Text classification has become a crucial tool in various applications, including opinion mining and topic classification. Traditionally, this task required extensive manual labeling and a deep understanding of machine learning techniques, presenting significant barriers to entry. The advent of large language models (LLMs) like ChatGPT has revolutionized this field, enabling zero-shot classification without additional training. This breakthrough has led to the widespread adoption of LLMs in political and social sciences. However, researchers face challenges when using these models for text analysis. Many high-performing LLMs are proprietary and closed, lacking transparency in their training data and historical versions. This opacity conflicts with open science principles. Also, the substantial computational requirements and usage costs associated with LLMs can make large-scale data labeling prohibitively expensive. Consequently, there is a growing call for researchers to prioritize open-source models and provide strong justification when opting for closed systems.
Natural language inference (NLI) has emerged as a versatile classification framework, offering an alternative to generative Large Language Models (LLMs) for text analysis tasks. In NLI, a “premise” document is paired with a “hypothesis” statement, and the model determines if the hypothesis is true based on the premise. This approach allows a single NLI-trained model to function as a universal classifier across various dimensions without additional training. NLI models offer significant advantages in terms of efficiency, as they can operate with much smaller parameter counts compared to generative LLMs. For instance, a BERT model with 86 million parameters can perform NLI tasks, while the smallest effective zero-shot generative LLMs require 7-8 billion parameters. This difference in size translates to substantially reduced computational requirements, making NLI models more accessible for researchers with limited resources. However, NLI classifiers trade flexibility for efficiency, as they are less adept at handling complex, multi-condition classification tasks compared to their larger LLM counterparts.
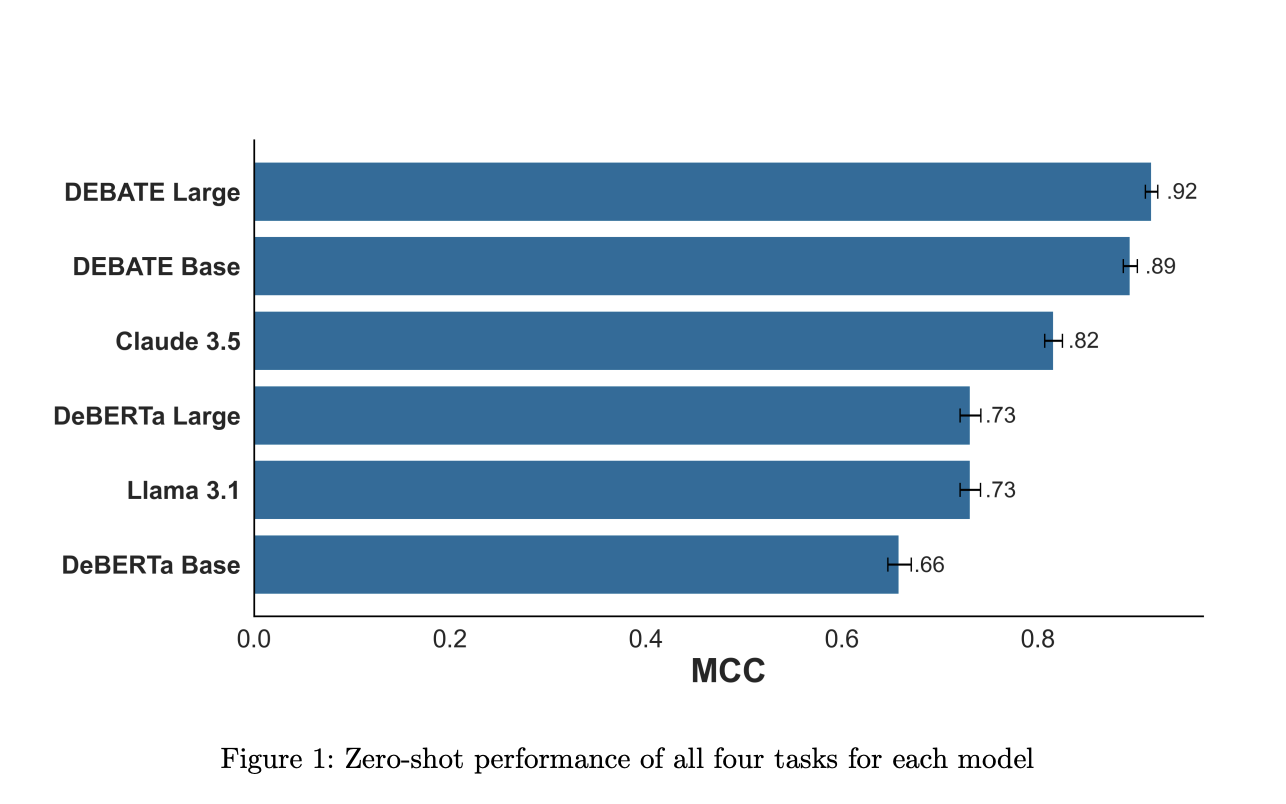
Researchers from the Department of Politics, Princeton University, Pennsylvania State University and Manship School of Mass Communication, Louisiana State University, propose Political DEBATE (DeBERTa Algorithm for Textual Entailment) models, available in Large and Base versions, which represent a significant advancement in open-source text classification for political science. These models, with 304 million and 86 million parameters, respectively, are designed to perform zero-shot and few-shot classification of political text with efficiency comparable to much larger proprietary models. The DEBATE models achieve their high performance through two key strategies: domain-specific training with carefully curated data and the adoption of the NLI classification framework. This approach allows the use of smaller encoder language models like BERT for classification tasks, dramatically reducing computational requirements compared to generative LLMs. The researchers also introduce the PolNLI dataset, a comprehensive collection of over 200,000 labeled political documents spanning various subfields of political science. Importantly, the team commits to versioning both models and datasets, ensuring replicability and adherence to open science principles.
