Research on Multimodal large language models (MLLMs) focuses on integrating visual and textual data to enhance artificial intelligence’s reasoning capabilities. By combining these modalities, MLLMs can interpret complex information from diverse sources such as images and text, enabling them to perform tasks like visual question answering and mathematical problem-solving with greater accuracy and insight. This interdisciplinary approach leverages the strengths of both visual and linguistic data, aiming to create more robust AI systems capable of understanding and interacting with the world like humans.
A significant challenge in developing effective MLLMs is their inability to solve complex mathematical problems involving visual content. Despite their proficiency in textual mathematical problem-solving, these models often need to improve when interpreting and reasoning through visual information. This gap highlights the need for improved datasets and methodologies that better integrate multimodal data. Researchers strive to create models that can understand text and derive meaningful insights from images, diagrams, and other visual aids critical in fields like education, science, and technology.
Existing methods to enhance MLLMs’ mathematical reasoning include prompt and fine-tuning approaches. Prompt methods leverage the models’ latent abilities through carefully crafted prompts, while fine-tuning methods adjust the model parameters using reasoning data from real-world or synthetic sources. However, current open-source image instruction datasets are limited in scope, containing few question-answer pairs per image, which restricts the models’ ability to exploit visual information fully. The limitations of these datasets impede the development of MLLMs, necessitating the creation of more comprehensive and diverse datasets to train these models effectively.
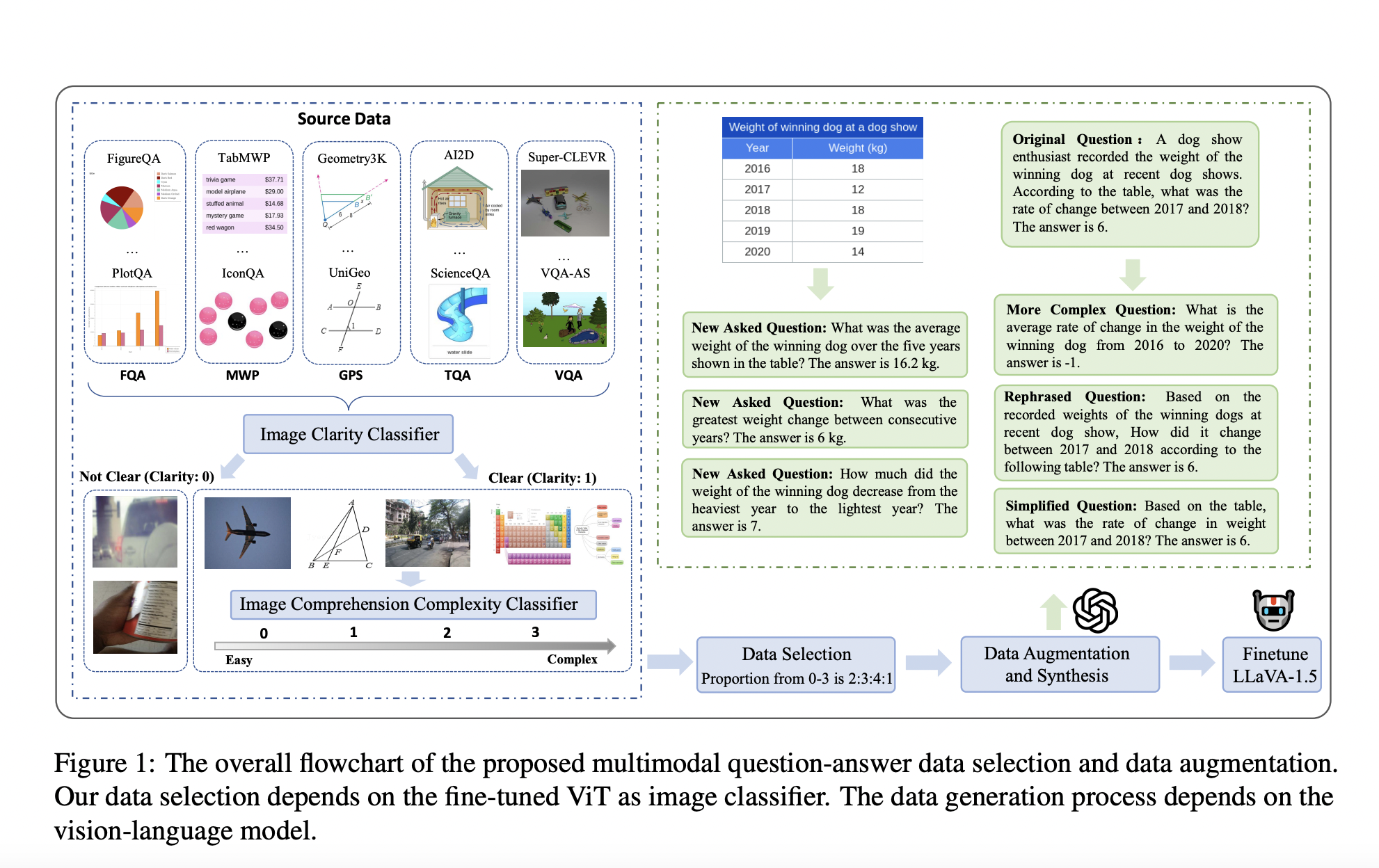
Researchers from institutions including the University of Electronic Science and Technology of China, Singapore University of Technology and Design, Tongji University, and the National University of Singapore introduced Math-LLaVA, a model fine-tuned with a novel dataset called MathV360K. This dataset includes 40K high-quality images and 320K synthesized question-answer pairs designed to improve the breadth and depth of multimodal mathematical reasoning capabilities. Introducing Math-LLaVA represents a significant step forward in the field, addressing the gaps left by previous datasets and methods.
