The rapid advancement of AI has led to the development of powerful models for discrete and continuous data modalities, such as text and images, respectively. However, integrating these distinct modalities into a single model remains a significant challenge. Traditional approaches often require separate architectures or compromise on data fidelity by quantizing continuous data into discrete tokens, leading to inefficiencies and performance limitations. This challenge is crucial for the advancement of AI, as overcoming it would enable more versatile models capable of processing and generating both text and images seamlessly, thereby enhancing applications in multi-modal tasks.
Current methods to address multi-modal generation primarily focus on specialized models for either discrete or continuous data. Language models, like transformers, excel at handling sequences of discrete tokens, making them highly effective for tasks involving text. Conversely, diffusion models are the state-of-the-art for generating high-quality images by learning to reverse a noise-adding process. However, these models typically require separate training pipelines for each modality, leading to inefficiencies. Moreover, some approaches attempt to unify these modalities by quantizing images into discrete tokens for processing by language models, but this often results in information loss, limiting the model’s ability to generate high-resolution images or perform complex multi-modal tasks.
A team of researchers from Meta, Waymo and University of Southern California propose Transfusion, an innovative method that integrates language modeling and diffusion processes within a single transformer architecture. This proposed method addresses the limitations of existing approaches by allowing the model to process and generate both discrete and continuous data without the need for separate architectures or quantization. Transfusion combines the next-token prediction loss for text with the diffusion process for images, enabling a unified training pipeline. The approach includes key innovations, such as modality-specific encoding and decoding layers and the use of bidirectional attention within images, which collectively enhance the model’s ability to handle diverse data types efficiently and effectively. This integration represents a significant step forward in creating more versatile AI systems capable of performing complex multi-modal tasks.
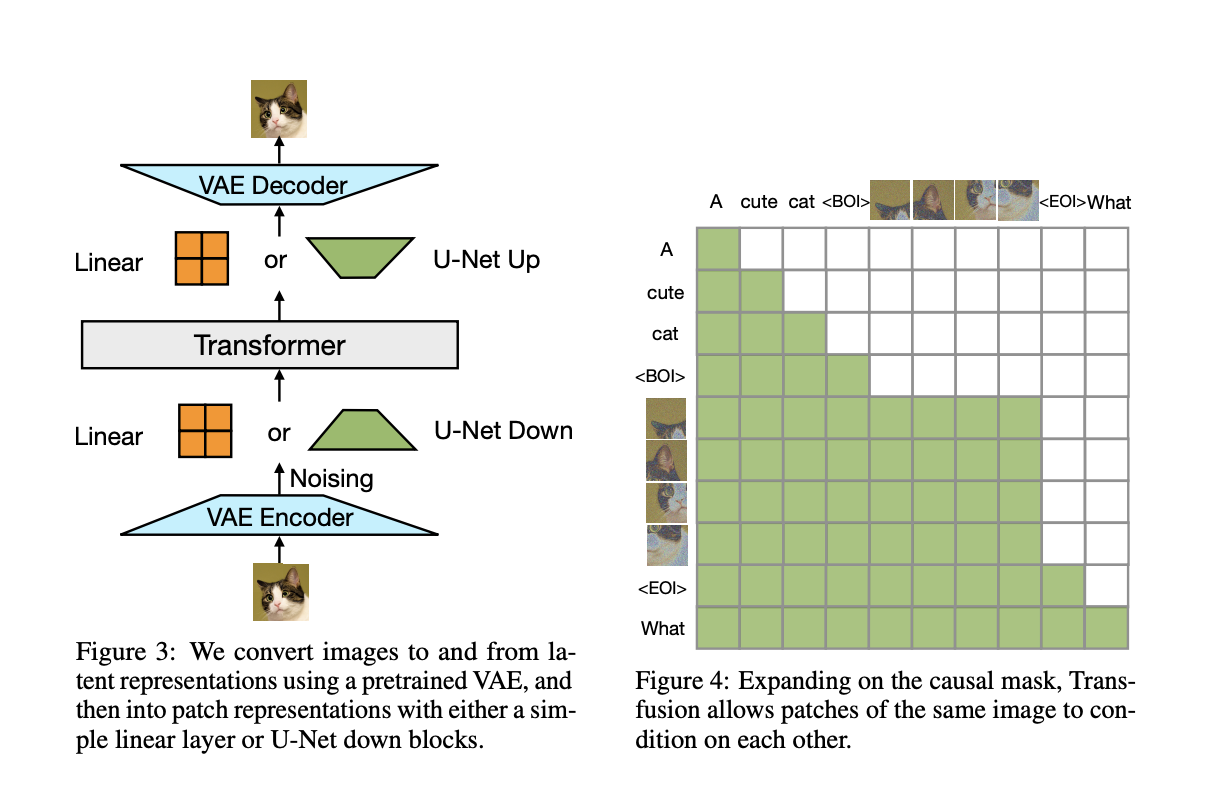
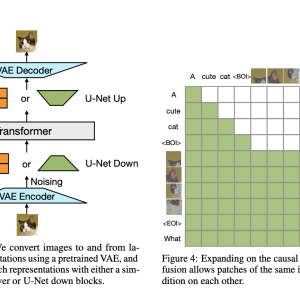
Transfusion is trained on a balanced mixture of text and image data, with each modality being processed through its specific objective: next-token prediction for text and diffusion for images. The model’s architecture consists of a transformer with modality-specific components, where text is tokenized into discrete sequences and images are encoded as latent patches using a variational autoencoder (VAE). The model employs causal attention for text tokens and bidirectional attention for image patches, ensuring that both modalities are processed effectively. Training is conducted on a large-scale dataset consisting of 2 trillion tokens, including 1 trillion text tokens and 692 million images, each represented by a sequence of patch vectors. The use of U-Net down and up blocks for image encoding and decoding further enhances the model’s efficiency, particularly when compressing images into patches.
Transfusion demonstrates superior performance across several benchmarks, particularly in tasks involving text-to-image and image-to-text generation. This innovative approach outperforms existing methods by a significant margin in key metrics such as Frechet Inception Distance (FID) and CLIP scores. For example, in a controlled comparison, Transfusion achieves a 2× lower FID score than the Chameleon models, demonstrating better scaling and reduced computational costs. A critical evaluation table highlights these results, showcasing the effectiveness of Transfusion across various benchmarks. Notably, the 7B parameter model achieves a FID score of 16.8 on the MS-COCO benchmark, outperforming other approaches that require more computational resources to achieve similar results .
In conclusion, Transfusion represents a novel approach to multi-modal learning, effectively combining language modeling and diffusion processes within a single architecture. By addressing the inefficiencies and limitations of existing methods, Transfusion offers a more integrated and efficient solution for processing and generating both text and images. This proposed method has the potential to significantly impact various AI applications, particularly those involving complex multi-modal tasks, by enabling a more seamless and effective integration of diverse data modalities.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 49k+ ML SubReddit
Find Upcoming AI Webinars here
The post Meta presents Transfusion: A Recipe for Training a Multi-Modal Model Over Discrete and Continuous Data appeared first on MarkTechPost.