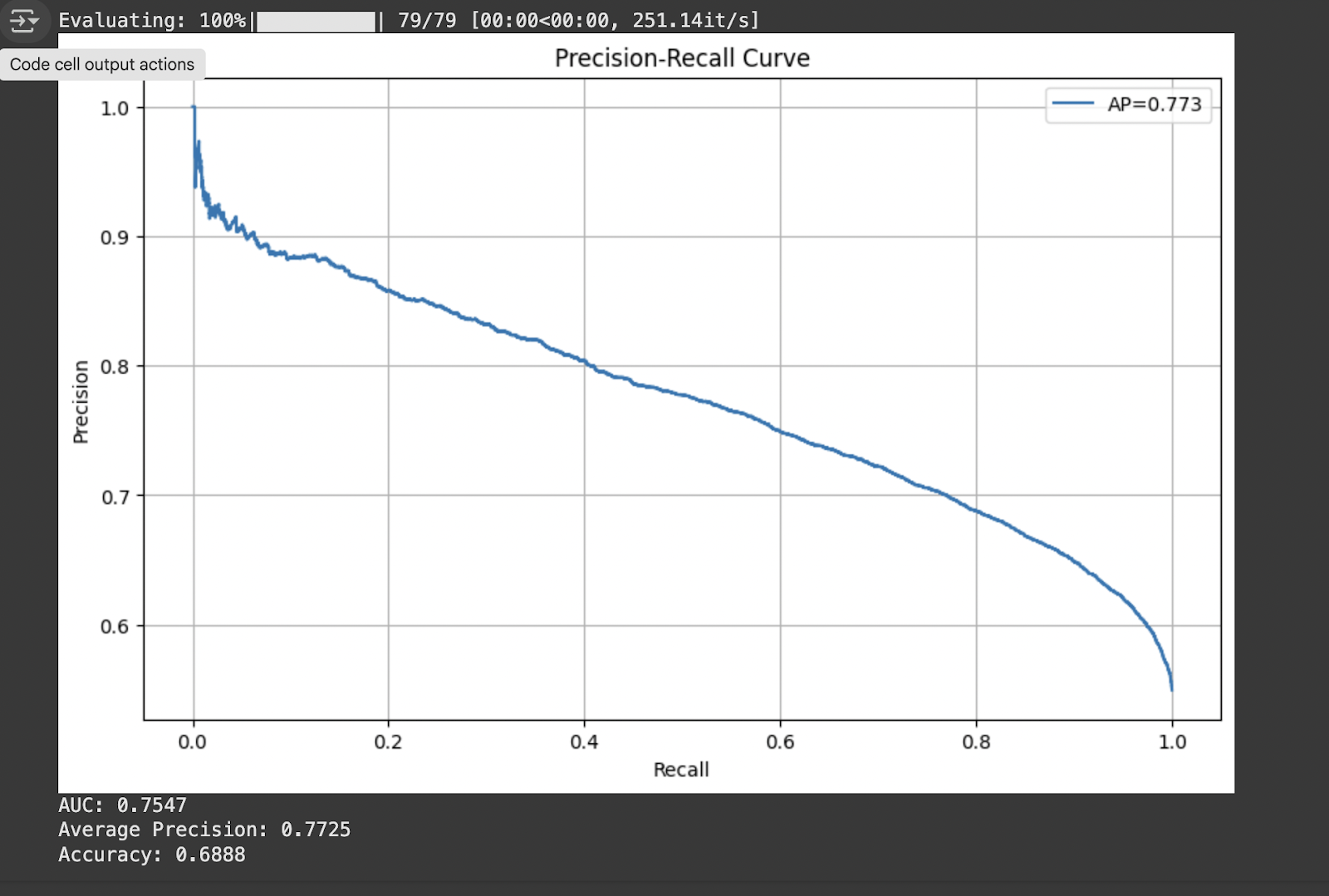
(recall, precision, label=f’AP=ap:.3f’)
l(‘Recall’)
l(‘Precision’)
(‘Precision-Recall Curve’)
d()
(True)
()
return
‘auc’: auc,
‘ap’: ap,
‘accuracy’: accuracy
metrics = evaluate_model_with_metrics(model, test_loader, device)
print(f»AUC: metrics[‘auc’]:.4f»)
print(f»Average Precision: metrics[‘ap’]:.4f»)
print(f»Accuracy: metrics[‘accuracy’]:.4f»)
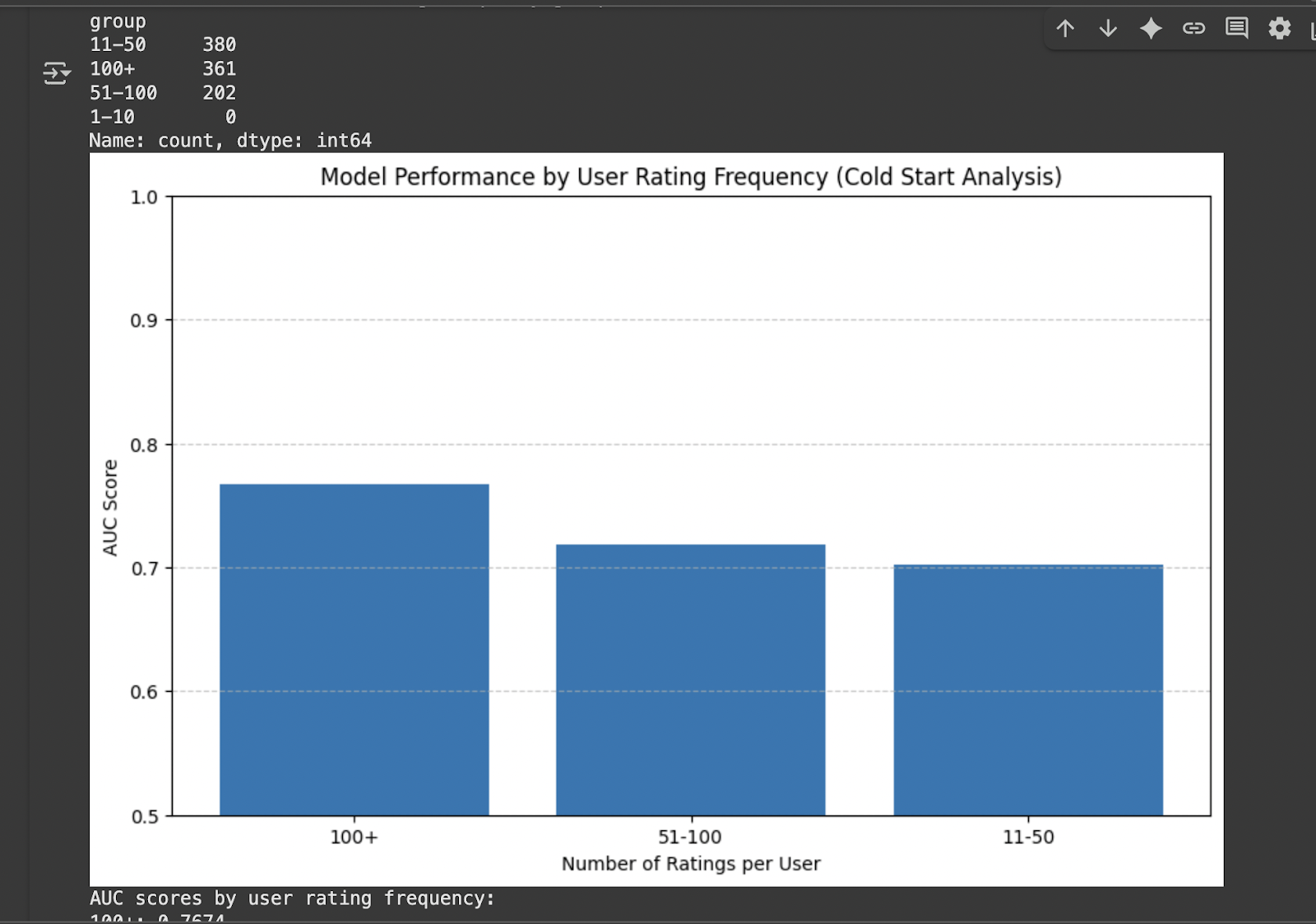
Cold Start Analysis
Let& analyze how our model performs for new users or users with few ratings (cold start problem):
Copy Code Copied Use a different Browser
user_rating_counts = ratings_by(‘user_id’).size().reset_index(name=’count’)
user_rating_counts[‘group’] = (user_rating_counts[‘count’],
bins=[0, 10, 50, 100, float(‘inf’)],
labels=[‘1-10′, ’11-50′, ’51-100’, ‘100+’])
print(«Number of users in each rating frequency group:»)
print(user_rating_counts[‘group’].value_counts())
def evaluate_by_user_group(model, ratings_df, user_groups, device):
results =
for group_name, user_ids in user_():
