Speech tokenization is a fundamental process that underpins the functioning of speech-language models, enabling these models to carry out a range of tasks, including text-to-speech (TTS), speech-to-text (STT), and spoken-language modeling. Tokenization offers the structure required by these models to efficiently analyze, process, and create speech by turning raw speech signals into discrete tokens. Tokenization is trained separately from the language model itself in many conventional methods, though. This division can result in a discrepancy between the generation of the tokens and their subsequent application in activities such as speech synthesis or recognition.
Conventional models of speech tokenizers rely on discrete representations of continuous speech signals created by quantization techniques and independent acoustic models. Frequently, the development of these tokenizers occurs independently of the language models they support being trained. Consequently, there is a chance that the way the language model interprets and utilizes the speech tokens produced during the tokenization phase will not match. Because of this mismatch, the speech-language model’s performance can be limited. This is because the tokenization process may not precisely match the learning objectives of the language model.
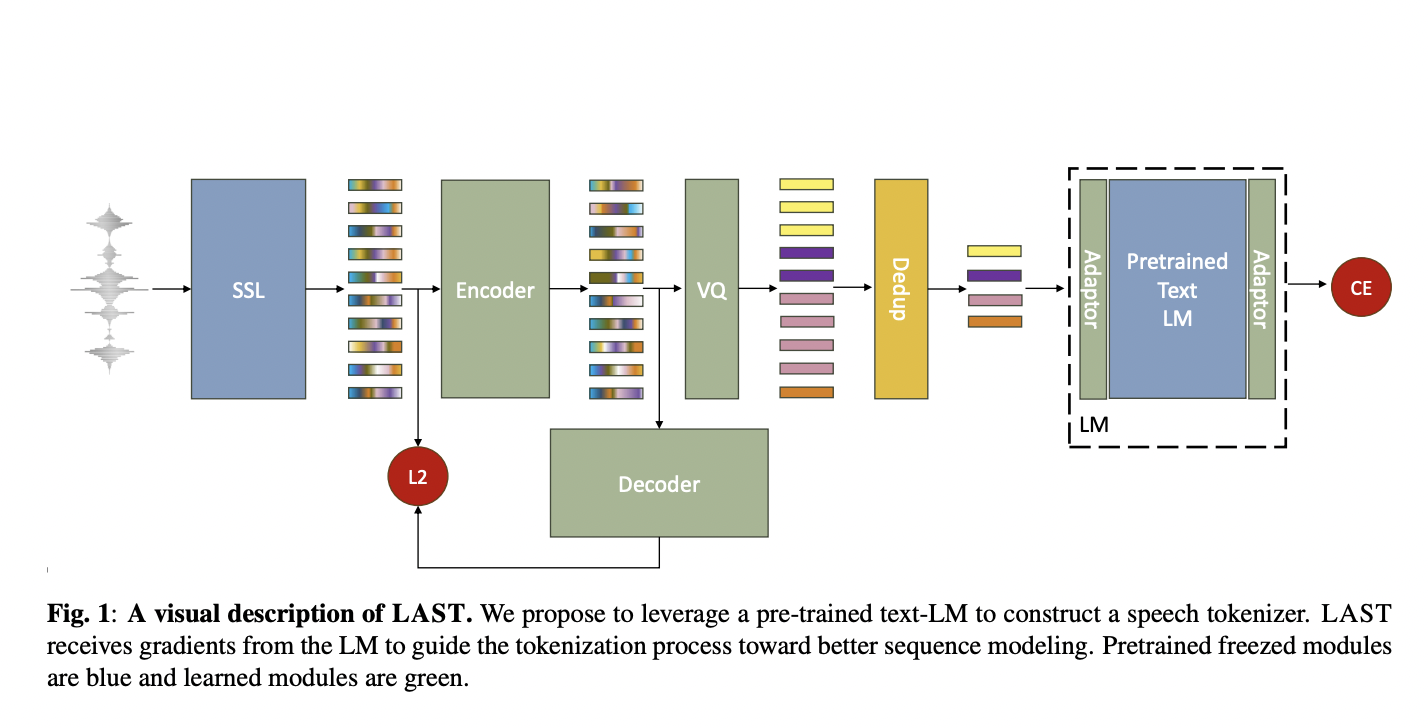
To overcome some of these issues, a team of researchers from the Hebrew University of Jerusalem have introduced Language Model Aware Speech Tokenisation (LAST). With this approach, the speech tokenization procedure incorporates a pre-trained text language model (LM). There are three primary parts to LAST, which are as follows.
- A contextualized speech representation is extracted via a pre-trained, frozen speech SSL model.
- These representations are transformed into discrete tokens by an adapter-quantization module.
- An already-trained, frozen text learning model that directs the tokenization process, making it more appropriate for sequential modeling.
This technique seeks to provide discrete speech representations that are more appropriate for spoken language modeling and speech-to-text conversion by incorporating the goals of these text-based models into the tokenization process. This method creates a new feature space that is more appropriate for speech Language Model grouping and representation by transforming the features acquired from a pre-trained speech model.
There are various benefits to this alignment of the speech and textual models. First, it makes it possible for the voice tokenization process to be more influenced by the language’s fundamental structure, allowing the tokens to represent linguistic elements pertinent to written and spoken communication. Aligning the tokenization with the LM’s aims decreases the chance of mismatch, leading to more accurate and efficient performance across multiple speech tasks.
The work that presents this approach also includes the effects of important design decisions, such as the size of the text-based language model and the voice vocabulary. By experimenting with various setups, the researchers were able to determine how these variables affect the language model’s overall performance and the efficiency of the tokenization process. According to their research, the integrated tokenization strategy performs better than conventional techniques in speech-to-text and spoken language modeling tasks.
One of this approach’s most important results is the ability to interpret both speech and text inputs with a single pre-trained language model. This is a significant divergence from traditional approaches, which usually ask for distinct models for these various modalities. The suggested tokenization method improves efficiency and performance by streamlining the process with a single model that can handle both speech and text.
In conclusion, this approach to voice tokenization represents a major improvement over conventional methods by guaranteeing a greater alignment between the tokenization process and the goals of the language model. Speech features become a new space that enables more efficient clustering and representation by incorporating pre-trained text-language model objectives. As a result, a single model can be used for both speech and text inputs, leading to a more reliable and adaptable speech-language model that works better on a variety of tasks, including speech-to-text and spoken-language modeling.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
The post Language Model Aware Speech Tokenization (LAST): A Unique AI Method that Integrates a Pre-Trained Text Language Model into the Speech Tokenization Process appeared first on MarkTechPost.