
Large language models (LLMs) have made significant strides in natural language understanding and generation. However, they face a critical challenge when handling long contexts due to limitations in context window size and memory usage. This issue hinders their ability to process and comprehend extensive text inputs effectively. As the demand for LLMs to handle increasingly complex and lengthy tasks grows, addressing this limitation has become a pressing concern for researchers and developers in the field of natural language processing.
Researchers have explored various approaches to overcome the challenges of long-context processing in LLMs. Model-level methods, such as positional interpolation and transformer variants with modified attention mechanisms, have shown promise but come with significant drawbacks. These include increased training costs, neglect of detailed information, and loss of earlier context. On the other hand, retrieval-based methods like Retrieval Augmented Generation (RAG) have been developed to utilize external databases for information extraction. However, RAG struggles with complex questions due to limitations in decision-making mechanisms. Agent-based approaches have emerged as a potential solution, utilizing LLMs’ planning and reflection abilities to tackle complex problems and retrieve unstructured information. Despite these advancements, existing methods still face difficulties in handling multi-hop questions and fully exploiting the capabilities of LLMs as agents.
Researchers from Alibaba Group, The Chinese University of Hong Kong, Shanghai AI Laboratory, and the University of Manchester introduced GraphReader, a robust graph-based agent system to tackle the challenges of long-context processing in LLMs. This innovative approach segments lengthy texts into discrete chunks, extracting and compressing essential information into key elements and atomic facts. These components are then used to construct a graph structure that effectively captures long-range dependencies and multi-hop relationships within the text. The agent autonomously explores this graph using predefined functions and a step-by-step rational plan, progressively accessing information from coarse elements to detailed original text chunks. This process involves taking notes and reflecting until sufficient information is gathered to generate an answer. GraphReader’s design aims to establish a scalable long-context capability based on a 4k context window, potentially rivaling or surpassing the performance of GPT-4 with a 128k context window across various context lengths.