The MathV360K dataset was constructed by selecting 40K high-quality images from 24 pre-existing datasets, focusing on subjects like algebra, geometry, and visual question answering. Researchers synthesized 320K new question-answer pairs based on these images to enhance the diversity and complexity of the dataset. This comprehensive dataset was then used to fine-tune the LLaVA-1.5 model, resulting in the development of Math-LLaVA. The selection process for these images involved rigorous criteria to ensure clarity and complexity, aiming to cover a wide range of mathematical concepts and question types. The synthesis of additional question-answer pairs involved generating diverse questions that probe different aspects of the images and require multiple reasoning steps, further enhancing the dataset’s robustness.
Math-LLaVA demonstrated significant improvements, achieving a 19-point increase on the MathVista minutest split compared to the original LLaVA-1.5 model. Furthermore, it showed enhanced generalizability and performed well on the MMMU benchmark. Specifically, Math-LLaVA achieved a 57.7% accuracy on the GPS subset, outperforming G-LLaVA-13B, trained on 170K high-quality geometric image-caption and question-answer pairs. These results highlight the effectiveness of the diverse and comprehensive MathV360K dataset in enhancing the multimodal mathematical reasoning capabilities of MLLMs. The model’s performance on different benchmarks underscores its ability to generalize across various mathematical reasoning tasks, making it a valuable tool for a wide range of applications.
To conclude, the research underscores the critical need for high-quality, diverse multimodal datasets to improve mathematical reasoning in MLLMs. By developing and fine-tuning Math-LLaVA with MathV360K, researchers have significantly enhanced the model’s performance and generalizability, showcasing the importance of dataset diversity and synthesis in advancing AI capabilities. The MathV360K dataset and the Math-LLaVA model represent a substantial advancement in the field, providing a robust framework for future research and development. This work not only underscores the potential of MLLMs to transform various domains by integrating visual and textual data but also inspires hope for the future of AI, paving the way for more sophisticated and capable AI systems.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 45k+ ML SubReddit
The post Math-LLaVA: A LLaVA-1.5-based AI Model Fine-Tuned with MathV360K Dataset appeared first on MarkTechPost.