The Political DEBATE models are trained on the PolNLI dataset, a comprehensive corpus comprising 201,691 documents paired with 852 unique entailment hypotheses. This dataset is categorized into four main tasks: stance detection, topic classification, hate-speech and toxicity detection, and event extraction. PolNLI draws from a diverse range of sources, including social media, news articles, congressional newsletters, legislation, and crowd-sourced responses. It also incorporates adapted versions of established academic datasets, such as the Supreme Court Database. Notably, the vast majority of the text in PolNLI is human-generated, with only a small fraction (1,363 documents) being LLM-generated. The dataset’s construction followed a rigorous five-step process: collecting and vetting datasets, cleaning and preparing data, validating labels, hypothesis augmentation, and splitting the data. This meticulous approach ensures both high-quality labels and diverse data sources, providing a robust foundation for training the DEBATE models.
The Political DEBATE models are built upon the DeBERTa V3 base and large models, which were initially fine-tuned for general-purpose NLI classification. This choice was motivated by DeBERTa V3’s superior performance on NLI tasks among transformer models of similar size. The pre-training on general NLI tasks facilitates efficient transfer learning, allowing the models to quickly adapt to political text classification. The training process utilized the Transformers library, with progress monitored via the Weights and Biases library. After each epoch, model performance was evaluated on a validation set, and checkpoints were saved. The final model selection involved both quantitative and qualitative assessments. Quantitatively, metrics such as training loss, validation loss, Matthew’s Correlation Coefficient, F1 score, and accuracy were considered. Qualitatively, the models were tested across various classification tasks and document types to ensure consistent performance. In addition to this, the models’ stability was assessed by examining their behavior on slightly modified documents and hypotheses, ensuring robustness to minor linguistic variations.
The Political DEBATE models were benchmarked against four other models representing various options for zero-shot classification. These included the DeBERTa base and large general-purpose NLI classifiers, which are currently the best publicly available NLI classifiers. The open-source Llama 3.1 8B, a smaller generative LLM capable of running on high-end desktop GPUs or integrated GPUs like Apple M series chips, was also included in the comparison. Also, Claude 3.5 Sonnet, a state-of-the-art proprietary LLM, was tested to represent the cutting-edge of commercial models. Notably, GPT-4 was excluded from the benchmark due to its involvement in the validation process of the final labels. The primary performance metric used was the Matthews Correlation Coefficient (MCC), chosen for its robustness in binary classification tasks compared to metrics like F1 and accuracy. MCC, ranging from -1 to 1 with higher values indicating better performance, provides a comprehensive measure of model effectiveness across various classification scenarios.
The NLI classification framework enables models to quickly adapt to new classification tasks, demonstrating efficient few-shot learning capabilities. The Political DEBATE models showcase this ability, learning new tasks with only 10-25 randomly sampled documents, rivaling or surpassing the performance of supervised classifiers and generative language models. This capability was tested using two real-world examples: the Mood of the Nation poll and a study on COVID-19 tweet classification.
The testing procedure involved zero-shot classification followed by few-shot learning with 10, 25, 50, and 100 randomly sampled documents. The process was repeated 10 times for each sample size to calculate confidence intervals. Importantly, the researchers used default settings without optimization, emphasizing the models’ out-of-the-box usability for few-shot learning scenarios.
The DEBATE models demonstrated impressive few-shot learning performance, achieving results comparable to or better than specialized supervised classifiers and larger generative models. This efficiency extends to computational requirements as well. While initial training on the large PolNLI dataset may take hours or days with high-end GPUs, few-shot learning can be accomplished in minutes without specialized hardware, making it highly accessible for researchers with limited computational resources.
A cost-effectiveness analysis was conducted by running the DEBATE models and Llama 3.1 on various hardware configurations, using a sample of 5,000 documents from the PolNLI test set. The hardware tested included an NVIDIA GeForce RTX 3090 GPU, an NVIDIA Tesla T4 GPU (available free on Google Colab), a Macbook Pro with an M3 max chip, and an AMD Ryzen 9 5900x CPU.
The results demonstrated that the DEBATE models offer significant speed advantages over small generative LLMs like Llama 3.1 8B across all tested hardware. While high-performance GPUs like the RTX 3090 provided the best speed, the DEBATE models still performed efficiently on more accessible hardware such as laptop GPUs (M3 max) and free cloud GPUs (Tesla T4).
Key findings include:
1. DEBATE models consistently outperformed Llama 3.1 8B in processing speed across all hardware types.
2. High-end GPUs like the RTX 3090 offered the best performance for all models.
3. Even on more modest hardware like the M3 max chip or the free Tesla T4 GPU, DEBATE models maintained relatively brisk classification speeds.
4. The efficiency gap between DEBATE models and Llama 3.1 was particularly pronounced on consumer-grade hardware.
This analysis highlights the DEBATE models’ superior cost-effectiveness and accessibility, making them a viable option for researchers with varying computational resources.
This research presents Political DEBATE models that demonstrate significant promise as accessible, efficient tools for text analysis across stance, topic, hate speech, and event classification in political science. For these models, the researchers also present a comprehensive dataset PolNLI. Their design emphasizes open science principles, offering a reproducible alternative to proprietary models. Future research should focus on extending these models to new tasks, such as entity and relationship identification, and incorporating more diverse document sources. Expanding the PolNLI dataset and further refining these models can enhance their generalizability across political communication contexts. Collaborative efforts in data sharing and model development can drive the creation of domain-adapted language models that serve as valuable public resources for researchers in political science.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and LinkedIn. Join our Telegram Channel.
If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
The post Political DEBATE Language Models: Open-Source Solutions for Efficient Text Classification in Political Science appeared first on MarkTechPost.