
Synthetic data generation has become crucial in training large language models (LLMs). This field focuses on creating artificial data sets that mimic real-world data, allowing researchers to train and evaluate machine learning models effectively without compromising privacy or requiring extensive data collection efforts. The methodology behind synthetic data creation aims to provide diverse and scalable data sets to enhance the robustness and performance of LLMs in various applications.
The primary challenge in synthetic data generation lies in creating diverse data at scale. Traditional methods often struggle to maintain both diversity and scalability. Instance-driven approaches, which generate new data based on a seed corpus, are limited by the diversity of the original data set. Key-point-driven methods attempt to diversify synthetic data by leveraging a curated list of key points, but this process is difficult to scale across different domains due to the exhaustive curation required. As a result, these methods often fail to produce data sets that can cover a broad range of scenarios and use cases.
Current methods for synthetic data generation typically involve instance-driven and key-point-driven approaches. Instance-driven methods use a seed corpus to create new instances, but their diversity is constrained by the initial corpus. Key-point-driven methods rely on a comprehensive list of key points, which is challenging to curate exhaustively and limits the scope to specific domains. These methods, while useful, often fall short in producing sufficiently diverse and scalable synthetic data sets required for advanced LLM training and application.
Researchers from Tencent AI Lab introduced Persona Hub, a novel persona-driven data synthesis methodology. This approach leverages a collection of one billion diverse personas, automatically curated from web data, to generate synthetic data. Persona Hub allows LLMs to create data from various perspectives, enhancing diversity and scalability. By associating synthetic data prompts with specific personas, this methodology can steer LLMs towards creating distinct and varied data sets, overcoming the limitations of previous methods.
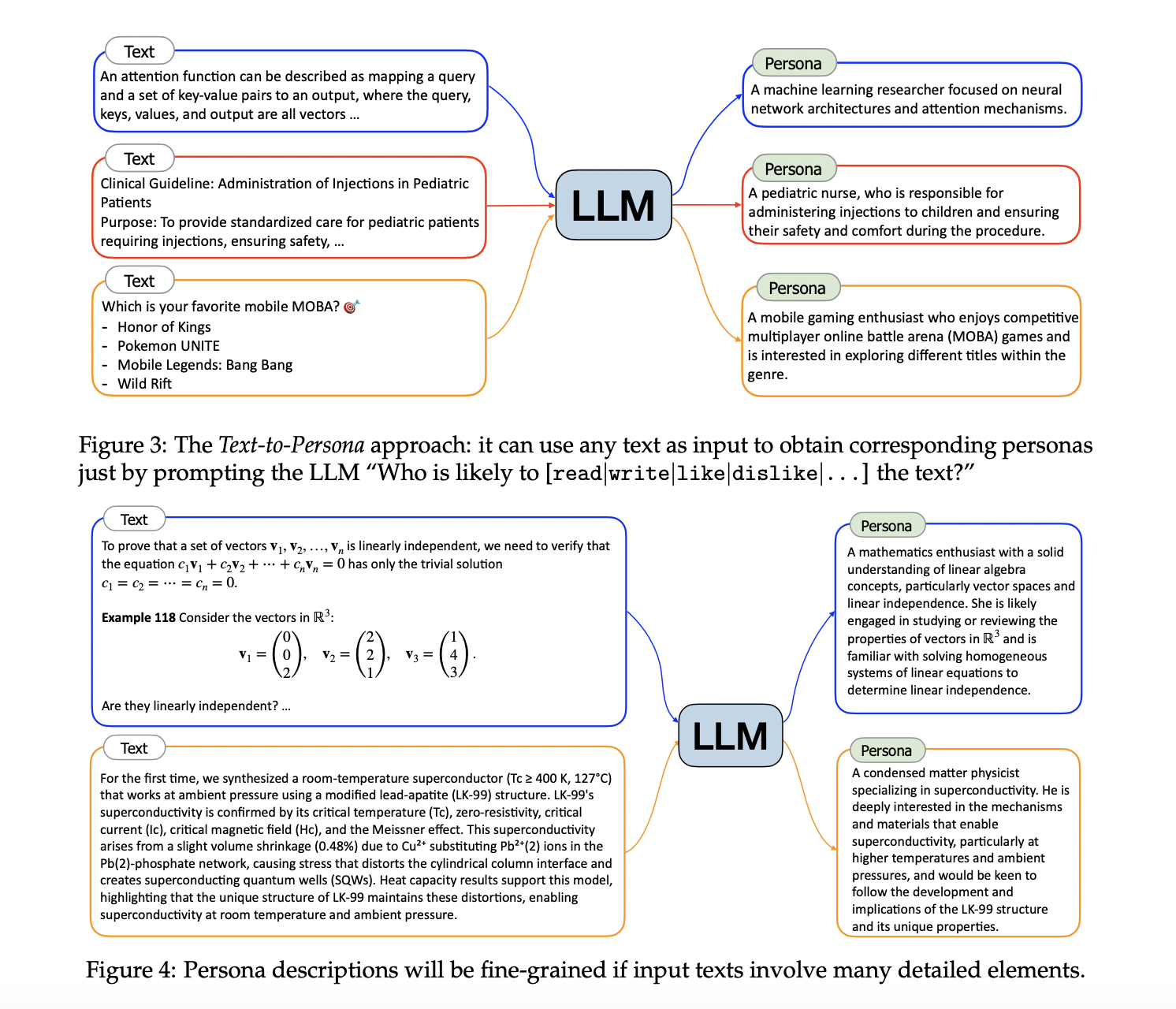
