End-to-end (E2E) neural networks have emerged as flexible and accurate models for multilingual automatic speech recognition (ASR). However, as the number of supported languages increases, particularly those with large character sets like Chinese, Japanese, and Korean (CJK), the output layer size grows substantially. This expansion negatively impacts compute resources, memory usage, and asset size. The challenge becomes more pronounced in multilingual systems, where the output often consists of unions of characters or subwords from various languages. Researchers are thus grappling with the need to maintain model efficiency and performance while accommodating a diverse range of languages and their associated character sets in E2E ASR systems.
Previous attempts to address these challenges in multilingual ASR have focused on byte-level representations, particularly using UTF-8 codewords as base tokens. This approach allows for a fixed output vocabulary size of 256, providing compactness and universality across languages. However, byte-level representations often result in longer sequences, especially for CJK languages, potentially increasing error rates as multiple predictions are required for single characters. Researchers proposed byte-level subwords using byte pair encoding (BPE) on UTF-8 codeword sequences to mitigate this. While this reduced the number of decoding steps, it didn’t guarantee valid UTF-8 outputs. A dynamic programming algorithm was later introduced to recover valid characters from potentially invalid byte sequences, though this method optimized for character validity rather than ASR quality.
The state-of-the-art method reviewed by Apple researchers proposes a robust representation learning approach using a vector quantized auto-encoder. This method aims to optimize byte-level representation specifically for E2E ASR tasks, addressing the limitations of previous approaches. The framework is designed to be data-driven, incorporating information from both text and audio to enhance accuracy. It offers flexibility to include additional side information, such as lexicons or phonemes, making it adaptable to various ASR scenarios. Importantly, the method includes an error correction mechanism to handle invalid sequences, with recovery optimized for accuracy rather than other metrics. This approach aligns with the researchers’ criteria for an ideal byte-level representation: task-specific optimization, comprehensive information utilization, and effective error correction.
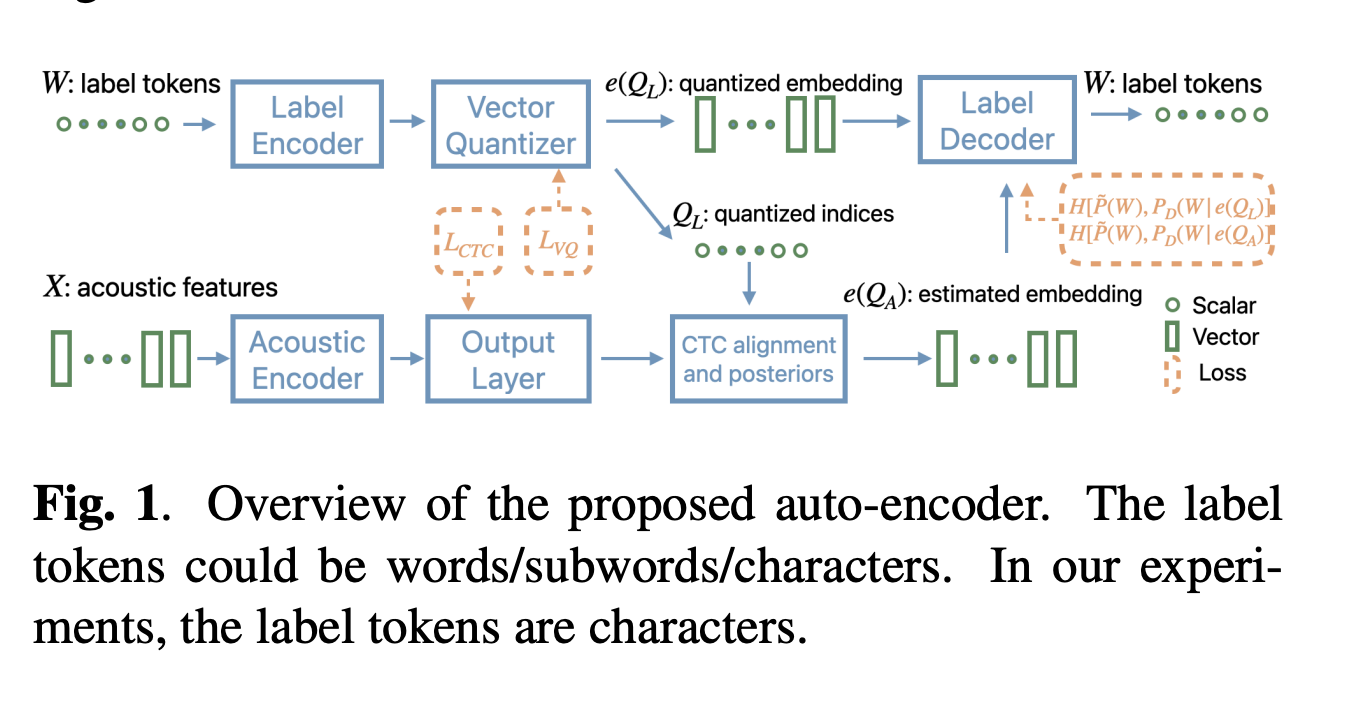
The proposed method formulates the representation problem as an optimization task with latent variables, using a vector quantized auto-encoder (VQ-AE) architecture. This auto-encoder consists of four key components: a label encoder, an acoustic encoder, a label decoder, and a vector quantizer. The system uses vector quantization as its bottleneck, with the indices of quantized embeddings serving as latent variables.
The auto-encoder is optimized using a loss function comprising four terms: cross-entropy losses for label and acoustic encoders, a CTC loss for the acoustic encoder, and a quantization loss. The method employs a Residual VQ-VAE (RVQ-VAE) with two or three codebooks, each containing 256 embeddings, allowing each label token to be represented by 2-3 bytes.
To handle potential errors in byte sequences, the system incorporates an error correction mechanism through the label decoder. This decoder estimates the most likely label sequence, optimizing for accuracy even when faced with invalid byte sequences. The proposed VQ-based representation offers advantages over UTF-8, including fixed-length coding, task-specific optimization, and improved error recovery.
The researchers evaluated their proposed VQ-based representation approach on bilingual English and Mandarin dictation tasks, comparing it with character-based and UTF-8 subword outputs. Using a CTC-AED model with approximately 120M parameters, they tested various output representations on datasets comprising 10k hours of English and 14k hours of Mandarin training data.
Results showed that the VQ-based representation consistently outperformed UTF-8 subword outputs across different subword sizes. With 8000 subwords, the VQ-based approach achieved a 5.8% relative reduction in Word Error Rate (WER) for English and a 3.7% relative reduction in Character Error Rate (CER) for Mandarin compared to UTF-8. When compared to character-based output, both VQ and UTF-8 representations performed better on English, while maintaining similar accuracy for Mandarin. Notably, the VQ-based method with 8000 subwords demonstrated a 14.8% relative error rate reduction for English and a 2.3% reduction for Mandarin compared to character-based output, highlighting its effectiveness and flexibility in multilingual ASR systems.
This study presents a robust algorithm for optimizing byte-level representation in ASR, offering an alternative to UTF-8 representation. This approach can be optimized using audio and text data, with an error correction mechanism designed to enhance accuracy. Testing on English and Mandarin dictation datasets demonstrated a 5% relative reduction in Token Error Rate (TER) compared to UTF-8-based methods. While the current study focused on bilingual ASR, the researchers acknowledge challenges in developing a universal representation for all languages, such as the index collapse issue.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
The post Apple Researchers Propose a Novel AI Algorithm to Optimize a Byte-Level Representation for Automatic Speech Recognition ASR and Compare it with UTF-8 Representation appeared first on MarkTechPost.