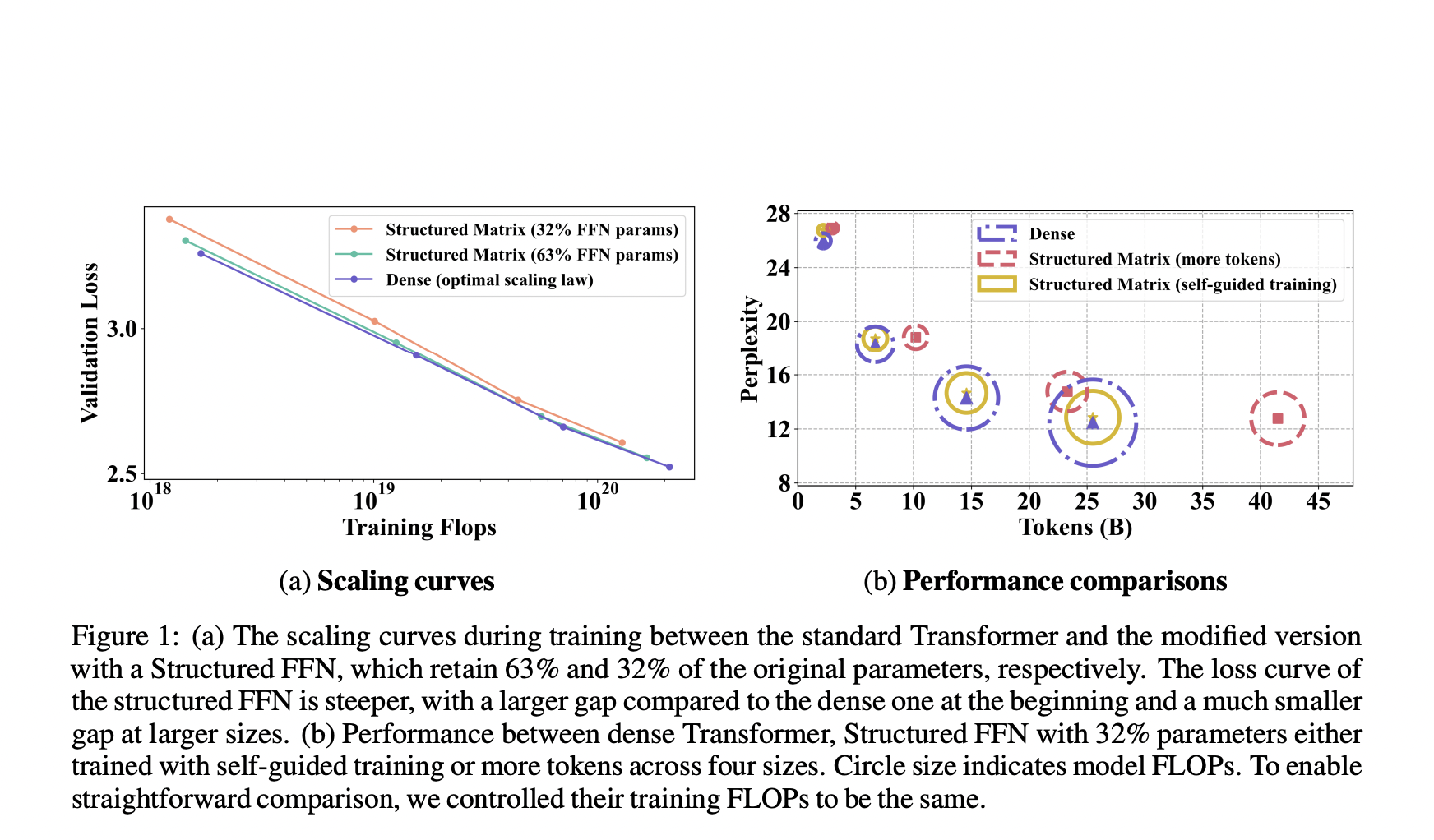
Optimizing the efficiency of Feedforward Neural Networks (FFNs) within Transformer architectures is a significant challenge in AI. Large language models (LLMs) are highly resource-intensive, requiring substantial computational power and energy, which restricts their applicability and raises environmental concerns. Efficiently addressing this challenge is crucial for promoting sustainable AI practices and making advanced AI technologies more accessible by reducing operational costs.
Current methods to enhance FFN efficiency typically involve low-rank approximations and structured matrices. Approaches such as LowRank and BlockDense decompositions have been proposed to reduce parameters and FLOPs. However, these methods often face limitations in practical scenarios. For instance, low-rank approximations can suffer from poor optimization dynamics due to increased symmetries leading to saddle points, and structured matrices can result in suboptimal training dynamics and reduced efficiency in online decoding due to poor parallelism on GPUs. These limitations make the existing methods less suitable for real-time applications and large-scale deployments.
A team of researchers from Google DeepMind and EPFL propose a hybrid structure combining low-rank and block-diagonal matrices with a technique termed ‘self-guided training.’ This new method aims to mitigate the optimization issues by introducing a dense matrix during the initial training phase, which is gradually phased out, allowing the structured matrices to take over. This approach ensures better training stability and faster convergence. The hybrid method not only addresses computational efficiency but also ensures that optimization dynamics are smooth, reducing the occurrence of loss spikes and instability and thus representing a significant advancement over existing methods.
The research employs structured linear parameterization, where the FFN layers are approximated using combinations of low-rank and block-diagonal matrices. The key innovation is the ‘self-guided training’ method, where the dense matrix aids in the early training stages, progressively transitioning to efficient structured forms. The training utilizes the RefinedWeb dataset, which includes 600B tokens, and employs advanced GPU optimizations like mixed precision training, Flash Attention, and rotary embeddings. Hyperparameters such as learning rates and dropout rates are meticulously tuned to ensure optimal performance. The proposed models are tested at scales ranging from 110M to 1.3B parameters, demonstrating scalability and robustness.
The innovative method significantly enhances training and inference efficiency. The structured FFN models achieved a 1.35× speed-up in training and a 2.5× faster FFN at inference with only a slight increase in perplexity. The ‘self-guided training’ technique resulted in a 0.4 reduction in perplexity on a 1.3B parameter model with consistent training FLOPs. The approach demonstrated improved performance metrics, including lower perplexity and higher throughput, validating its efficacy and superiority over traditional FFNs.
In conclusion, this research presents a significant contribution to optimizing large language models by introducing a hybrid structured FFN approach combined with self-guided training. This innovation addresses critical limitations of existing methods, resulting in improved training efficiency and model performance. The findings suggest that this advancement could propel AI research forward by making large-scale models more computationally efficient and accessible, thereby promoting sustainable and democratized AI development.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 45k+ ML SubReddit
The post Cutting Costs, Not Performance: Structured FeedForward Networks FFNs in Transformer-Based LLMs appeared first on MarkTechPost.