Large Language Models (LLMs) and their multi-modal counterparts (MLLMs) have made significant strides in advancing artificial general intelligence (AGI) across various domains. However, these models face a significant challenge in the realm of visual mathematical problem-solving. While MLLMs have demonstrated impressive capabilities in diverse tasks, they struggle to fully utilize their potential when confronted with mathematical problems presented in visual contexts. This limitation is particularly evident in scenarios where models must interpret geometric figures, understand spatial relationships, and integrate complex mathematical concepts with visual information.
The difficulty lies in the unique demands of visual mathematical problem-solving, which requires a seamless integration of analytical reasoning from textual questions with the contextual information provided by visual diagrams. Unlike text-only mathematical problems, where LLMs have shown considerable progress due to abundant training data and their inherent language proficiency, visual mathematics introduces an additional layer of complexity. Models must not only comprehend the mathematical concepts but also accurately interpret visual elements such as geometric shapes, angles, measurements, and spatial relationships represented in diagrams.
Visual instruction tuning for MLLMs has seen significant advancements through approaches like LLaMA-Adapter, LLaVA, Flamingo, SPHINX, and InternVL, each introducing efficient techniques for vision-language integration. Simultaneously, text-based mathematical problem-solving has progressed with projects like MAmmoTH, MetaMATH, and MathCoder. However, in the multi-modal mathematical domain, efforts remain limited. Datasets such as Geometry3K and UniMath have emerged, but their scope and scale are insufficient. G-LLaVA shows promise in graphical geometry but struggles in other mathematical areas, highlighting the need for more robust, comprehensive approaches to visual mathematical problem-solving.
Researchers from CUHK, Peking University, Shanghai AI Laboratory, and Oracle introduce MAVIS (MAthematical VISual instruction tuning) which presents a robust approach addressing the limitations of MLLMs in visual mathematical problem-solving. This framework tackles three critical issues: unsatisfactory math diagram embeddings by vision encoders, diagram-language misalignment between vision encoders and LLMs, and inaccurate mathematical reasoning with visual elements. MAVIS introduces two extensive datasets, MAVIS-Caption and MAVIS-Instruct, covering various mathematical domains. It employs a progressive three-stage training pipeline to enhance diagram visual encoding and reasoning capabilities. The result is MAVIS-7B, a specialized MLLM optimized for visual mathematical tasks, which demonstrates superior performance on evaluation benchmarks compared to existing open-source MLLMs, highlighting the effectiveness of this targeted approach in advancing visual mathematical problem-solving capabilities.
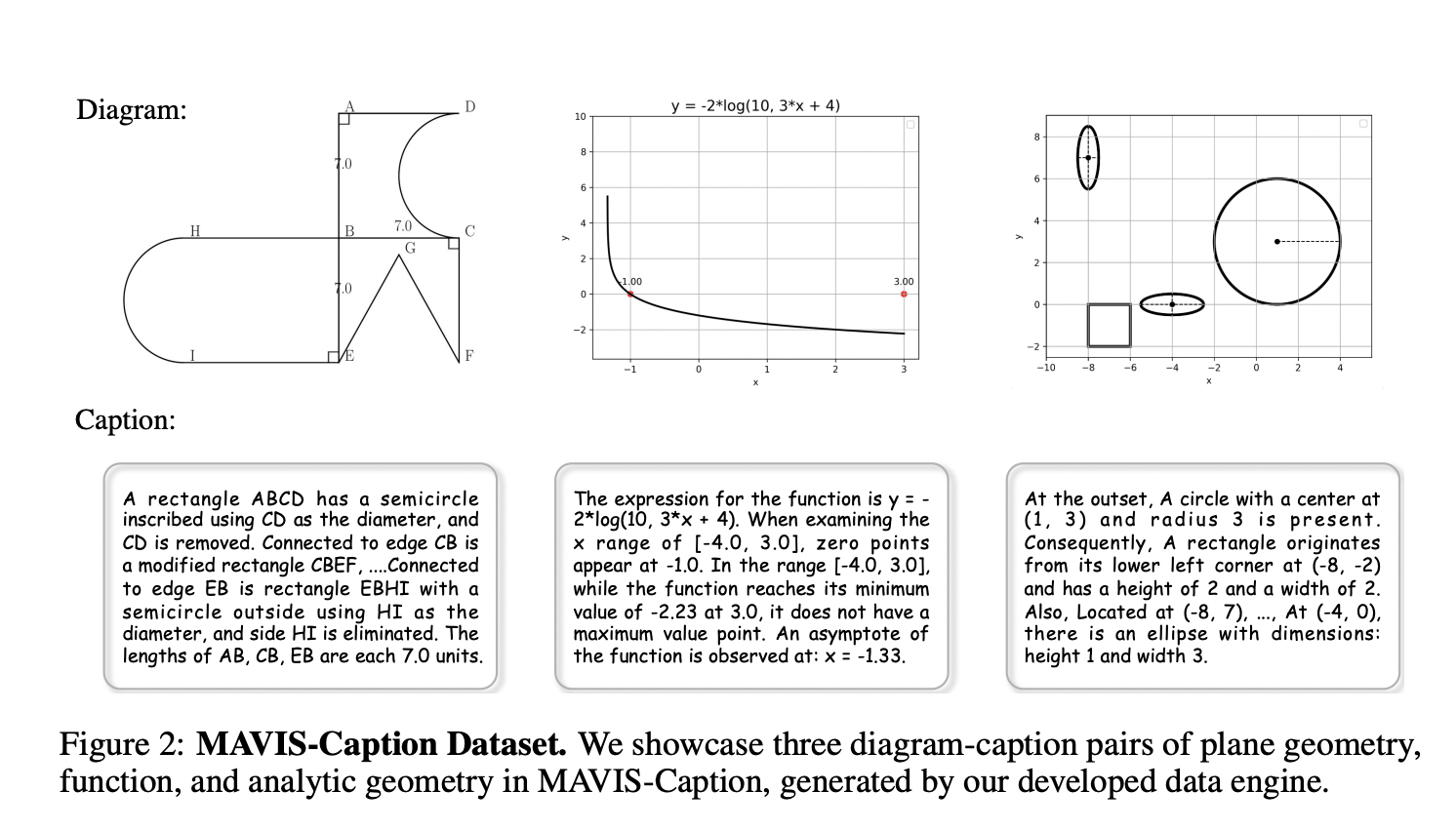
MAVIS introduces an innovative data engine to generate high-quality mathematical diagrams efficiently, addressing the scarcity of visual mathematics datasets. The engine covers three main diagram types: plane geometry, analytic geometry, and function. For plane geometry, it employs multi-hop data curation principles, iteratively combining basic shapes to create diverse configurations. Analytic geometry diagrams are constructed on a Cartesian coordinate system, incorporating various geometric elements without overlap. Function diagrams focus on seven fundamental types, using parameterized equations to generate diverse graphs. All diagrams are rendered using Matplotlib, with additional features like vertex labeling and key point plotting to enhance mathematical understanding and reasoning capabilities.