Persona Hub comprises one billion personas representing 13% of the world’s population, each associated with unique knowledge, experiences, interests, and professions. This collection enables the generation of synthetic data across diverse scenarios by prompting LLMs with specific personas. The personas act as distributed carriers of world knowledge, guiding the LLMs to produce diverse and contextually rich synthetic data. The researchers developed scalable approaches to derive these personas from massive web data, utilizing both text-to-persona and persona-to-persona methods. The text-to-persona approach infers personas from specific texts, while the persona-to-persona approach expands persona diversity through interpersonal relationships.
The persona-driven approach produced impressive quantitative results. Researchers created 50,000 math problems, 50,000 logical reasoning problems, 50,000 instructions, 10,000 knowledge-rich texts, 10,000 game NPCs, and 5,000 tools. In evaluations, a model fine-tuned with 1.07 million synthetic math problems achieved 79.4% accuracy on an in-distribution test set of 11,600 instances, outperforming all tested open-source LLMs. On the MATH benchmark, the model reached 64.9% accuracy, matching the performance of gpt-4-turbo-preview, demonstrating significant improvements in LLM capabilities through persona-driven data synthesis.
Researchers highlighted the substantial improvements in LLM performance and the profound impact of persona-driven data synthesis on LLM training and development. By leveraging the 1 billion personas in Persona Hub, the researchers could create diverse synthetic data sets that significantly enhance the LLM’s capabilities. This methodology proved effective in various data synthesis scenarios, showcasing its potential to become a standard practice in synthetic data generation.
The researchers’ persona-driven methodology for synthetic data generation addresses the limitations of traditional methods by introducing a scalable and diverse approach. Persona Hub’s extensive collection of personas facilitates the creation of rich, varied synthetic data, advancing the field of LLM training and applications. This innovative method promises to enhance the capabilities of LLMs and broaden their real-world applicability. By providing a robust solution to the challenges of synthetic data generation, this research has the potential to drive significant advancements in artificial intelligence and machine learning.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 45k+ ML SubReddit
The post This AI Paper by Tencent AI Lab Researchers Introduces Persona-Hub: A Collection of One Billion Diverse Personas for Scaling Synthetic Data appeared first on MarkTechPost.