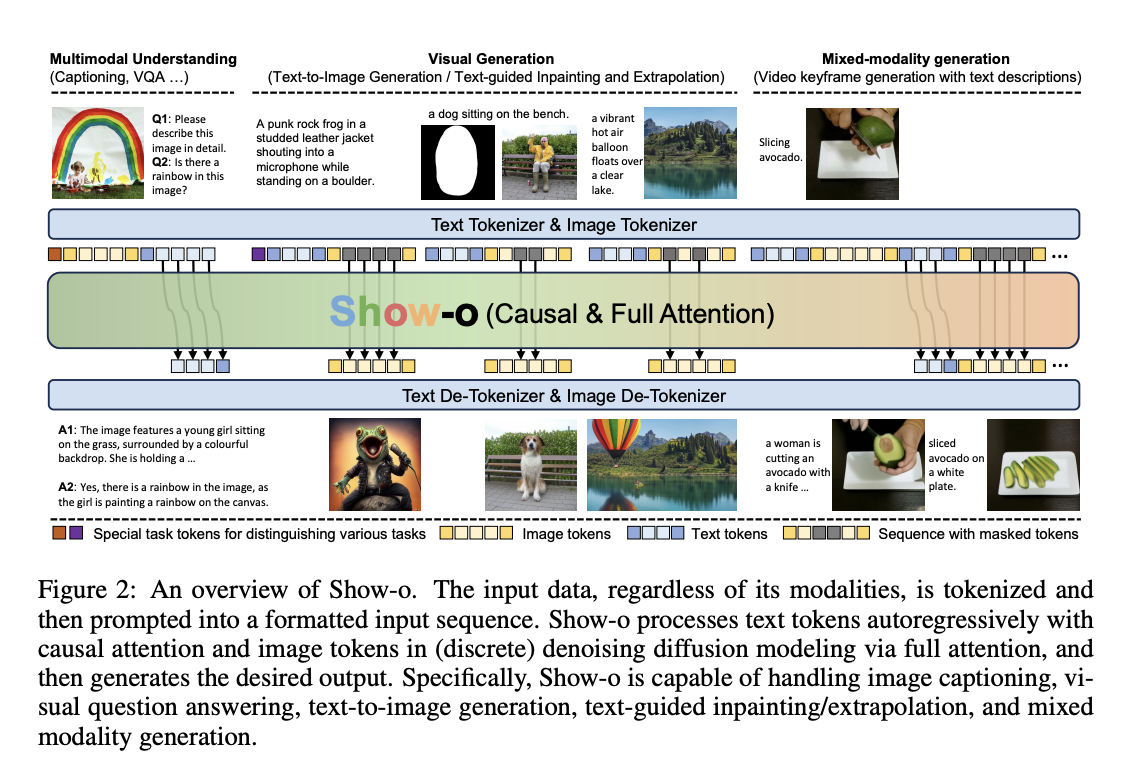
This paper introduces Show-o, a unified transformer model that integrates multimodal understanding and generation capabilities within a single architecture. As artificial intelligence advances, there’s been significant progress in multimodal understanding (e.g., visual question-answering) and generation (e.g., text-to-image synthesis) separately. However, unifying these capabilities in one model remains a challenge. Show-o addresses this by innovatively combining autoregressive and discrete diffusion modeling techniques, allowing it to handle text and image modalities effectively.
Current approaches to multimodal AI often involve separate models for understanding and generation tasks. For instance, models like LLaVA excel at multimodal understanding, while diffusion models like Stable Diffusion focus on image generation. Some recent attempts at unification, such as NExT-GPT, use separate components for different tasks. In contrast, the researchers propose Show-o, a single transformer that unifies both capabilities. Show-o builds upon a pre-trained large language model (LLM) and incorporates autoregressive text modeling and discrete denoising diffusion for images. This allows it to handle diverse input types and generate various outputs, including text responses, photos, and mixed-modality content.
Show-o’s architecture is based on existing LLMs but incorporates a QK-Norm operation in each attention layer. It uses a unified prompting strategy to format various input types, allowing seamless handling of multimodal data. The model employs an “omni-attention” mechanism that applies causal attention to text tokens and full attention to image tokens, enabling efficient processing of both modalities.The training process for Show-o consists of three stages. Initially, the model learns image token embeddings and pixel dependencies. This is followed by aligning images and text for understanding and generation tasks. Finally, the model undergoes fine-tuning with high-quality data to enhance its performance.
Show-o demonstrates impressive performance across various benchmarks. Multimodal understanding tasks achieve comparable or superior results to specialized models despite having fewer parameters. For example, on the VQAv2 benchmark, Show-o outperforms larger unified models like NExT-GPT and Chameleon. In image generation, the model achieves a competitive FID score of 9.24 on the MSCOCO 30K dataset, surpassing some larger models trained on more extensive datasets. Despite its smaller size, the GenEval benchmark for text-to-image generation performs comparably to or better than specialized models like SDXL and SD3. Additionally,it exhibits capabilities in downstream tasks like text-guided image inpainting and extrapolation without requiring fine-tuning. It also shows potential for mixed-modality generation, such as creating video keyframes with corresponding text descriptions.
Show-o represents a significant advancement in multimodal AI by unifying understanding and generation capabilities within a single, efficient transformer architecture. Despite its relatively small size, its ability to achieve comparable or superior performance to specialized models across various tasks highlights its potential as a versatile foundation model for multimodal AI applications. Integrating autoregressive and discrete diffusion modeling techniques allows Show-o to handle different modalities distinctly yet cohesively. This approach simplifies the model architecture and enables new possibilities in mixed-modality tasks and efficient downstream applications.
While there are still areas for improvement, such as text recognition and object counting, Show-o’s performance and versatility make it a promising step towards more integrated and capable AI systems. As research in this direction continues, we may see even more powerful unified models that can seamlessly understand and generate across multiple modalities, potentially revolutionizing various fields of AI application.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Here is a highly recommended webinar from our sponsor: ‘Unlock the power of your Snowflake data with LLMs’
The post Show-o: A Unified AI Model that Unifies Multimodal Understanding and Generation Using One Single Transformer appeared first on MarkTechPost.