Large language models (LLMs) have gained immense capabilities due to their training on vast internet-based datasets. However, this broad exposure has inadvertently incorporated harmful content, enabling LLMs to generate toxic, illicit, biased, and privacy-infringing material. As these models become more advanced, the embedded hazardous information poses increasing risks, potentially making dangerous knowledge more accessible to malicious actors. While safety fine-tuning techniques have been implemented to mitigate these issues, researchers continue to discover jailbreaks that bypass these safeguards. The robustness of these protective measures remains an open research question, highlighting the critical need for more effective solutions to ensure the responsible development and deployment of LLMs in various applications.
Researchers have attempted various approaches to address the challenges posed by hazardous knowledge in LLMs. Safety training methods like DPO and PPO have been implemented to fine-tune models to refuse questions about dangerous information. Circuit breakers, utilizing representation engineering, have been introduced to orthogonalize directions corresponding to unwanted concepts. However, these safeguards have shown limited robustness as jailbreaks continue to bypass protections and extract hazardous knowledge through prompting strategies, white-box access optimization, or activation ablation.
Unlearning has emerged as a promising solution, aiming to update model weights to remove specific knowledge entirely. This approach has been applied to various topics, including fairness, privacy, safety, and hallucinations. Notable methods like RMU and NPO have been developed for safety-focused unlearning. However, recent adversarial evaluations have revealed vulnerabilities in unlearning techniques, demonstrating that supposedly removed information can still be extracted through probing internal representations or fine-tuning unlearned models. These findings underscore the need for more robust unlearning methods and thorough evaluation protocols.
This study by researchers from ETH Zurich and Princeton University challenges the fundamental differences between unlearning and traditional safety fine-tuning from an adversarial perspective. Using the WMDP benchmark to measure hazardous knowledge in LLMs, the research argues that unlearning is only possible if significant accuracy can be recovered by updating model weights or with data having minimal mutual information with the target knowledge. The study conducts a comprehensive white-box evaluation of state-of-the-art unlearning methods for hazardous knowledge, comparing them to traditional safety training with DPO. The findings reveal vulnerabilities in current unlearning techniques, emphasizing the limitations of black-box evaluations and the need for more robust unlearning methods.
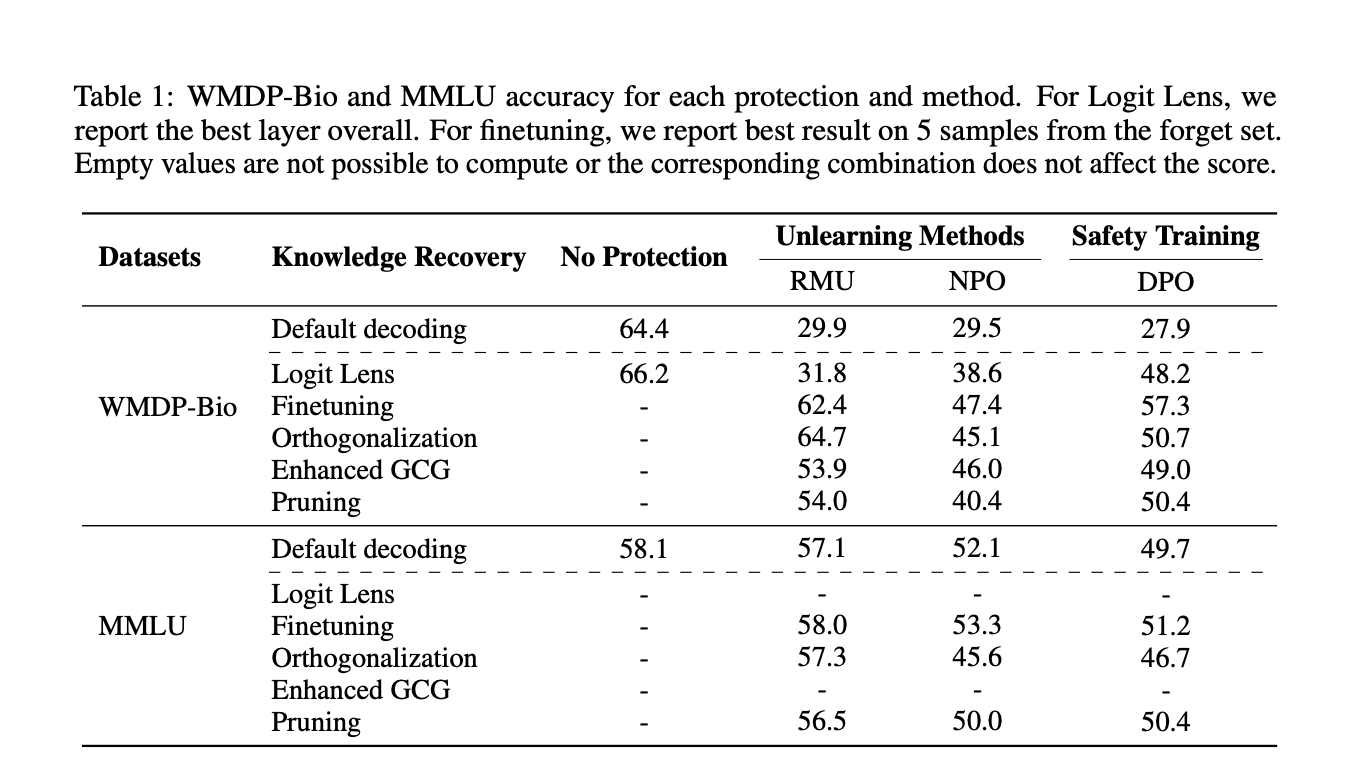
The study focuses on unlearning methods for safety, specifically targeting the removal of hazardous knowledge from large language models. The research utilizes forget and retain sets, with the former containing information to be unlearned and the latter preserving neighboring information. The evaluation employs datasets from the WMDP benchmark for biology and cybersecurity. The threat model assumes white-box access to an unlearned model, allowing weight modification and activation space intervention during inference. The study evaluates RMU, NPO+RT, and DPO as unlearning and safety training methods. Experiments use Zephyr-7B-β as the base model, fine-tuned on WMDP and WikiText corpora. GPT-4 generates preference datasets for NPO and DPO training. Performance is assessed using the WMDP benchmark and MMLU to measure general utility after unlearning.