MAVIS-Caption, a crucial component of the MAVIS framework, is a large-scale dataset comprising 588,000 diagram-caption pairs. It covers three mathematical domains: plane geometry (299K pairs), analytic geometry (77K pairs), and function (212K pairs). The dataset’s captions are detailed, with an average length of 61.48 words and a vocabulary size of 149. Caption generation strategies vary by diagram type, utilizing GPT-4-created templates and specific rules for each domain. Plane geometry captions are built iteratively, analytic geometry captions use coordinate-based descriptions, and function captions detail various properties of the graphed functions. All captions are refined by ChatGPT for natural language expression, ensuring high-quality, diverse, and mathematically accurate descriptions of visual mathematical content.
MAVIS-Instruct is a comprehensive dataset of 834,000 visual math problems designed to enhance MLLMs’ visual mathematical reasoning capabilities. It covers plane geometry and function problems, each accompanied by a Chain-of-Thought (CoT) rationale averaging 150 words. The dataset’s questions are streamlined to minimize textual redundancy, encouraging MLLMs to extract critical information from visual inputs. MAVIS-Instruct is compiled from four sources: manually collected problems augmented by GPT-4 (84K), existing datasets expanded by GPT-4 (80K), data engine captions annotated by GPT-4 (51K), and problems directly generated by the data engine. This diverse approach ensures broad coverage of mathematical concepts and problem types, while maintaining high-quality, detailed solutions and rationales for each problem.
MAVIS-7B demonstrates superior performance across multiple mathematical benchmarks, showcasing its effectiveness in visual mathematical problem-solving. On the comprehensive MathVerse benchmark, MAVIS-7B achieves the highest overall accuracy among open-source models, surpassing larger models and specialized mathematical MLLMs. It outperforms InternLM-XComposer2 (7B) by 11.0% and ShareGPT4V (13B) by 10.1%. In specific domains, MAVIS-7B excels on GeoQA for plane geometry, achieving 66.7% accuracy, and on FunctionQA, reaching 40.3% accuracy, outperforming both traditional methods and other MLLMs. Qualitative analysis reveals MAVIS-7B’s superior understanding of geometric elements, function curves, and coordinate axes, leading to higher-quality Chain-of-Thought reasoning compared to GPT-4V.
This study introduces MAVIS, an efficient approach to mathematical visual instruction tuning for MLLMs. The framework comprises two key components: high-quality datasets (MAVIS-Caption and MAVIS-Instruct) generated by a sophisticated data engine, and a three-stage training pipeline. This process sequentially enhances the math-specific vision encoder, improves diagram-language alignment, and develops mathematical reasoning capabilities. The resulting specialist model, MAVIS-7B, demonstrates exceptional performance across various mathematical visual benchmarks. MAVIS’s innovative approach sets a new standard in visual mathematical problem-solving, paving the way for future advancements in this critical area of artificial intelligence and education technology.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 46k+ ML SubReddit
The post From Diagrams to Solutions: MAVIS’s Three-Stage Framework for Mathematical AI appeared first on MarkTechPost.