Large language models (LLMs) have garnered significant attention for their ability to understand and generate human-like text. These models possess the unique capability to encode factual knowledge effectively, thanks to the vast amount of data they are trained on. This ability is crucial in various applications, ranging from natural language processing (NLP) tasks to more advanced forms of artificial intelligence. However, understanding how these models acquire and retain factual information during pretraining is a complex challenge. This research investigates the intricate process through which LLMs internalize knowledge and explores how these models can be optimized to maintain and generalize the knowledge they acquire.
One of the major issues researchers face in training LLMs is the loss of factual knowledge over time. When large datasets are used in pretraining, LLMs struggle to retain the details of specific facts, especially when new information is introduced in subsequent stages of training. Furthermore, LLMs often struggle to remember rare or long-tail knowledge, significantly affecting their ability to generalize across diverse topics. This loss of retention impairs the accuracy of models when applied to complex or infrequently encountered scenarios, presenting a considerable barrier to improving the performance of LLMs.
Several methods have been introduced to address these challenges, focusing on improving the acquisition and retention of factual knowledge in LLMs. These methods include scaling up model sizes and pretraining datasets, using advanced optimization techniques, and modifying batch sizes to better handle data during training. Deduplication of datasets has also been proposed to reduce redundancy in the training data, leading to more efficient learning. Despite these efforts, the fundamental problems of rapid forgetting and the model’s difficulty in generalizing less frequent facts persist, and current solutions have only made incremental improvements.
Researchers from KAIST, UCL, and KT have introduced a novel approach to studying the acquisition and retention of factual knowledge in LLMs. They designed an experiment that systematically injected new factual knowledge into the model during pretraining. By analyzing the model’s ability to memorize and generalize this knowledge under various conditions, the researchers aimed to uncover the dynamics that govern how LLMs learn and forget. Their approach involved monitoring the model’s performance across different checkpoints and observing the effect of factors such as batch size, data duplication, and paraphrasing on knowledge retention. This experiment offered valuable insights into optimizing training strategies to improve long-term memory in LLMs.
The researchers’ methodology was thorough, involving detailed evaluation at multiple stages of pretraining. They conducted the experiments using fictional knowledge that the model had not encountered before to ensure the accuracy of the analysis. Various conditions were tested, including injecting the same factual knowledge repeatedly, paraphrasing it, or presenting it only once. To measure the effectiveness of knowledge retention, the team evaluated the model’s performance by examining changes in the probability of recalling specific facts over time. They discovered that larger batch sizes helped the model maintain factual knowledge more effectively, while duplicated data led to faster forgetting. By using a variety of test conditions, the research team could determine the most effective strategies for training LLMs to retain and generalize knowledge.
The performance of the proposed methodology revealed several key findings. First, the research showed that larger models, such as those with 7 billion parameters, exhibited better factual knowledge retention than smaller models with only 1 billion parameters. Interestingly, the amount of training data used did not significantly impact retention, contradicting the belief that more data leads to better model performance. Instead, the researchers found that models trained with a deduplicated dataset were more robust, with slower rates of forgetting. For instance, models exposed to paraphrased knowledge showed a higher degree of generalization, meaning they could apply the knowledge more flexibly in different contexts.