The study employs a diverse range of methods to uncover hazardous capabilities in unlearned models, drawing inspiration from well-known safety jailbreaks with modifications to target unlearning methods. These techniques include:
1. Finetuning: Using Low-Rank Adaptation (LoRA) to fine-tune unlearned models on datasets with varying levels of mutual information with the unlearned knowledge.
2. Orthogonalization: Investigating refusal directions in the activation space of unlearned models and removing them during inference.
3. Logit Lens: Projecting activations in the residual stream onto the model’s vocabulary to extract answers from intermediate layers.
4. Enhanced GCG: Developing an improved version of Gradient-based Conditional Generation (GCG) that targets unlearning methods by optimizing prefixes to prevent hazardous knowledge detection.
5. Set difference pruning: Identifying and pruning neurons associated with safety alignment using SNIP scores and set difference methods.
These approaches aim to comprehensively evaluate the robustness of unlearning techniques and their ability to effectively remove hazardous knowledge from language models.
The study reveals significant vulnerabilities in unlearning methods. Finetuning on just 10 unrelated samples substantially recovers hazardous capabilities across all methods. Logit Lens analysis shows unlearning methods more effectively remove knowledge from the residual stream compared to safety training. Orthogonalization techniques successfully recover hazardous knowledge, with RMU being the most vulnerable. Critical neurons responsible for unlearning were identified and pruned, leading to increased performance on WMDP. Universal adversarial prefixes, crafted using enhanced GCG, significantly increased accuracy on hazardous knowledge benchmarks for all methods. These findings demonstrate that both safety training and unlearning can be compromised through various techniques, suggesting that unlearned knowledge is not truly removed but rather obfuscated.
This comprehensive white-box evaluation of state-of-the-art unlearning methods for AI safety reveals significant vulnerabilities in current approaches. The study demonstrates that unlearning techniques fail to reliably remove hazardous knowledge from model weights, as evidenced by the recovery of supposedly unlearned capabilities through various methods. These findings challenge the perceived superiority of unlearning methods over standard safety training in providing robust protection. The research emphasizes the inadequacy of black-box evaluations for assessing unlearning effectiveness, as they fail to capture internal model changes. These results underscore the urgent need for developing more robust unlearning techniques and implementing thorough evaluation protocols to ensure the safe deployment of large language models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Want to get in front of 1 Million+ AI Readers? Work with us here
The post Evaluating the Vulnerabilities of Unlearning Techniques in Large Language Models: A Comprehensive White-Box Analysis appeared first on MarkTechPost.