
Retrieval-Augmented Generation (RAG) has significantly enhanced the capabilities of large language models (LLMs) by incorporating external knowledge to provide more contextually relevant and accurate responses. However, this technique comes with a major downside: it often leads to high computational and memory costs. These challenges are primarily due to the injection of long sequences of external documents into the requests, which can expand the original sequence length by more than tenfold. As a result, the increased computational and memory requirements hinder the efficiency of RAG, posing a substantial obstacle to its scalability for real-time applications. Previous attempts to optimize LLM inference through sharing intermediate states have been useful, but they fail to fully address the unique demands of RAG, particularly those arising from long sequence generation and frequent knowledge retrieval.
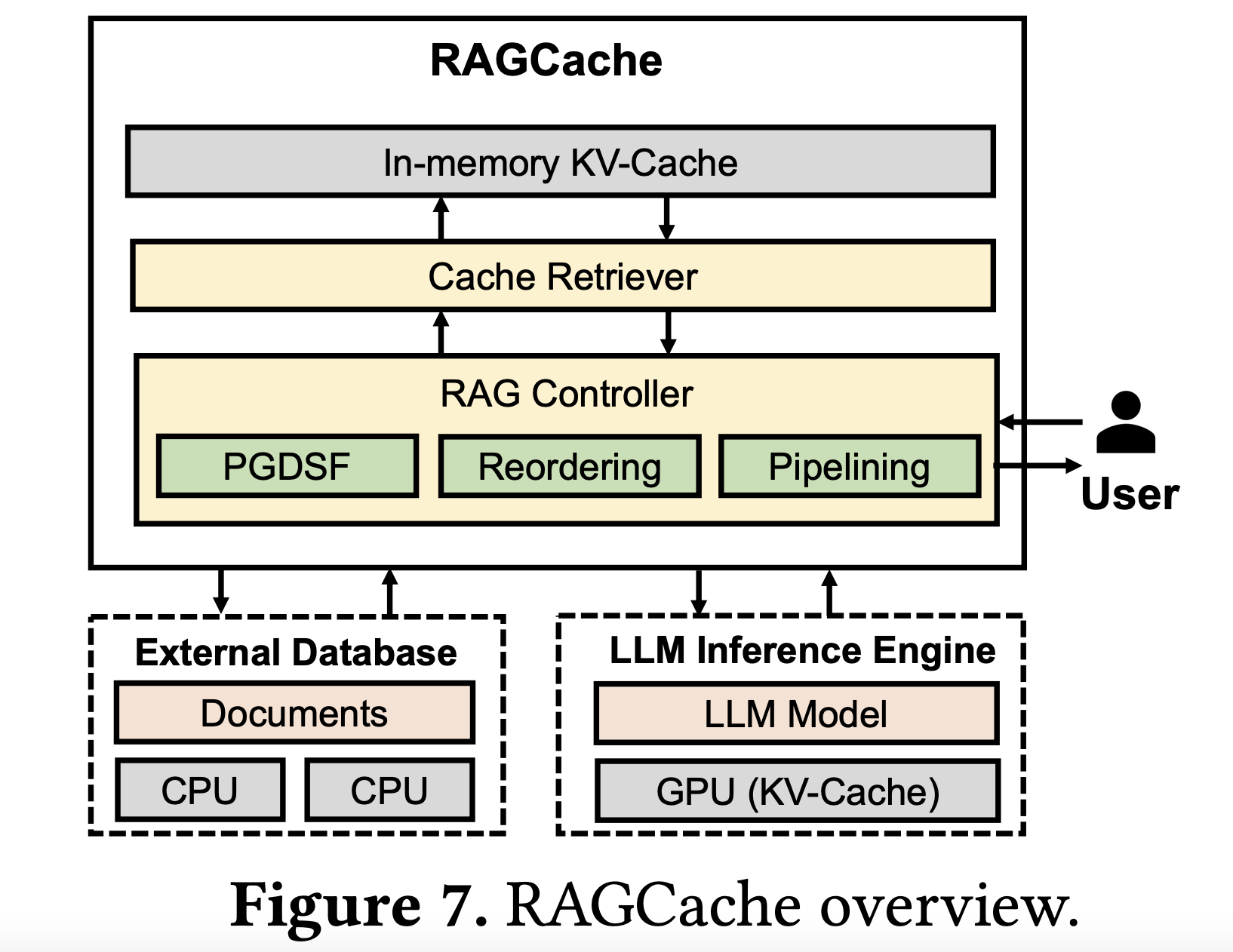
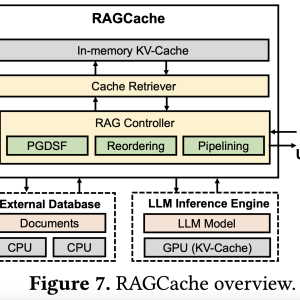
A team of researchers from Peking University and ByteDance introduced RAGCache, a novel multilevel dynamic caching system specifically designed to optimize Retrieval-Augmented Generation. It tackles the inefficiencies of traditional RAG setups by introducing a knowledge tree that caches the intermediate states of retrieved documents in both GPU and host memory hierarchies. RAGCache uses a replacement policy tailored to be aware of LLM inference characteristics and RAG retrieval patterns, significantly improving cache hit rates. Additionally, the system overlaps the retrieval and inference stages, reducing end-to-end latency. This design allows RAGCache to dynamically cache and manage key-value tensors, making it the first system capable of sharing these states across multiple requests. By doing so, RAGCache reduces redundant computations and accelerates response times while also leveraging GPU and host memory in an efficient manner.
RAGCache employs a knowledge tree to organize the cached key-value tensors of retrieved documents. Frequently accessed documents are stored in fast GPU memory, while less frequently accessed ones are stored in slower host memory. A core innovation of RAGCache is its prefix-aware Greedy-Dual-Size-Frequency (PGDSF) replacement policy, which carefully considers the document order, frequency, size, and recency to minimize cache misses. This design ensures that the most valuable intermediate