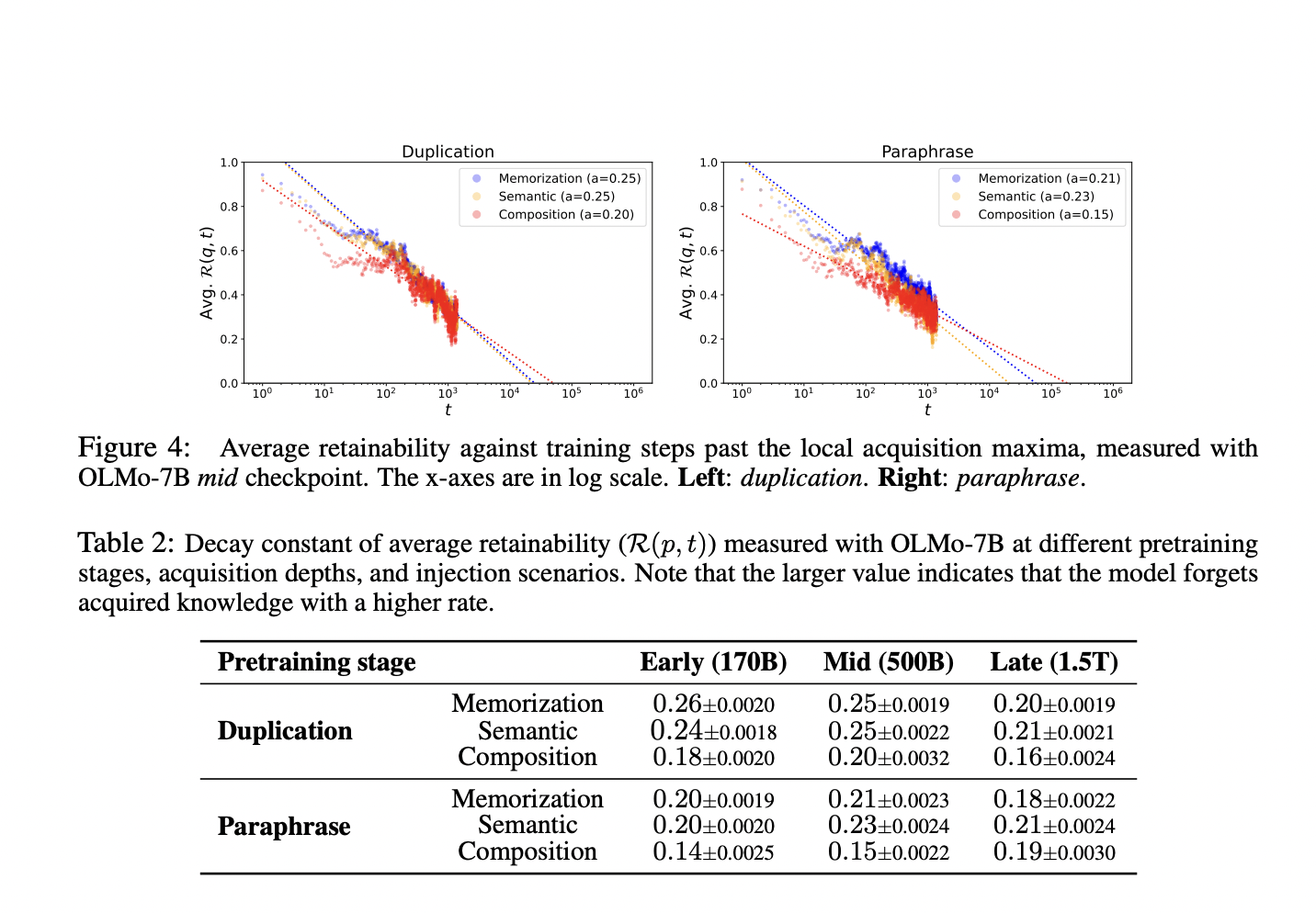
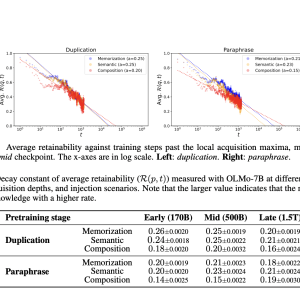
Another key finding was the relationship between batch size and knowledge retention. Models trained with larger batch sizes, such as 2048, demonstrated greater resistance to forgetting than those trained with smaller batch sizes of 128. The study also uncovered a power-law relationship between training steps and forgetting, showing that factual knowledge degrades more quickly in models trained with duplicated data. On the other hand, models exposed to a larger volume of unique facts retained this knowledge longer, underscoring the importance of dataset quality over sheer quantity. For instance, the decay constant for duplicated data in the late pretraining stage was 0.21, compared to 0.16 for paraphrased data, indicating slower forgetting when the dataset was deduplicated.
The research offers a promising approach to addressing the issues of forgetting and poor generalization in LLMs. The findings suggest that optimizing batch size and deduplication during the pretraining phase can significantly improve the retention of factual knowledge in LLMs. These improvements can make models more reliable across a broader range of tasks, especially when dealing with less common or long-tail knowledge. Ultimately, this study provides a clearer understanding of the mechanisms behind knowledge acquisition in LLMs, opening new avenues for future research to refine training methods and further enhance the capabilities of these powerful models.
This research has provided valuable insights into how large language models acquire and retain knowledge. By identifying factors such as model size, batch size, and dataset quality, the study offers practical solutions for improving LLM performance. These findings highlight the importance of efficient training techniques and underscore the potential for optimizing LLMs to become even more effective in handling complex and diverse language tasks.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 50k+ ML SubReddit
Subscribe to the fastest-growing ML Newsletter with over 26k+ subscribers.
The post This AI Paper from KAIST, UCL and KT Investigates the Acquisition and Retention of Factual Knowledge in Large Language Models appeared first on MarkTechPost.