MultiOn AI has recently announced the release of its latest innovation, the Retrieve API, an autonomous web information retrieval API designed to revolutionize how developers and businesses extract and utilize web data. This groundbreaking API complements the previously launched Agent API, offering a comprehensive solution for autonomous web browsing and data extraction.
The development of the Retrieve API stemmed from feedback received after the launch of the Agent API. Developers expressed the need for a natural language-based web understanding and data extraction tool to enhance the agent’s capabilities in autonomous web browsing. This necessity became increasingly evident for use cases requiring web research and structured data extraction, leading MultiOn to create the Retrieve API.
The Retrieve API is designed to actively crawl and parse web pages in real-time, fetching structured information with unparalleled accuracy and speed. Unlike traditional search engines and APIs, the Retrieve API processes web pages dynamically, allowing it to extract and understand information with high precision. This functionality enables developers to create fully autonomous web agents capable of navigating pages and scraping information efficiently with minimal coding effort.
Several use cases illustrate the practical applications of the Retrieve API. For instance, a startup developing an AI-powered personal shopping assistant can utilize the Retrieve API to scan e-commerce sites, compare prices, and gather product reviews, providing users personalized recommendations. Similarly, a company creating an automated lead generation tool might use the API to crawl company websites, social media profiles, and business directories, compiling detailed prospect lists for sales teams. Additionally, a content creation startup can leverage the API to gather trending topics, relevant statistics, and reputable sources, aiding in generating data-driven articles and reports.
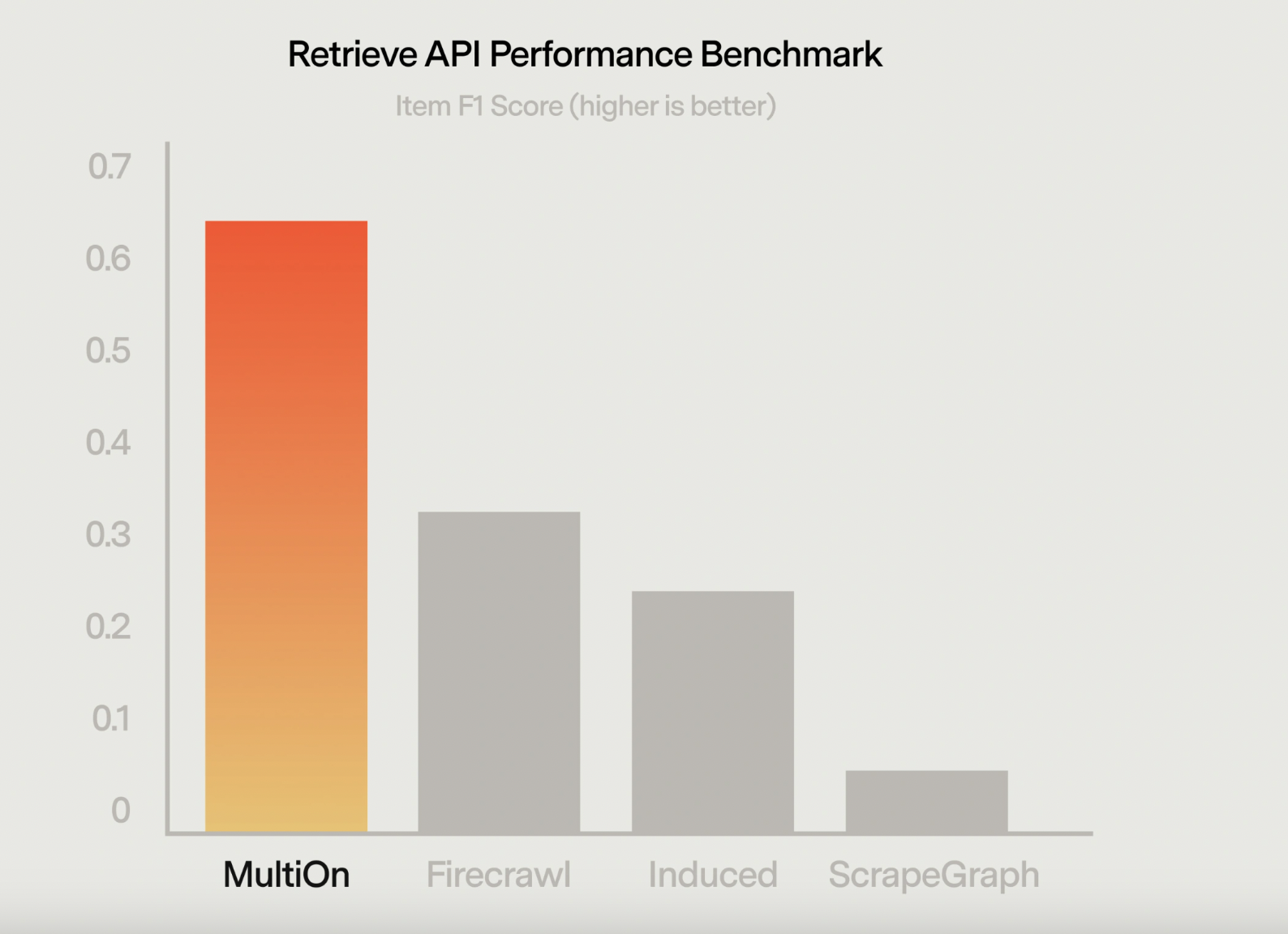
MultiOn benchmarked the Retrieve API against existing LLM-based data extraction APIs such as Firecrawl and Induced.AI and popular open-source libraries like ScrapeGraph to validate its performance. The benchmarks involved testing 50 static websites across various categories, including e-commerce, social media, news, food, travel, finance, technology, and information. The evaluation metrics focused on the retrieved data’s accuracy and completeness, with the Retrieve API outperforming competitors in precision and recall.
The API’s implementation is straightforward, allowing developers to integrate its capabilities into their applications quickly. MultiOn provides detailed code examples and a comprehensive cookbook to help users get started. The process involves installing the MultiOn package, initializing the client with an API key, and using simple commands to scrape and retrieve data from web pages. The Retrieve API supports advanced features such as JavaScript rendering and parallel scraping, making it a versatile tool for various web data extraction needs.
In conclusion, MultiOn AI’s introduction of the Retrieve API addresses the growing demand for efficient and accurate web data extraction. The API empowers developers to build sophisticated web agents and applications that seamlessly navigate and scrape information. This innovative API stands out for its real-time processing capabilities, ease of use, and superior performance, positioning MultiOn as a leader in autonomous web browsing and data extraction.
The post Retrieve API by MultiOn AI Transforms Autonomous Web Information Retrieval with Real-Time Processing and Unparalleled Accuracy: Empowering Developers to Build Advanced Web Agents and Applications appeared first on MarkTechPost.