GraphReader is built on a graph structure, where each node contains a key element and a set of atomic facts. This structure enables the capture of global information from long input documents within a limited context window. The system operates in three main phases: graph construction, graph exploration, and answer reasoning. During graph construction, the document is split into chunks, summarized into atomic facts, and key elements are extracted. Nodes are created from these components and linked based on shared key elements. In the graph exploration phase, the agent initializes by defining a rational plan and selecting initial nodes. It then explores the graph by examining atomic facts, reading relevant chunks, and investigating neighbouring nodes. The agent maintains a notebook to record supporting facts throughout the exploration. Finally, in the answer reasoning phase, the system compiles notes from multiple agents, analyzes them using Chain-of-Thought reasoning, and generates a final answer to the given question.
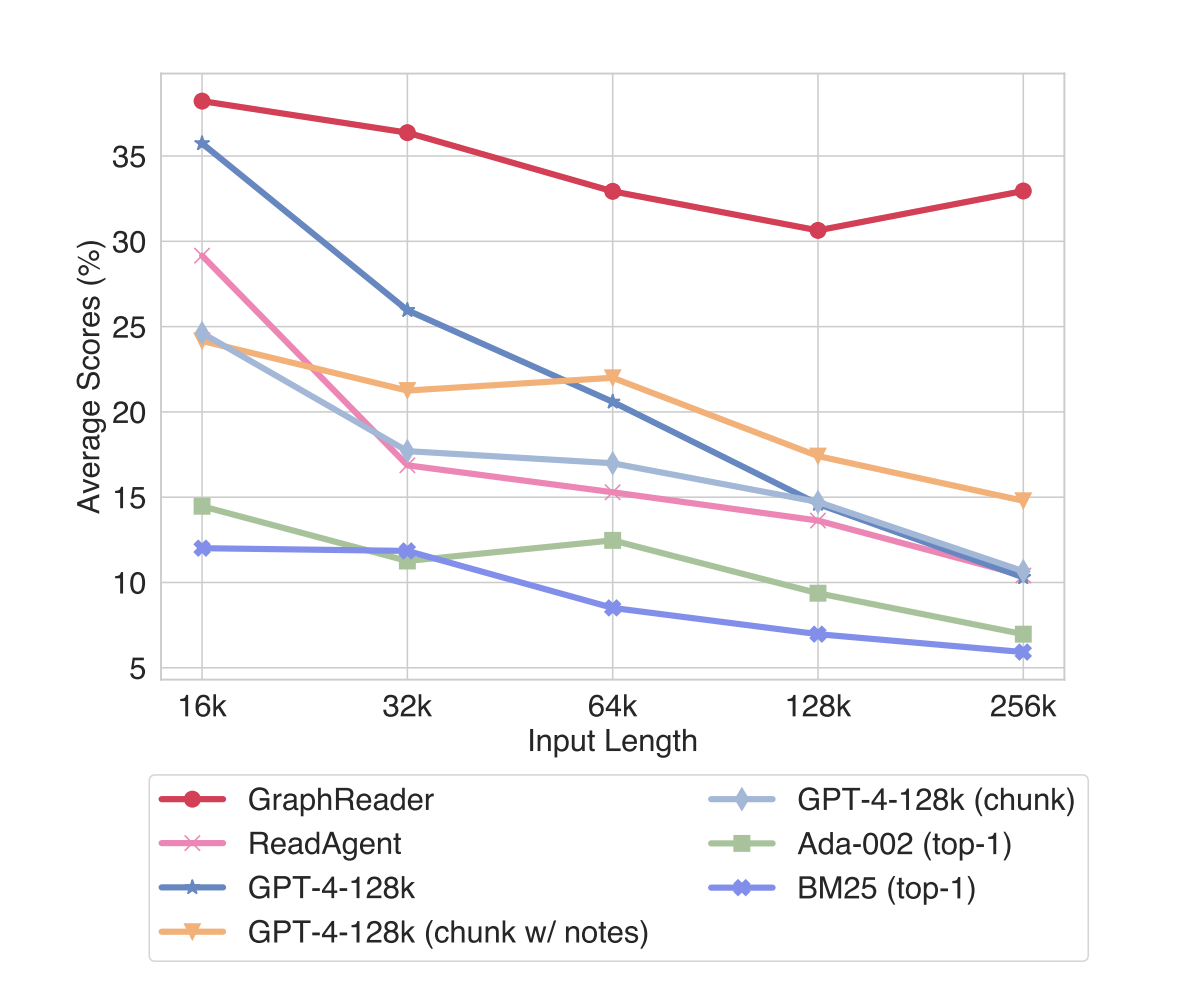
The evaluation of GraphReader and other methods on multiple long-context benchmarks reveals several key findings. GraphReader consistently outperforms other approaches across various tasks and context lengths. On multi-hop QA tasks, GraphReader achieves superior performance compared to RAG methods, long-context LLMs, and other agent-based approaches. For instance, on the HotpotQA dataset, GraphReader achieves 55.0% EM and 70.0% F1 scores, surpassing GPT-4-128k and ReadAgent. GraphReader’s effectiveness extends to extremely long contexts, as demonstrated in the LV-Eval benchmark. It maintains robust performance across text lengths from 16k to 256k tokens, showing a relative performance gain of 75.00% over GPT-4-128k at 128k context length. This superior performance is attributed to GraphReader’s graph-based exploration strategy, which efficiently captures relationships between key information and facilitates effective multi-hop reasoning in long contexts.
GraphReader represents a significant advancement in addressing long-context challenges in large language models. By organizing extensive texts into graph structures and employing an autonomous agent for exploration, it effectively captures long-range dependencies within a compact 4k context window. Its superior performance, outperforming GPT-4 with a 128k input length across various question-answering tasks, demonstrates its efficacy in handling complex reasoning scenarios. This breakthrough opens new possibilities for applying LLMs to tasks involving lengthy documents and intricate multi-step reasoning, potentially revolutionizing fields like document analysis and research assistance. GraphReader sets a new benchmark for long-context processing, paving the way for more advanced language models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 45k+ ML SubReddit
The post GraphReader: A Graph-based AI Agent System Designed to Handle Long Texts by Structuring them into a Graph and Employing an Agent to Explore this Graph Autonomously appeared first on MarkTechPost.