states are retained and reused, leading to significantly reduced processing times for subsequent requests. Another key feature is dynamic speculative pipelining, which overlaps the vector retrieval and LLM inference steps, mitigating the latency caused by sequential execution. These technical improvements culminate in a system that achieves up to 4× faster time to first token (TTFT) and up to 2.1× improved throughput compared to traditional setups like vLLM integrated with Faiss.
The importance of RAGCache lies in its ability to make RAG more practical for real-time and large-scale use cases. In the benchmarks conducted, RAGCache was implemented on vLLM, a leading LLM inference system, alongside Faiss, a popular vector database. The results were compelling: RAGCache reduced the time to first token by up to 4× and improved throughput by 2.1× compared with vLLM using Faiss. Furthermore, when compared to SGLang, a high-performance LLM serving system, RAGCache still showed substantial improvements of up to 3.5× reduction in TTFT and 1.8× enhancement in throughput. These performance gains underscore the efficiency of multilevel caching combined with advanced retrieval and generation overlapping techniques. By ensuring that frequently accessed documents are efficiently cached, RAGCache significantly lowers computational burdens, making it ideal for scenarios that involve high volumes of similar retrieval requests.
RAGCache represents a transformative step in optimizing Retrieval-Augmented Generation by introducing an intelligent, multilevel caching system that reduces latency and boosts throughput. Its innovative approach to caching intermediate states across multiple requests and dynamically managing memory across GPU and host levels directly addresses the bottlenecks of current RAG systems. The experimental results show that RAGCache can provide substantial performance improvements, making it a powerful tool for scaling up RAG in practical, real-time applications. As LLMs continue to grow in complexity and size, solutions like RAGCache are critical for ensuring that these technologies can be deployed efficiently without compromising on speed or computational cost.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[AI Magazine/Report] Read Our Latest Report on ‘SMALL LANGUAGE MODELS‘
The post RAGCache: Optimizing Retrieval-Augmented Generation with Dynamic Caching appeared first on MarkTechPost.