group_ratings = ratings_df[ratings_df[‘user_id’].isin(user_ids)]
group_dataset = NCFDataset(group_ratings)
group_loader = DataLoader(group_dataset, batch_size=256, shuffle=False)
if len(group_loader) == 0:
continue
()
predictions = []
true_labels = []
with _grad():
for batch in group_loader:
user_ids = batch[‘user_id’].to(device)
item_ids = batch[‘item_id’].to(device)
labels = batch[‘label’].to(device)
outputs = model(user_ids, item_ids)
d(().numpy())
true_d(().numpy())
from cs import roc_auc_score
try:
auc = roc_auc_score(true_labels, predictions)
results[group_name] = auc
except:
results[group_name] = None
return results
user_groups =
for group in user_rating_counts[‘group’].unique():
users_in_group = user_rating_counts[user_rating_counts[‘group’] == group][‘user_id’].values
user_groups[group] = users_in_group
group_performance = evaluate_by_user_group(model, test_df, user_groups, device)
e(figsize=(10, 6))
groups = []
aucs = []
for group, auc in group_():
if auc is not None:
d(group)
d(auc)
(groups, aucs)
l(‘Number of Ratings per User’)
l(‘AUC Score’)
(‘Model Performance by User Rating Frequency (Cold Start Analysis)’)
(0.5, 1.0)
(axis=’y’, linestyle=’—‘, alpha=0.7)
()
print(«AUC scores by user rating frequency:»)
for group, auc in group_():
if auc is not None:
print(f»group: auc:.4f»)
Business Insights and Extensions
Copy Code Copied Use a different Browser
def analyze_predictions(model, data_loader, device):
()
predictions = []
true_labels = []
with _grad():
for batch in data_loader:
user_ids = batch[‘user_id’].to(device)
item_ids = batch[‘item_id’].to(device)
labels = batch[‘label’].to(device)
outputs = model(user_ids, item_ids)
d(().numpy())
true_d(().numpy())
results_df = pd.DataFrame(
‘true_label’: true_labels,
‘predicted_score’: predictions
)
e(figsize=(12, 6))
ot(1, 2, 1)
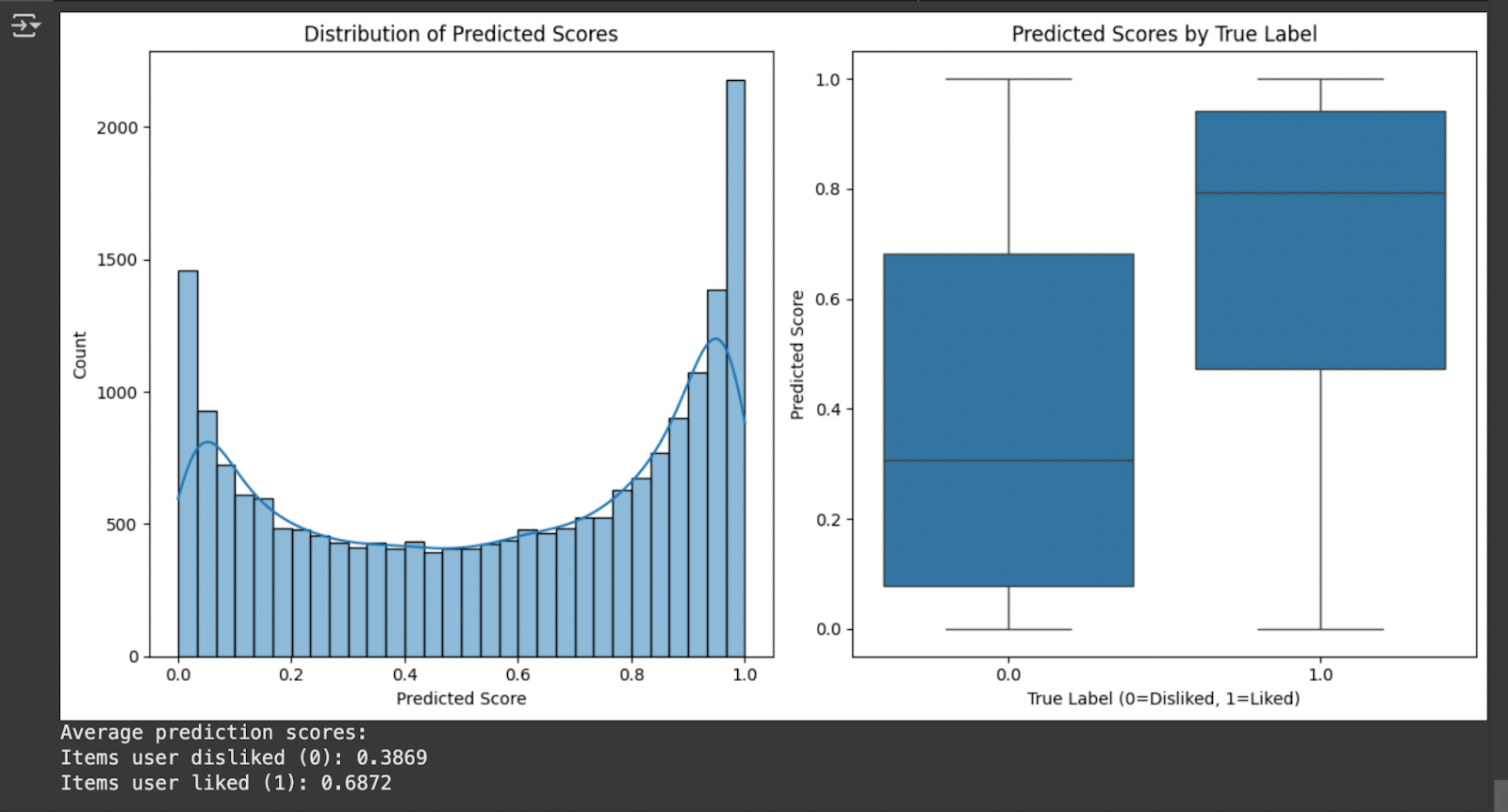
lot(results_df[‘predicted_score’], bins=30, kde=True)
(‘Distribution of Predicted Scores’)
l(‘Predicted Score’)
l(‘Count’)
ot(1, 2, 2)
ot(x=’true_label’, y=’predicted_score’, data=results_df)
(‘Predicted Scores by True Label’)
l(‘True Label (0=Disliked, 1=Liked)’)
l(‘Predicted Score’)
_layout()
()
avg_scores = results_by(‘true_label’)[‘predicted_score’].mean()
print(«Average prediction scores:»)
print(f»Items user disliked (0): avg_scores[0]:.4f»)
print(f»Items user liked (1): avg_scores[1]:.4f»)
analyze_predictions(model, test_loader, device)
This tutorial demonstrates implementing Neural Collaborative Filtering , a deep learning recommendation system combining matrix factorization with neural networks. Using the MovieLens dataset and PyTorch, we built a model that generates personalized content recommendations. The implementation addresses key challenges, including the cold start problem and provides performance metrics like AUC and precision-recall curves. This foundation can be extended with hybrid approaches, attention mechanisms, or deployable web applications for various business recommendation scenarios.
Here is the . Also, don’t forget to follow us on and join our and . Don’t Forget to join our .
The post appeared first on .
#ArtificialIntelligence #MachineLearning #AI #DeepLearning #Robotics