
Maintaining the model’s capacity to manage changes in data distribution, i.e., the ability to function effectively even when presented with data that is different from what it was trained on, is essential when modifying a pre-trained foundation model for certain downstream tasks. Because retraining the entire model for each new dataset or task can be time-consuming and resource-intensive, achieving this robustness is crucial. A more effective adaptation strategy is preferred instead, one that improves performance on specialized tasks without necessitating a total redesign while preserving the fundamental knowledge.
Existing techniques, such as weight interpolation, provide a simple and useful way to overcome this issue. These techniques usually combine the weights of a refined version with the pre-trained model to achieve a balance between task-specific modifications and general knowledge. However, these approaches often use a fixed or static interpolation coefficient for all test samples. Although this fixed technique works well in many situations, it may limit the model’s capacity to adjust to differences among various data samples, which could limit its performance improvements on tasks that come after.
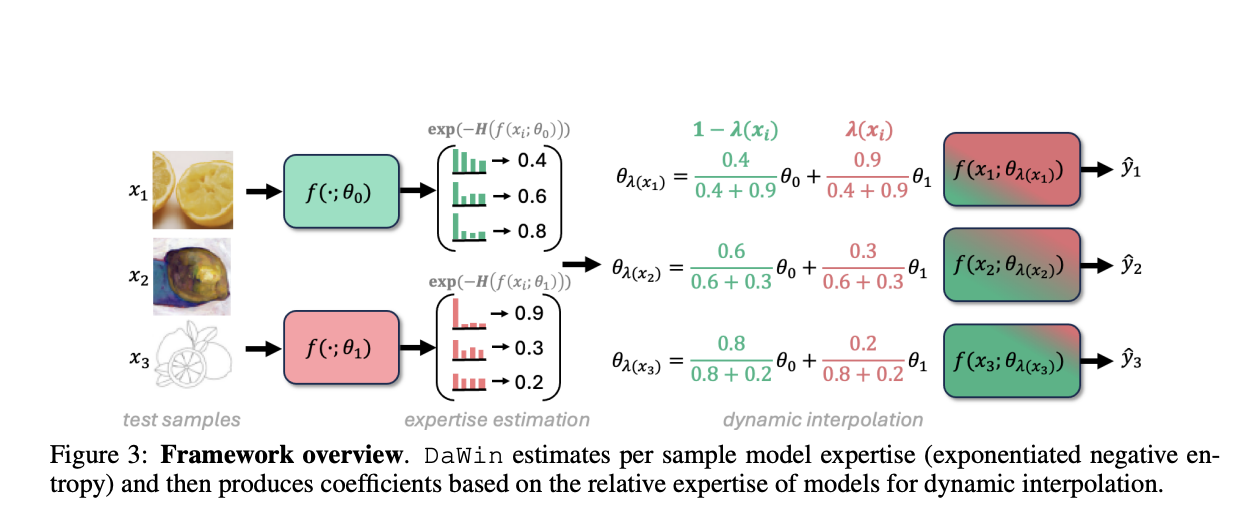
To overcome these limitations, a team of researchers from the University of Wisconsin–Madison, Yonsei University, and NAVER AI Lab has introduced a new technique called Dynamic Weight Interpolation or DaWin. The distinctive feature of DaWin is that it doesn’t need any more training. Rather, it dynamically modifies the model weight blending according to the entropy of predictions for every test sample. In this application, entropy quantifies the degree of uncertainty or confidence in a model’s forecast, where a prediction with a lower entropy is considered more confident. DaWin can identify the proper weight blending by evaluating each model’s competence on a per-sample basis by examining the entropy levels.
DaWin determines the best combination for every sample during inference, in contrast to earlier techniques that require additional training to modify these coefficients. It eliminates the need for a separate training procedure to calibrate the blending coefficients for various samples. DaWin uses a mixture modeling strategy to handle the possible computational difficulties of using a dynamic approach during inference. Grouping comparable samples together makes it easier for the model to process sets of data with related properties. DaWin minimizes the overhead involved in determining unique interpolation coefficients for every sample by clustering the coefficients. This method greatly expedites the procedure while maintaining the advantages of dynamic adaptation.
The team has verified DaWin’s effectiveness using 14 distinct tasks and a range of extensive visual recognition standards. This assessment covered multi-task learning settings with eight distinct classification tasks as well as robust fine-tuning scenarios, including ImageNet and five related benchmarks that measure performance under distribution shifts. In every study, the results consistently showed that DaWin works better than static weight interpolation techniques, providing considerable gains in accuracy and robustness.
These performance improvements have a low computational cost compared to other dynamic approaches. DaWin is a workable option for real-world applications where efficiency and adaptability are crucial since it can adapt to the unique requirements of each test sample without the need for additional training or a large amount of processing resources.
The team has summarized their primary contributions as follows.
- The team has provided a simple numerical analysis of Oracle dynamic interpolation techniques, showing that the cross-entropy (X-entropy) ratio is a reliable measure for computing the per-sample interpolation coefficient.
- DaWin has been proposed as a practical method that economically approximates Oracle dynamic interpolation. It automatically calculates interpolation coefficients for each sample based on the predicted entropy ratio of several models on unlabelled test samples.
- Extensive testing has shown that DaWin greatly improves classification accuracy in multi-task learning and distribution shift scenarios. This enhancement is accomplished without significantly lengthening the inference time. The team has also offered a theoretical justification for DaWin’s effectiveness.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
The post DaWin: A Training-Free Dynamic Weight Interpolation Framework for Robust Adaptation appeared first on MarkTechPost.